云原生在各大厂的落地与分析
随着k8s成为事实上的容器编排标准,在容器编排上很难说有严格意义上的竞品,各大厂云平台也几乎是对k8s进行插件开发、或是其核心组件进行二次开发,而不是对k8s的架构进行更改(其本身架构已足够优秀)。这样既既符合社区的期望、也降低了开发人员门槛。
云原生的概括(引用自字节跳动云原生)
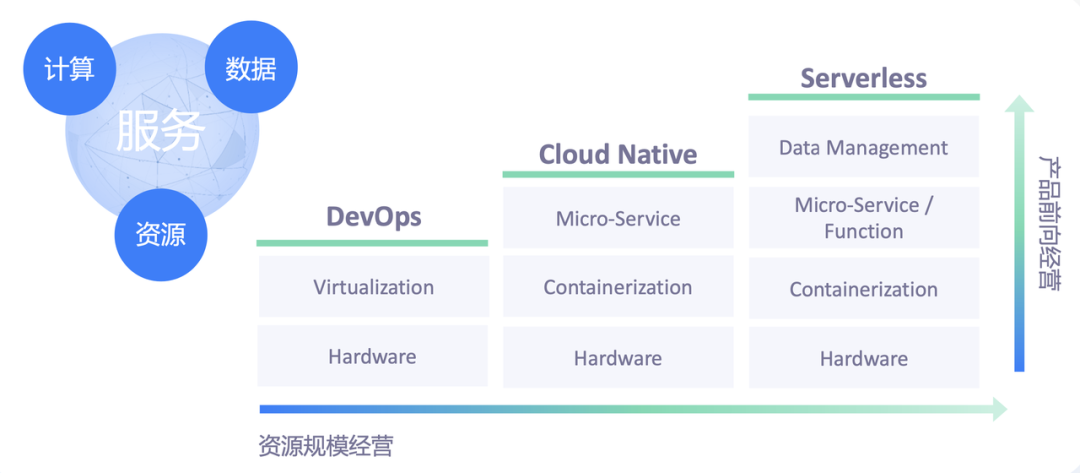
云原生相近的技术体系分成了 DevOps、Cloud Native 以及 Serverless 三代。
- DevOps:更多强调管理和运维的自动化。主流的服务开发模式是以虚拟机作为底层的资源抽象模型,以 Jenkins 之类的一些自动化管理平台来部署单体应用,进而实现运维管理自动化;
- Cloud Native:以微服务模式为主。在资源方面以容器作为更小、更灵活的资源交付单元,辅以 Kubernetes 等容器编排引擎,来管理服务的部署和运维。开发者的效率得到了更大的释放,极大增加了业务产品自身的迭代效率;
- Serverless:开发者以函数或者极度简化的微服务代码来表达自身的业务逻辑,以事件作为数据模型来表达服务上下游之间的请求和响应。把容量管理、请求路由和服务治理等运维层面的需求下沉到底层的基础设施来统一支持,服务开发者只需聚焦在自己的业务逻辑上。开发和生产的效率会进一步提升。
这三代技术总体是沿着两个路径在往前推进,分别是产品前向一体化,以及资源规模化。这两种思路从两个角度分别推动着技术体系的演进。
- 产品前向一体化:这种思路的核心是如何标准化地把业务的计算逻辑、数据管理模型、资源管理等方面的共性需求抽取出来,沉淀到基础设施当中,使得开发者可以用更少、更简洁的代码高效表达自身的需求;
- 资源规模化:这种思路更多体现在优化上,关注资源池本身的规模化优势,通过大量的并池、资源的混用以及调度等优化手段,实现资源成本降低的目的。
从技术体系迭代来看,字节跳动技术体系往后迭代方向可以总结为下面的主题:
- 无需管理的基础设施
- 自动扩展和伸缩
- 提升开发效率
- 提升资源效率
- 按需付费,节省成本
我们希望朝这些主题方向努力,最终形成下一代的 Serverless 基础设施。
过去各公司的迭代
字节——16年开始的虚拟化、容器化,直接上的k8s。
美团——16年自研(验证容器可行性)到18拥抱k8s。
携程——2017基于Mesos上的自研调度器到18年K8s fork版本的调度器。
基础架构部门——之前基于自研引擎Raw-Docker,22年拥抱k8s。
本部门——由于前人的积累的经验,20年选择了k8s作为上云的基本组件。
同期的公司都做了什么?
