

RBF、 K-NN 与Decision tree
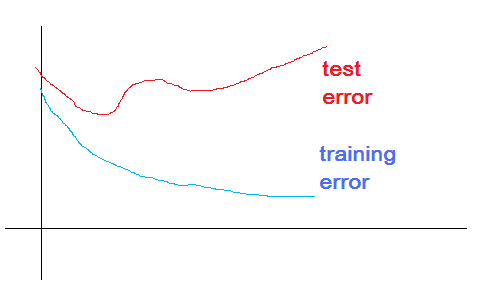
要做一个classifier,的确不易。面对需要训练的classifier,是否training error越少越好呢?显然不是,因为虽然training error降低了,但test error不见得就会降低,实际表现为一个拐点。如下图:
为了平衡error的权重,我们引入了额外的函数lambda*θ,训练效果由error和 lambda*θ共同评价。下面讨论一下lambda的取值:
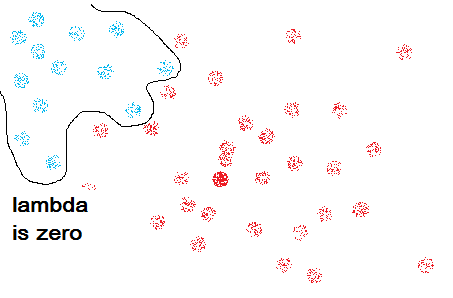
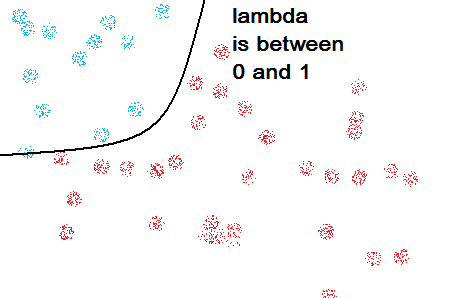 (存疑)
(存疑)

通过加入额外的评价函数,我们对模型的训练应该是比较到位的。但是用一个函数对所有样本分类,在样本比较复杂的时候就会有点吃力。
因此,我们采取多个函数综合评估的方式进行,即RBF(radial base function)
RBF采取多个正态分布函数进行评估,各函数的均值和方差不一样。
(待续)
K-NN 最近邻算法。俗话说物以类聚,人以群分。该算法就是采用离目标点最近的k个邻居,对目标点进行分类。但k值的选取非常关键,而且易受干扰。
decision tree:决策树,根据不同的决策选择不同的路径。

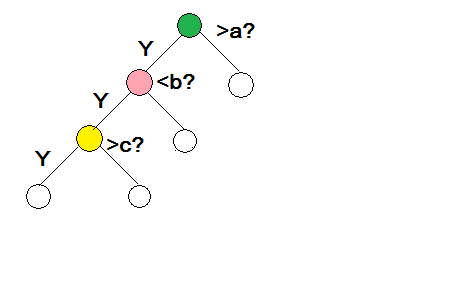
posted on 2010-03-24 13:13 lifehacker 阅读(753) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号