
数据结构与算法(2)-线性表
Author:Liedra
https://www.cnblogs.com/LieDra/
Ch2 线性表
0x01 线性表的定义和特点
定义
线性表是一种可以在任意位置进行插入和删除数据元素操作、由n(n≥0)个相同类型数据元素a0,a1,…,an-1组成的线性结构。是最常用且最简单的一种数据结构,它是n个数据元素的有限序列。
操作集合:初始化线性表、插入数据元素、求当前数据元素个数、删除数据元素、取数据元素等。
实现方式:线性(数组)、链式(指针)。
注意,下两节所说的存取操作和插入删除操作指的是在某个位置的操作,不是对某个值的操作。
0x02 线性表的顺序表示和实现(顺序表)
定义
使用数组,用一段地址连续的存储单元依次存储线性表的数据元。(一般采用静态数组方法。
编号地址
存储器中的每个存储单元都有自己的编号,这个编号称为地址。
存储位置公式
每个数据元素,不管它是整型,实型还是字符型,都需要占用一定的存储单元空间(假设为x)
那么第i(从0计算)个元素的存储位置为
indexi = index0 + i*x 从这个公式可以得到此时存取操作时间性能为O(1)即常数性能,因为计算机只需要计算一次。
我们通常将存取操作具备常数性能的存储结构称为随机存储结构
顺序表类的定义
类的设计包括两部分:类定义和类实现。类定义给出类的成员变量和成员函数的定义,类实现给出成员函数的具体编码实现。
类的成员变量用来表示抽象数据类型的数据集合,类的成员函数用来表示抽象数据类型的操作集合。
class SeqList //SeqList是类名
{
protected:
DataType *list; //数组元素的数据类型
int maxSize; //最大元素个数
int size; //当前元素个数
public:
SeqList(int max=0); //构造函数
~SeqList(void); //析构函数
int Size(void) const; //取当前数据元素个数
void Insert(const DataType& item,int i); //插入
DataType Delete(const int i); //删除
DataType GetData(int i) const; //取数据元素
};
顺序表类的实现
SeqList::SeqList(int max) //构造函数
{
maxSize = max;
size = 0;
list = new DataType[maxSize];
}
SeqList::~SeqList(void) //析构函数
{
delete[]list;
}
int SeqList::Size(void) const //取当前数据元素个数
{
return size;
}
void SeqList::Insert(const DataType& item, int i) //插入
//在指定位置i前插入一个数据元素item
{
//从size-1至i逐个元素后移
for (int j = size; j > i; j--) list[j] = list[j - 1];
list[i] = item; //在i位置插入item
size++; //当前元素个数加1
}
DataType SeqList::Delete(const int i) //删除
//删除指定位置i的数据元素,删除的元素由函数返回
{
DataType x = list[i];
//取到要删除的元素
//从i+1至size-1逐个元素前移
for (int j = 1; j < size - 1; j++) list[j] = list[j + 1];
size--; //当前元素个数减1
return x; //返回删除的元素
}
DataType SeqList::GetData(int i) const //取数据元素
//取位置i的数据元素,取到的数据元素由函数返回
{
return list[i]; //返回取到的元素
}
注意:
(1)类的成员变量通常设计成私有(private)访问权限,该类要被作为基类继承,所以设计成保护(protected)访问权限。 (2)构造函数要完成对象定义以及初始化赋值 (3)对于动态数组存储结构,析构函数要释放动态申请的内存空间 (4)插入成员函数应该考虑插入位置参数i的范围以及数组的存储空间是否已满
效率分析
时间效率:算法时间主要耗费在移动元素的操作上
- 存取操作:O(1)
- 插入和删除:O(n),因为插入或删除后,需要移动其余元素,有n中位置插入。
优缺点和适用场景
优点:算法简单,空间单元利用率高;
缺点:需要预先确定数据元素的最大个数,插入和删除时需要移动较多的数据元素。
线性表顺序存储结构比较适用于元素存取操作较多,增删操作较少的场景
顺序表类应用举例
编程实现如下任务:建立一个线性表,首先依次输入数据元素1,2,3,…,10,然后删除数据元素5,最后依次显示当前线性表中的数据元素。要求采用顺序表实现,假设该顺序表的数据元素个数在最坏情况下不会超过100个。
实现的方法,利用已设计好的抽象数据类型模块(存放在头文件名为SeqList.h中,通过 #include “SeqList.h” ),直接编写一个主函数实现。
