
数据结构与算法(9)--排序
Ch9 排序
0x01 基本概念
排序是对数据元素序列建立某种有序排列的过程,是把一个数据元素序列整理成按关键字递增(或递减)排列的过程。
关键字是要排序的数据元素集合中的一个域,排序是以关键字为基准进行的。
主关键字:数据元素值不同时该关键字的值也一定(数据库主键)不同,是能够惟一区分各个不同数据元素的关键字;不满足主关键字定义的关键字称为次关键字。
内部排序是把待排数据元素全部调入内存中进行的排序。
外部排序是因数量太大,把数据元素分批导入内存,排好序后再分批导出到磁盘和磁带外存介质上的排序方法。
比较排序算法优劣的标准:
(1)时间复杂度:它主要是分析记录关键字的比较次数和记录的 移动次数
(2)空间复杂度 :算法中使用的内存辅助空间的多少
(3)稳定性:若两个记录A和B的关键字值相等,但排序后A、B的 先后次序保持不变,则称这种排序算法是稳定的
0x02 插入排序
插入排序的基本思想是:每步将一个待排序的对象,按其关键码大小,插入到前面已经排好序的一组对象的适当位置上,直到对象全部插入为止。常见有直接插入排序和希尔排序两种。
直接插入排序
顺序地把待排序的数据元素按其关键字值的大小插入到已排序数据元素子集合的适当位置。
void InsertSort (DataType a[], int n)
//用直接插入法对a[0]--a[n-1]排序
{
int i, j;
DataType temp;
for(i=0; i<n-1; i++)
{
temp = a[i+1];
j = i;
while(j > -1 && temp.key <= a[j].key)
{
a[j+1] = a[j];
j--;
}
a[j+1] = temp;
}
}
(1)时间效率: 因为在最坏情况下,所有元素的比较次数总和为(0+1+…+n-1)→O(n2)。其他情况下也要考虑移动元素的次数。 故时间复杂度为O(n2)
(2)空间效率:仅占用1个缓冲单元——O(1)
(3)算法的稳定性:稳定

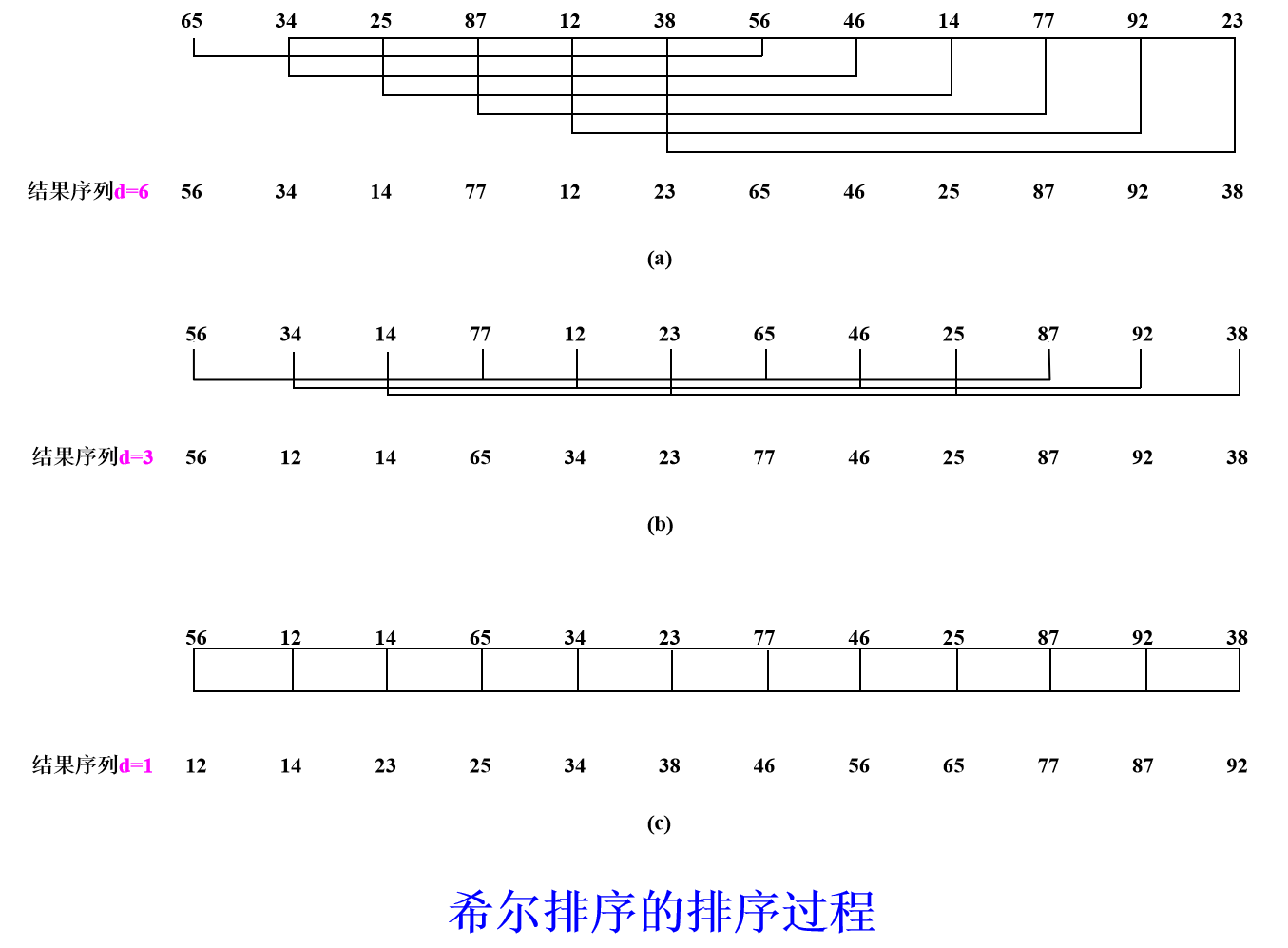
希尔排序(缩小增量排序)