统一调度接入能力优化
携程
算法集参数化配置
Pod所属的业务类型不同,对Pod的调度算法选取以及权重参数等可能不同。
解决方案:
增强了调度器Policy机制,引入了PolicyCacheProvider对象。
亲和性参数化配置
多维度的亲和性需求使业务方会涉及过多底层实现细节,导致其心智负担过重。
解决方案:
对NodeAffinity/PodAffinity进行了PolicyTemplate的CRD抽象,分别提炼出NodeSchedulerConfig和PodSchedulerConfig以及SchedulerConfigBinding对象。
Pod在创建时,会由sched-webhook根据绑定的Policy,更新Pod Spec。因此,业务方在使用时,不必再自己组装Pod Spec中的细节,可以直接通过Annotation指定预设好的Pod的亲和性调度规则,平台管理员也可以通过创建Binding对象透明改变Pod的调度行为。
美团
kube-scheduler性能优化
如果有上万台 Node节点,预选、优选和选定判断逻辑会浪费很多计算时间,这也是调度器性能低下的一个重要因素。
解决方案:
提出了“预选失败中断机制”,即一旦某个预选条件不满足,那么该 Node即被立即放弃,后面的预选条件不再做判断计算,从而大大减少了计算量,调度性能也大大提升。(Kubernetes1.10版本发布并开始作为默认的调度策略)
kubelet风险可控性改造
稳定性和风险可控性对大规模集群管理来说非常重要。从架构上来看,Kubelet是离真实业务最近的集群管理组件,社区版本的Kubelet对本机资源管理有着很大的自主性,试想一下,如果某个业务正在运行,但是Kubelet由于出发了驱逐策略而把这个业务的容器干掉了会发生什么?这在集群中是不应该发生的,所以需要收敛和封锁Kubelet的自决策能力,它对本机上业务容器的操作都应该从上层平台发起。
解决方案:
容器重启策略
Kernel升级是日常的运维操作,在通过重启宿主机来升级Kernel版本的时候,发现宿主机重启后,上面的容器无法自愈或者自愈后版本不对,这会引发业务的不满,也造成了不小的运维压力。后来为Kubelet增加了一个重启策略(Reuse),同时保留了原生重启策略(Rebuild),保证容器系统盘和数据盘的信息都能保留,宿主机重启后容器也能自愈。
IP状态保持
根据美团点评的网络环境,自研了CNI插件,并通过基于Pod唯一标识来申请和复用IP。做到了应用IP在Pod迁移和容器重启之后也能复用,为业务上线和运维带来了不少的收益。
限制驱逐策略
知道Kubelet拥有节点自动修复的能力,例如在发现异常容器或不合规容器后,Kubelet会对它们进行驱逐删除操作,这对于美团来说风险太大,美团允许容器在一些次要因素方面可以不合规。例如当Kubelet发现当前宿主机上容器个数比设置的最大容器个数大时,会挑选驱逐和删除某些容器,虽然正常情况下不会轻易发生这种问题,但是也需要对此进行控制,降低此类风险。
可扩展性
解决方案:
资源调配
在Kubelet的扩展性方面增强了资源的可操作性,例如为容器绑定Numa从而提升应用的稳定性;根据应用等级为容器设置CPUShare,从而调整调度权重;为容器绑定CPUSet等等。
增强容器
打通并增强了业务对容器的配置能力,支持业务给自己的容器扩展ulimit、io limit、pid limit、swap等参数的同时也增强容器之间的隔离能力。
应用原地升级
大家都知道,Kubernetes默认只要Pod的关键信息有改动,例如镜像信息,就会出发Pod的重建和替换,这在生产环境中代价是很大的,一方面IP和HostName会发生改变,另一方面频繁的重建也给集群管理带来了更多的压力,甚至还可能导致无法调度成功。为了解决该问题,美团打通了自上而下的应用原地升级功能,即可以动态高效地修改应用的信息,并能在原地(宿主机)进行升级。