程序如下:
#include <iostream>
#include <stdlib.h>
using namespace std;
typedef int DataType; //定义具体问题元素的数据类型
#include "SeqList.h" //包含顺序表类
int main()
{
SeqList myList(100); //定义顺序表类对象myList
int n = 10;
for (int i = 0; i < n; i++) //在myList中顺序插入10个元素
myList.Insert(i + 1, i);
myList.Delete(4); //删除myList中数据元素5
for (int i = 0; i < myList.Size(); i++)
cout << myList.GetData(i) << " ";
system("pause");
return 0;
}
注意,使用下列语句使得抽象数据类型实际上转为int类型
typedef int DataType;
0x03 线性表的链式表示和实现(单链表)
定义
一个或多个结点组合而成的数据结构称为链表。单链表中构成链表的结点只有一个指向直接后继结点的指针域。其结构特点:逻辑上相邻的数据元素在物理上不一定相邻。
结点一般由两部分构成:
- 数据域:存储真正的数据元素
- 指针域:存储下一个结点(直接后继)的地址(指针)
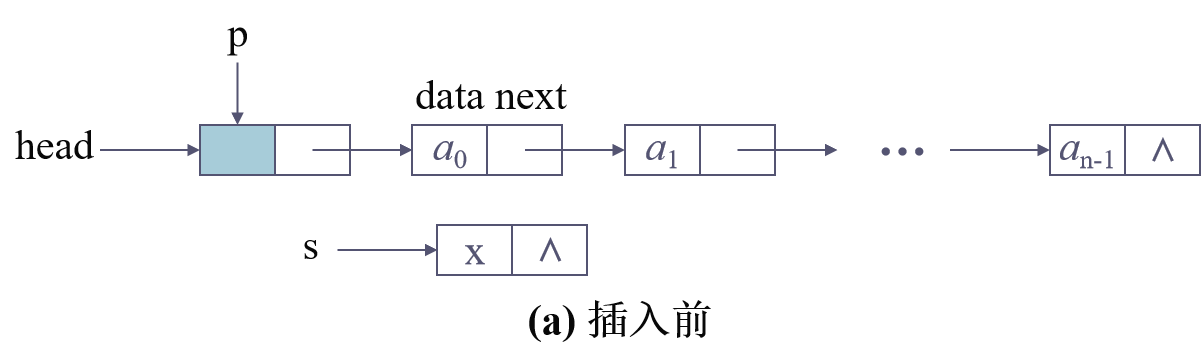
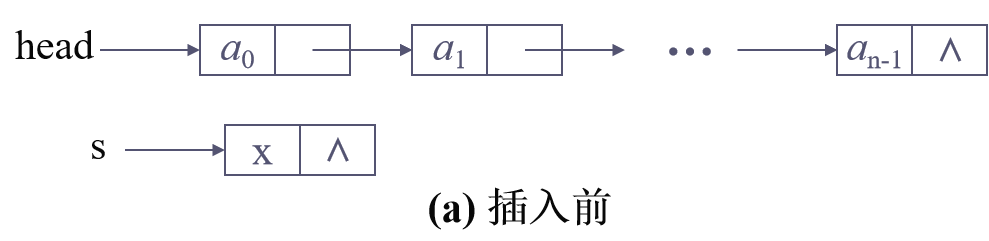
头指针:是指向链表中第一个结点(或为头结点、或为首元结点)的指针。之后的每一个结点,其实就是上一个的后继指针指向的位置。链式存储时只要不是循环链表,就一定存在头指针。
头结点:为了能更加方便地对链表进行操作,会在单链表的首元结点前附设一个结点,称为头结点,其数据域一般无意义(有时也会存链表长度等,头结点不计入表长度)。
元结点是指链表中存储线性表第一个数据元素a0的结点。
头指针与头结点:当不存在头结点时,头指针指向首个有真实数据的结点,当存在头结点时,头指针指向头结点,头结点的指针域指向首个有真实数据的结点。
存在头结点时:
不存在头结点时:
结点类的定义和实现
//List.h
#include<iostream>
template<class T>class List; //前向引用声明
template<class T>
//Node类的定义和实现
class Node
{
public:
friend class List<T>; //List类为友元类
Node(Node<T>* Next = NULL) { next = Next; } //构造函数一,构造头结点,没有data数据
//构造函数二,构造其他结点,有data数据
Node(T& Date, Node<T>* Next = 0)
{
date = Date;
next = Next;
}
~Node() {}
private:
T date;
Node<T>* next; //next指向下一个结点
};
单链表类的定义
这里实现的单链表其实是有序单链表,插入数据是先找到应该插入的位置,再进行插入,非有序的情况下的单链表的实现更加简单。
template<class T>
class List
{
private:
Node<T>* head; //头指针
int size; //数据元素的个数
public:
List(); //构造函数
~List(); //析构函数
Node<T>* Index(int i); //定位
void Insert(T& Data); //插入
T Delete(int i); //删除数据并返回结果
T GetData(int i) { return Index(i)->data; } //获得数据
//这里还可以根据需要添加Get size函数
};
单链表类的实现
实现是如果是带头结点的,那么构造函数要用new运算符动态申请一个头结点并由头指针指示,初始时当前数据元素个数为0。
析构函数要完成单链表中所有结点内存空间的释放。
插入的实现:首先找到第i个结点并由Index(i)指示,动态申请一个新的结点,其next指向第i个结点,然后修改i-1结点的指针域指向新结点。
//List类的实现
template<class T>
List<T>::List()
{
head = new Node<T>(); //头结点指向一个Node类
size = 0; //初始时数据元素个数为0
}
template<class T>
List<T>::~List()
{
Node<T>* p;
while (head != 0) //while删除当前链表的第一个结点,直到head=0,没有结点
{
p = head;
head = p->next;
delete p;
}
size = 0; //数据元素个数为0
}
template<class T>
Node<T>* List<T>::Index(int i)
{ //定位,目的是找指向第i个数据元素的指针并返回
if (i<-1 || i>(size - 1)) //i的范围为-1到size-1
{