(1)基本思想:把整个待排序的数据元素分成若干个小组,对同一小组内的数据元素用直接插入法排序;小组的个数逐次缩小,当完成了所有数据元素都在一个组内的排序后排序过程结束。
(2)技巧:小组的构成不是简单地“逐段分割”,而是将相隔某个增量dk的记录组成一个小组,让增量dk逐趟缩短(例如依次取5,3,1),直到dk=1为止。
(3)优点:让关键字值小的元素能很快前移,且序列若基本有序时,再用直接插入排序处理,时间效率会高很多。
算法如下:
void ShellSort (DataType a[], int n, int d[], int numOfD)
//用希尔排序法对元素a[0]--a[n-1]排序,d[0]--d[numOfD-1]为希尔增量值
{ int i, j, k, m, span;
DataType temp;
for(m = 0; m < numOfD; m++) //共numOfD次循环
{ span = d[m]; //取本次的增量值
for(k = 0; k < span; k++) //共span个小组
{
//组内是直接插入排序,区别是每次不是增1而是增span
for(i = k; i < n-span; i = i+span) { temp = a[i+span];
j = i;
while(j > -1 && temp.key <= a[j].key)
{ a[j+span] = a[j];
j = j-span;
}
a[j+span] = temp;
}
}
}
}
一个示例如下:
0x03 选择排序
基本思想:每次从待排序的数据元素集合中选取关键字最小(或最大)的数据元素放到数据元素集合的最前(或最后),数据元素集合不断缩小,当数据元素集合为空时选择排序结束。
常见选择排序算法:
直接选择排序、堆排序
直接选择排序
基本思想:从待排序的数据元素集合中选取关键字最小的数据元素并将它与原始数据元素集合中的第一个数据元素交换位置;然后从不包括第一个位置上数据元素的集合中选取关键字最小的数据元素并将它与原始数据元素集合中的第二个数据元素交换位置;如此重复,直到数据元素集合中只剩一个数据元素为止。
