
信用评分预测模型(二)--数据基本统计分析和标准化
Author:Liedra
https://www.cnblogs.com/LieDra/
前言
数据基本统计分析和标准化是同时进行的。
其中数据基本统计中,对于标称型数据,统计缺失值数量,分级情况,众数以及众数占比。对于数值型数据,主要统计了均值,标准差,缺失值数量,最小值,最大值,中位数。
标准化与否对结果也会有一定的影响,我们先观察下现在标准化的状态。
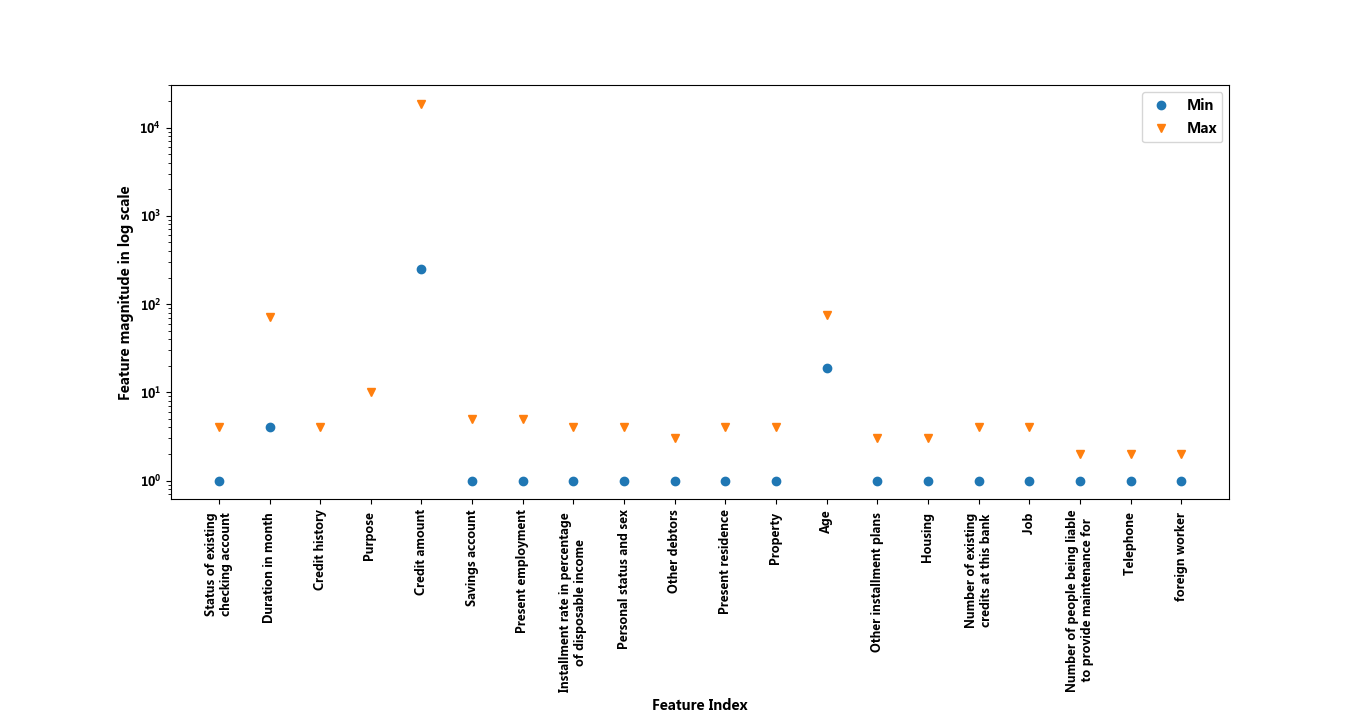
发现有个别属性值过大,可能会导致对模型产生误导影响。因此在某些模型中需要对数据进行标准化。
其中标准化过程使用的是最常用的z标准化,即零-均值规范化,也称标准差标准化,经过处理的数据的均值为0,标准差为1。
转化公式中用到数据为属性的均值和方差。
下面是对数据进行基本统计分析和标准化的过程。
代码示例
'''
version:
author:LieDra
Method:基本统计分析、数据标准差标准化
'''
import pandas as pd
#读取文件
readFileName="D:/study/5/code/python/python Data analysis and mining/class/dataset/german-13q.xls"
# readFileName="D:/study/5/code/python/python Data analysis and mining/class/dataset/german-7n.xls"
#读取excel
df=pd.read_excel(readFileName)
# print()
x=df.ix[:,:-1]
print('q')
# for i in range(1,8):
# print(i,x['a'+str(i)].avg(),x['a'+str(i)].std())
result = {}
for col in df.columns[:-1]:
result[col]=[]
print(x[col].value_counts(1,ascending=True)) # 算每列标称属性的频率,得到众数所占比例
# # print(' max: ',x[col].max(),'min:',x[col].min(),'median:',x[col].median())
print(col,'\n mean:',x[col].mean(),' std: ',x[col].std())
print(' max: ',x[col].max(),'min:',x[col].min(),'median:',x[col].median())
for each in x[col]:
result[col].append((each-x[col].mean())/x[col].std())
result[col].append(each/(x[col].max()))
result['resu']=[]
result['resu']=df.ix[:,-1]
# for col in df.columns[:-1]:
# for each in x[col]:
# print(each,end=' ')
# print()
result2 = pd.DataFrame(result,columns=df.columns[:-1])
# result2 = pd.DataFrame(result,columns=df.columns)
# for each in result:
# print(each)
print(result)
# result2.to_excel(r"dataset\german-13q-z.xls")
数据基本统计结果已经在(1)中展示,如下图
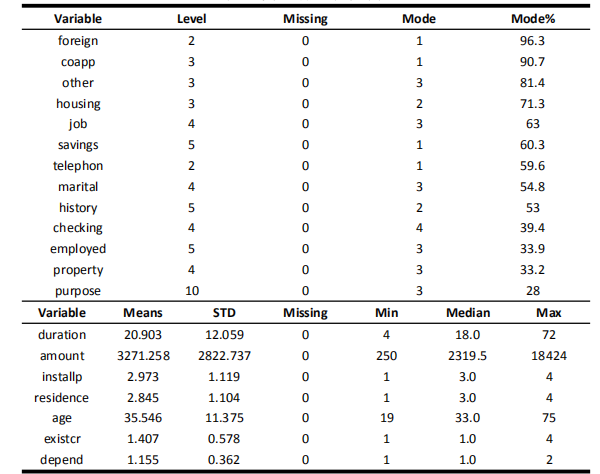
标准化后的结果保存到文件中,并手工将标称型数据和数值型数据合并到一个表格中,以方便之后的处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号