cout << "错误的i值" << endl;
exit(0); //错误的话结束
}
if (i == -1)return head; //i=-1时,指向头结点
Node<T>* p = head->next; //p首先指向第0个数据元素结点
int j = 0;
while (p != 0 && j < i) //循环,找到指向第i个结点的指针
{
p = p->next;
j++;
}
return p; //返回指向第i个结点的指针
}
template<class T>
void List<T>::Insert(T& Data) //插入数据,这里的插入是按照大小顺序插入的
{
int i = 0; //从0开始计数
this->size++; //插入数据时该链表数据元素个数加一,这样定位时新加的元素如果在最后,则Index返回指针是空指针
while (Index(i) != 0 && Index(i)->data <= Data) { i++; } //找比data大的所在的结点的指针
Node<T>* p = new Node<T>(Data, Index(i)); //构造新的结点
Index(i - 1)->next = p; //新结点前面的结点的next指向新结点
}
template<class T>
T List<T>::Delete(int i)
{
Node<T>* s, * p = Index(i - 1); //p为指向第i-1个结点指针
s = p->next; //s指向第i个结点
p->next = p->next->next; //第i个结点脱链
T x = s->data;
delete s; //释放第i个结点空间
size--; //结点个数减1
return x; //返回第i个结点的data域值
}
效率分析
时间复杂度:插入和删除操作时不需要移动数据元素,只需要比较数据元素。
- 存取操作:假设需要获取第 i 个元素,则必须从第一个结点开始依次进行遍历,直到达到第 i 个结点。因此,对于单链表结构而言,其数据元素读取的时间复杂度为O(n)
- 插入和删除操作:对其任意一个位置进行增删操作,因为需要先遍历找到目标元素,其时间复杂度为O(n)。
顺序表和单链表比较
只对一个元素进行增删操作时,两种结构并不存在优劣之分,而如果针对多个数据进行增删,那么单链表较为合适,因为后续的增删只是简单的赋值移动指针。
单链表的优点:不需要预先确定数据元素的最大个数,插入和删除操作不需要移动数据元素;
单链表的缺点:每个结点中要有一个指针域,因此空间单元利用率不高。而且单链表操作的算法也较复杂。
总结:对于存取频繁的场景,使用线性表较好,对于插入和删除频繁的场景,使用单链表一般较好。
顺序表类应用举例
编程实现如下任务:建立一个线性表,首先依次输入数据元素1,2,3,…,10,然后删除数据元素5,最后依次显示当前线性表中的数据元素。要求采用单链表实现。
结点类和单链表类的定义和实现代码存放在文件List.h中,通过直接编写一个主函数来实现。
程序如下:
#include <iostream>
using namespace std;
#include"List.h"
int main()
{
List <int> myList;
int s[] = { 1,2,3,4,5,6,7,8,9,10 }, n = 10;
int temp;
for (int i = 0; i < n; i++)
myList.Insert(i);
myList.Delete(4);
for (int i = 0; i < 9; i++)
{
temp = myList.GetData(i);
cout << temp << " ";
}
cout << endl;
system("pause");
return 0;
}
结果
0 1 2 3 5 6 7 8 9
请按任意键继续. . .
0x04 循环单链表和双向链表
循环单链表
实现:循环单链表是单链表的另一种形式,将单链表中的终端结点的指针域由空指针改为指向头结点,使整个单链表形成一个环,这种头尾相连的单循环链表,称为循环链表。循环链表不一定需要头结点。
与单链表区别:主要差异在于循环的判断条件上,单链表判断条件为判断尾结点是否指向空,循环链表判断条件为判断结点是否指向头结点(头指针)
优点:从链尾到链头比较方便。
双向链表
双向链表是每个结点除后继指针域外还有一个前驱指针域,它有带头结点和不带头结点,循环和非循环结构,双向链表是解决查找前驱结点问题的有效途径。在单链表的每个结点中,再设置一个指向其前驱结点的指针域。
p->next->prior=p;p->prior->next=p
0x05 静态链表
在数组中增加一个(或两个)指针域用来存放下一个(或上一个)数据元素在数组中的下标,从而构成用数组构造的单链表。因为数组内存空间的申请方式是静态的,所以称为静态链表,增加的指针称做仿真指针。
0x06 其他
在上述顺序类的基础上,还可以通过设计完成相应功能的函数,来达到对顺序表中某些数据元素x的删除,将单链表原地排序等功能。具体设计要根据实际情况进行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号