优点:实现简单
缺点:每次只能确定一个元素,表长为n时需要n-1次。
算法如下:
void SelectSort(DataType a[], int n)
{
int i, j, small;
DataType temp;
for(i = 0; i < n-1; i++)
{
small = i; //设第i个数据元素关键字最小
for(j = i+1; j < n; j++) //寻找关键字最小的数据元素
if(a[j].key < a[small].key) small=j;//记住最小元素的下标
if(small != i) //当最小元素的下标不为i时交换位置
{
temp = a[i];
a[i] = a[small];
a[small] = temp;
}
}
}

时间效率: O(n的2次方)——虽移动次数较少,但比较次数多。
空间效率:O(1)——没有附加单元(仅用到1个temp)
算法的稳定性:不稳定
堆排序
基本思想:把待排序的数据元素集合构成一个完全二叉树结构,则每次选择出一个最大(或最小)的数据元素只需比较完全二叉树的高度次,即log2n次,则排序算法的时间复杂度就是O(nlog2n)。
堆的定义:
一、堆的定义
堆分为最大堆和最小堆两种。定义如下:
设数组a中存放了n个数据元素,数组下标从0开始,如果当数组下标2i+1<n时有:a[i].key≥a[2i+1].key(a[i].key≤a[2i+1].key);如果当数组下标2i+2<n时有:a[i].key≥a[2i+2].key (a[i].key≤a[2i+2].key),则这样的数据结构称为最大堆(最小堆)。
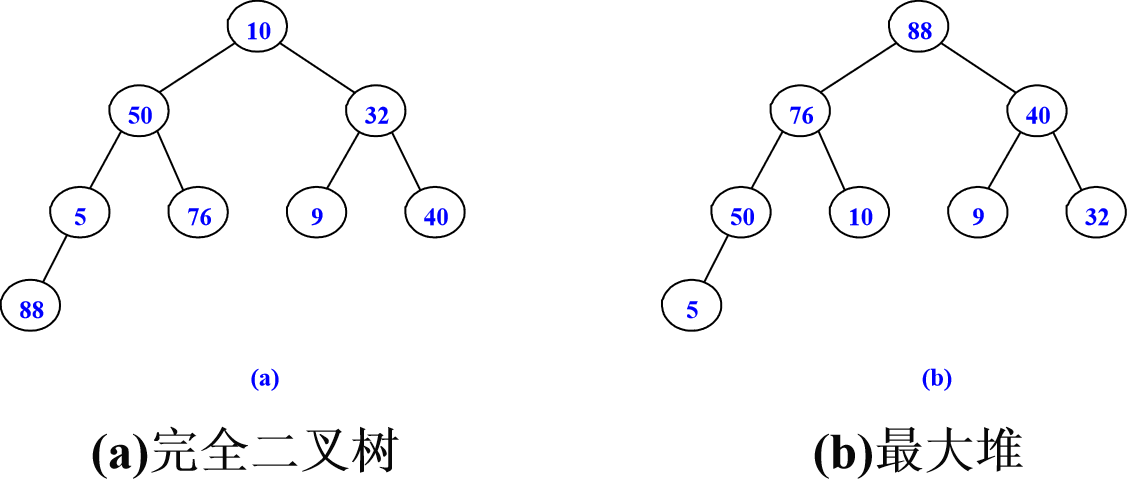
性质:
(1)最大堆的根结点是堆中值最大的数据元素,最小堆的根结点是堆中值最小的数据元素,我们称堆的根结点元素为堆顶元素。
(2)对于最大堆,从根结点到每个叶结点的路径上,数据元素组成的序列都是递减有序的;对于最小堆,从根结点到每个叶结点的路径上,数据元素组成的序列都是递增有序的。
创建堆
