
信用评分预测模型(一)--介绍
Author:Liedra
https://www.cnblogs.com/LieDra/
前言
在金融市场的不断发展下,信用评分对于一个人的影响比以前更大。
在当今社会,信用消费逐步成为了一种新的生活方式,有数据表明,越来越多的居民由传统储蓄转变为提前消费。因此,保证信贷经济的平稳是一个很 重要的研究领域。对银行来说,预先判断客户是否会违约有利于提升银行的盈利; 对整个社会来说,可以减少信用欺诈现象,去除信贷经济的泡沫。 本文研究的主要目的是通过对数据集的挖掘,建立评估人们还款能力的模 型,预测违约情况,最终希望判断出何种模型对于评价该分类更加精确。本文综 合分析了信用评估常用的模型,选取了逻辑回归、决策树、随机森林、支持向量 机、多层感知机五个模型进行分析,另外,我们考虑到单一分类器的局限性,于 是对模型进行组合,并与之前的单一模型进行比较,以期获得更好的预测效果, 为银行系统提供更好的建议,并以此为借鉴,可以让相应机构制定相关的措施。
对于银行来说,如何识别“好”客户和“坏”客户尤为重要。相对来说,相对于识别出“好”客户带来收益,如何识别出“坏”客户的意义更大,因为它可以减少不必要的损失。
数据介绍和说明
而对于信用预测而言,数据集较为敏感,很多数据集并不对外开放。本次我们应用UCI机器学习库中的German信用数据(网址为http://www.ics.uci.edu/~mlearn/databases/statlog/german/)。这个数据集由汉堡大学的一名教授提供。数据集中共有1000条记录,包含700个信誉良好的客户和300个违约的 客户。每条数据对应一个申请人,有二十个属性和一个标签。
其中有7个不同的数值属性,包括 持续时间(duration in month),借贷额度(credit amount),分期付款金额 占可支配收入的比例(installment rate in percentage of disposable income), 现居住地居住时间(present residence since),年龄(age),在本银行为清 偿的贷款额(number of existing credits at this bank ) , 需 要 赡 养 的 人 数 ( number of people being liable to provide maintenance for)。
还有 13 个为非数值属性,包括现 有的经常账户状况(status of existing checking account),信用历史(Credit history),信贷目的(purpose),储 蓄账户(savings account),当前工龄 (present employment since),婚姻状 况(personal status and sex),其他应 收账款(other debtors),抵押类型 (property),其他分期付款计划(other installment plan),住房情况(housing), 工 作 状 态 ( job ) , 电 话 状 态 (telephone),是否是外籍工作者 (foreign worker)。全部的 20 个变量 的统计结果如下所示。
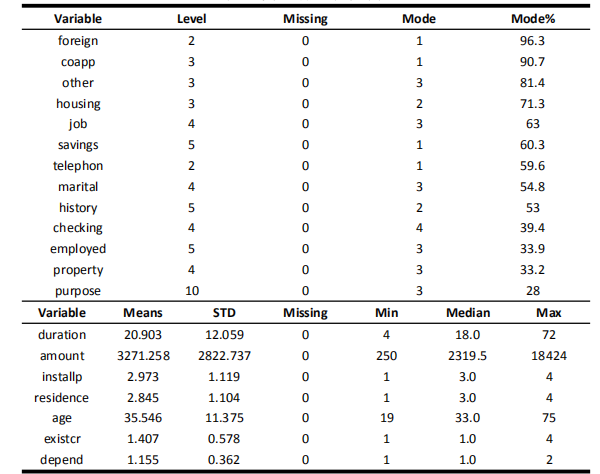
由统计可以看出,对于是否为外籍工作者、其他应收账款和其他分期付款计划这三种非数值属性,众数所占全部数据的百分比高达80%以上,因此其可能并不是很重要的属性,但并 不能因此直接舍弃这些属性,还要继续对此分析才能决定是否舍弃。除此之外,原始数据集中的数值型属性取值范围差别很大,对于模型的建立有一定的影响。为了构建出一个合理的模型,需要对数据进行一定的预处理。
数据预处理的部分将在稍后讨论。
我们将利用这些数据和预处理后的数据建立模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号