Python爬取猫眼电影榜单电影数据以及遇到问题总结
代码
import csv
import random
import re
import time
from urllib import request
from fake_useragent import UserAgent
#定义一个爬虫类
class MaoyanSpider(object):
#定义初始页面url
def __init__(self):
self.url='https://maoyan.com/board/4?offset={}'
#请求函数
def get_html(self,url):
ac = ''
ua = UserAgent()
with open('../accept.txt', 'r') as f:
ac = f.read()
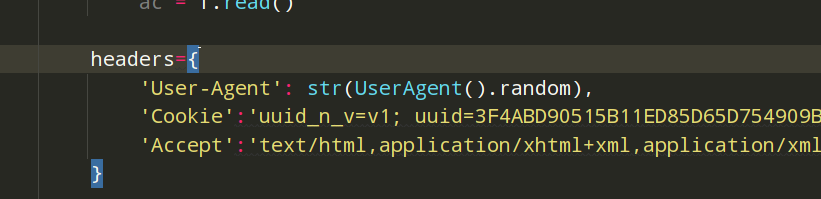
headers={
'Content-Type': 'text/plain; charset=UTF-8',
'Origin': 'https://maoyan.com',
'Referer': 'https://maoyan.com/board/4',
'User-Agent': str(UserAgent().random),
'Cookie':'uuid_n_v=v1; uuid=3F4ABD90515B11ED85D65D754909B702AF37B8DA83644A4088E2E969F595441F; _lxsdk_cuid=183fb51d246c8-06c430d6eb2ef5-7b555476-d34f0-183fb51d246c8; _csrf=340d884c8d1befce8efd5f08d3a0cfe3c966cf66dec884ef3a06390c984cb7b0; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1666368787,1666401162; __mta=48668313.1666368787309.1666372933563.1666401171306.8; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1666401708; _lxsdk=3F4ABD90515B11ED85D65D754909B702AF37B8DA83644A4088E2E969F595441F; _lxsdk_s=183fd3fd1d6-237-700-88b%7C%7C21',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
}
req=request.Request(url=url,headers=headers)
res=request.urlopen(req)
html=res.read().decode()
#直接调用解析函数
self.parse_html(html)
def parse_html(self,html):
# 正则表达式
re_bds = '<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?class="releasetime">(.*?)</p>'
# 生成正则表达式对象
pattern = re.compile(re_bds, re.S)
# r_list: [('我不是药神','徐峥,周一围,王传君','2018-07-05'),...] 列表元组
r_list = pattern.findall(html)
print(html)
self.save_html(r_list)
def save_html(self,r_list):
#生成文件对象
with open('D:/桌面/PyCases/maoyan.csv','a+',newline='',encoding='utf-8-sig') as f:
headfile=['片名','主演','上映时间']
writer=csv.DictWriter(f,fieldnames=headfile)
writer.writeheader()
for r in r_list:
name=r[0].strip()
star=r[1].strip()[3:]
time=r[2].strip()[5:15]
writer.writerow({'片名':name,'主演':star,'上映时间':time})
print(name,star,time)
def run(self):
print('开始抓取.....')
begin=time.time()
for offset in range(0,21,10):
print(offset)
url=self.url.format(offset)
self.get_html(url)
time.sleep(random.uniform(2,3))
end=time.time()
print('抓取完成')
print('执行时间:%.2f' % (end - begin))
if __name__ == '__main__':
try:
spider = MaoyanSpider()
spider.run()
except Exception as e:
print("错误",e)
所遇到的问题
1. 爬取网页中遇到认证的问题
解决办法:
在请求头中加入‘Accept’,‘Cookie’
2.爬取数据生成csv表格时数据覆盖的问题
解决办法:
with open('w')改为with open('a+')
'a+'为追加数据
'w'为写入数据

下一步需要解决的问题
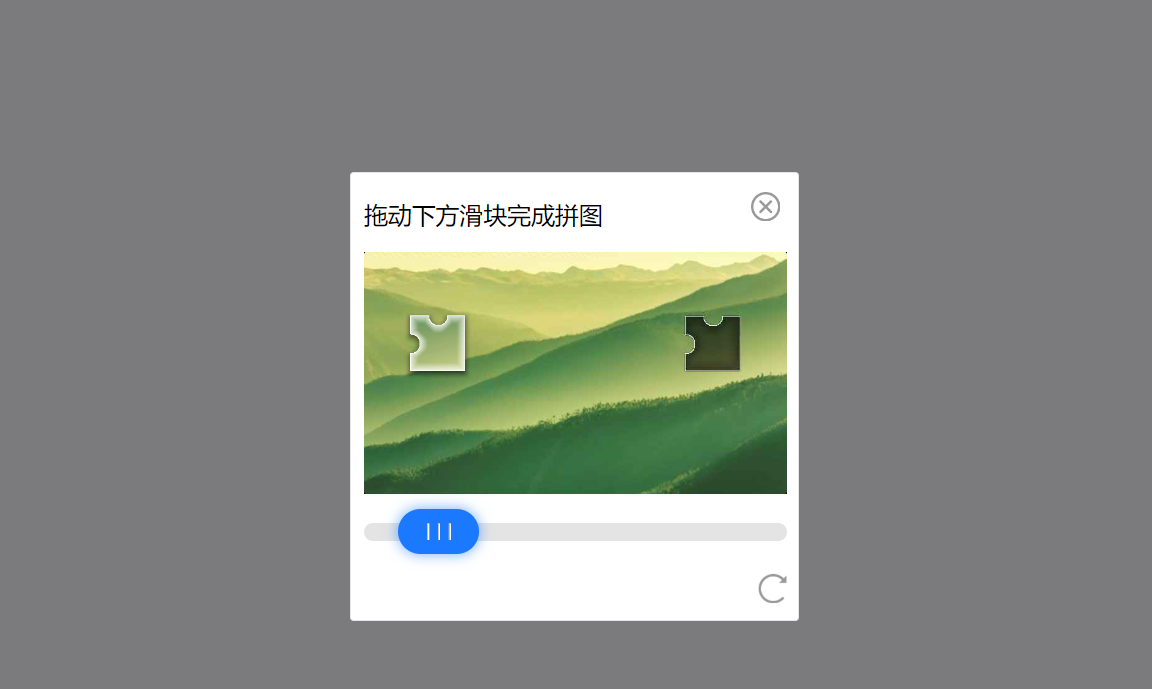
在爬取过程中,网页的反爬措施为需要滑动验证,需要手动操作才能继续爬取

 浙公网安备 33010602011771号
浙公网安备 33010602011771号