从最后一个叶子结点开始往前逐步调整,让每个双亲大于(或小于)子女,直到根结点为止。
初始化创建堆排序
void InitCreatHeap(DataType a[], int n)
{
int i;
for(i = (n-1)/2; i >= 0; i--)
CreatHeap(a, n, i);
}
创建堆
void CreatHeap (DataType a[], int n, int h)
{
int i, j, flag;
DataType temp;
i = h; // i为要建堆的二叉树根结点下标
j = 2*i+1; // j为i的左孩子结点的下标
temp = a[i];
flag = 0;
//沿左右孩子中值较大者重复向下筛选
while(j < n && flag != 1)
{ //寻找左右孩子结点中的较大者,j为其下标
if(j < n-1 && a[j].key < a[j+1].key) j++;
if(temp.key > a[j].key) //a[i].key>a[j].key
flag=1; //标记结束筛选条件
else //否则把a[j]上移
{
a[i] = a[j];
i = j;
j = 2*i+1;
}
}
a[i] = temp; //把最初的a[i]赋予最后的a[j]
}
堆排序
堆排序的基本思想:循环执行如下过程直到数组为空:
(1)把堆顶a[0]元素(为最大元素)和当前最大堆的最后一个元素交换;
(2)最大堆元素个数减1;
(3)由于第(1)步后根结点不再满足最大堆的定义,所以调整根结点使之满足最大堆的定义。
void HeapSort(DataType a[], int n)
{
int i;
DataType temp;
InitCreatHeap(a, n); //初始化创建最大堆
for(i = n-1; i > 0; i--) //当前最大堆个数每次递减1
{
//把堆顶a[0]元素和当前最大堆的最后一个元素交换
temp = a[0];
a[0] = a[i];
a[i] = temp;
CreatHeap(a, i, 0); //调整根结点满足最大堆
}
}
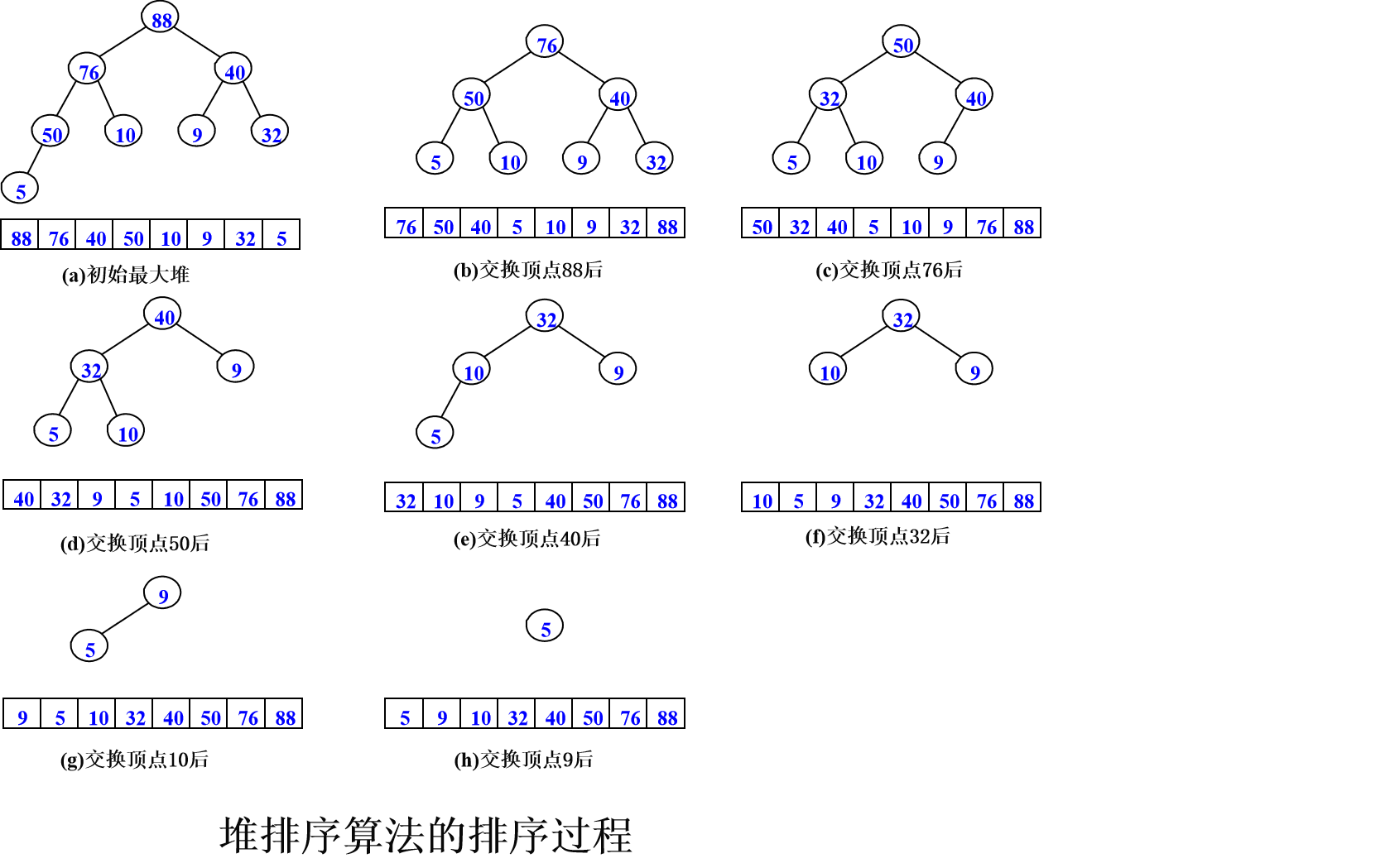
算法分析:
时间效率:O(nlog2n)。因为整个排序过程中需要调用n-1次堆顶点的调整,而每次堆排序算法本身耗时为log2n;
空间效率:O(1)。仅在第二个for循环中交换记录时用到一个临时变量temp。
稳定性: 不稳定。
优点:对小文件效果不明显,但对大文件有效。
总结:创建堆时,其实就是比较父节点与左右孩子的大小,如果父节点较小,则与孩子结点中较大的那个互换,然后再重复此过程向下。对每个父节点都进行相同的操作。 堆排序则是创建了n-1次最大堆或最小堆,但是每次堆中元素都减少一个。
如果不太理解,下列网址中的例子可能较为简单:https://www.cnblogs.com/payapa/p/11192303.html
0x04 交换排序
基本思想:交换数据元素的位置,来实现排序。
常见有:冒泡排序,快速排序。
冒泡排序
基本思想:每趟不断将记录两两比较,并按“前小后大”(或“前大后小”)规则交换。
优点:每趟结束时,不仅能挤出一个最大值到最后面位置,还能同时部分理顺其他元素;一旦下趟没有交换发生,还可以提前结束排序。
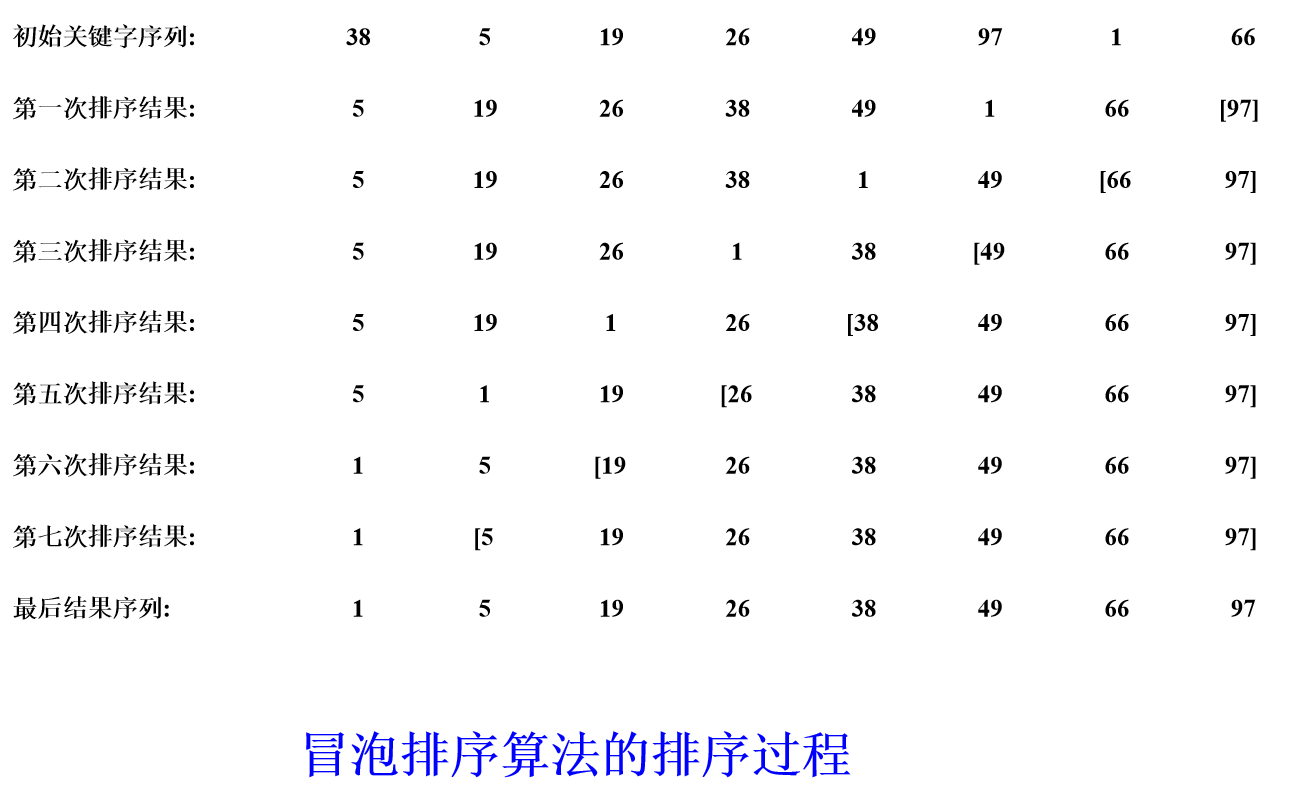
算法分析:
最好情况:初始排列已经有序,只执行一趟起泡,做 n-1 次关键码比较,不移动对象。
最坏情形:初始排列逆序,算法要执行n-1趟起泡,第i趟(1≤ i ≤ n) 做了n- i 次关键码比较,执行了n-i 次对象交换。此时的比较总次数和记录移动次数为:
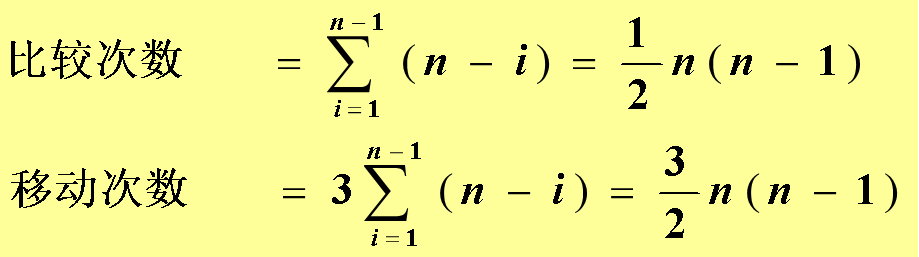
时间效率:O(n的2次方) —考虑最坏情况
空间效率:O(1) —只在交换时用到一个缓冲单元
稳定性: 稳定
核心代码如下:
flag = 1;
temp = a[j];
a[j] = a[j+1];
a[j+1] = temp;
完整代码较为简单,故省略
快速排序
基本思想:从待排序列中任取一个元素 (例如取第一个) 作为中心,所有比它小的元素一律前放,所有比它大的元素一律后放,形成左右两个子表;然后再对各子表重新选择中心元素并依此规则调整,直到每个子表的元素只剩一个。此时便为有序序列了。
优点:每趟可以确定不止一个元素的位置,而且呈指数增加,所以特别快。
详见下列网址:
https://www.runoob.com/w3cnote/quick-sort.html
0x05 归并排序
归并排序主要是二路归并排序。
基本思想:可以把一个长度为n 的无序序列看成是 n 个长度为 1 的有序子序列 ,首先做两两归并,得到 n / 2 个长度为 2 的有序子序列 ;再做两两归并,…,如此重复,直到最后得到一个长度为 n 的有序序列。
下面是一个例子,具体算法略(看参考 https://www.runoob.com/w3cnote/implementation-of-merge-sort.html )。

时间效率:O(nlogn)
空间效率:O(n)
稳定性:稳定
0x06 基数排序
基数排序也称作桶排序,是一种当关键字为整数类型时非常高效的排序方法。
其实是分别对个位数、十位数等按照从大到小(从小到大)多次排序,直到最高位,此时按照队列取出来就是有序的。
设有一个初始序列为: R {50, 123, 543, 187, 49, 30, 0, 2, 11, 100}。
对于任何一个十进制数,它的各个位数上的基数都是以09来表示的。所以我们不妨把09视为10个桶。
我们先根据序列的个位数的数字来进行分类,将其分到指定的桶中。例如:R[0] = 50,个位数上是0,将这个数存入编号为0的桶中。分类后,我们在从各个桶中,将这些数按照从编号0到编号9的顺序依次将所有数取出来。这时,得到的序列就是个位数上呈递增趋势的序列。 按照个位数排序: {50, 30, 0, 100, 11, 2, 123, 543, 187, 49}。
接下来,可以对十位数、百位数也按照这种方法进行排序,最后就能得到排序完成的序列。
代码略。
时间复杂度:O(mn)
空间复杂度:O(n)
稳定性:稳定(一直前后有序)
0x07 各类排序方法比较


 浙公网安备 33010602011771号
浙公网安备 33010602011771号