算法优化
携程
扩展的资源平衡算法
balanced_allocation没有考虑其它维度的资源
解决方案:
携程扩展了balanced_allocation算法,将更多资源加入计算过程,同时赋予不同资源不同的权重
水位感知的堆叠与打散算法
大量宿主机剩余一些碎片不能被分配出去,特别是一些大配置的Pod无法调度成功
解决方案:
修改了策略,引入一个集群整体资源水位的概念,用来切换打散策略和堆叠策略。
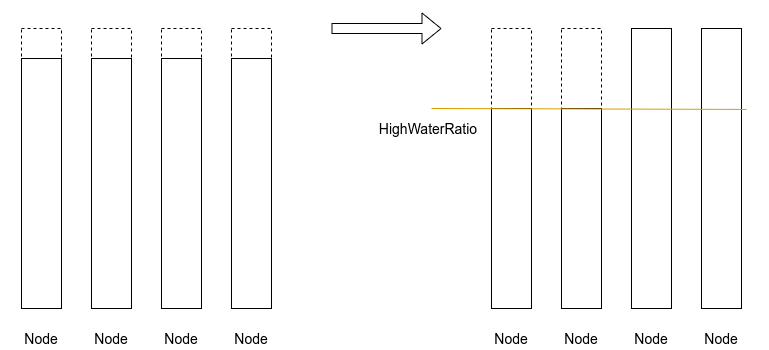
当整个集群中已经被分配出去的资源占总体资源的比例超过一个阈值,则切换为堆叠策略,这些“边脚料”资源就能攒在一起,被充分利用。通过这种方式,在资源紧张的时期,美团私有云的分配率极限可以达到98%。
资源利用率的提升
字节
在线 Web 服务和离线批式作业混合
解决方案:
在离线混合部署方案,通过单机多维度的资源隔离以及中心 + 节点两级管控的策略,很好地支持了两种服务进行并池尝试。
在线算服务和离线训练作业
解决方案:
采取了弹性并池方案,即在在线业务低峰的时段将在线资源进行缩容,腾出空闲的资源供给离线业务使用,从而实现资源的分享复用,提高资源利用效率。
美团
资源池的隔离
精细化的资源调度和运营,之所以做精细化运营主要是出于两点考虑:业务的资源需求场景复杂,以及资源不足的情况较多。
美团依托私有云和公有云资源,部署多个Kubenretes集群,这些集群有些是承载通用业务,有些是为特定应用专有的集群,在集群维度对云端资源进行调配,包括机房的划分、机型的区分等。在集群之下,又根据不同的业务需要,建设不同业务类型的专区,以便做到资源池的隔离来应对业务的需要。更细的维度,美团针对应用层面的资源需求、容灾需求以及稳定性等做集群层的资源调度,最后基于底层不同硬件以及软件,实现CPU、MEM和磁盘等更细粒度的资源隔离和调度。
Numa感知与绑定
用户的另一个痛点与容器性能和稳定性相关。美团不断收到业务反馈,同样配置的容器性能存在不小的差异,主要表现为部分容器请求延迟很高,经过测试和深入分析发现:这些容器存在跨Numa Node访问CPU,在将容器的CPU使用限制在同一个Numa Node后问题消失。所以,对于一些延迟敏感型的业务,要保证应用性能表现的一致性和稳定性,需要做到在调度侧感知Numa Node的使用情况。
解决方案:
更加底层的软硬件配合,在Node层采集了Numa Node的分配情况,在调度器层增加了对Numa Node的感知和调度,并保证资源使用的均衡性。对于一些强制需要绑定Node的敏感型应用,如果找不到合适的Node则扩容失败;对于一些不需要绑定Numa Node的应用,则可以选择尽量满足的策略。
经验心得
在容器时代,不能只看k8s本身,对于企业内的基础设施,“向上”和“向下”的融合和兼容问题也很关键。“向上”是面向业务场景为用户提供对接,因为容器并不能直接服务于业务,它还涉及到如何部署应用、服务治理、调度等诸多层面。“向下”,即容器与基础设施相结合的问题,这里更多的是兼容资源类型、更强大的隔离性、更高的资源使用效率等都是关键问题。
- 落地以用户痛点为突破口,业务是比较实际的,为什么需要进行迁移?业务会怕麻烦、不配合,所以推进要找到业务痛点,从帮助业务的角度出发,效果就会不一样。
- 内部的集群管理运营的价值展现也是很重要的一环,让用户看到价值,业务看到潜在的收益,他们会主动来找你。
目前的存在问题&&未来的建设重点
资源池暂未很好的分化、区分
- 资源池化分级
暴露太多业务方不关心的配置
- CRD(Custom Resource)定制资源与 Operator
服务没有优先级。
- 任务优先级分级
解决资源利用率与服务质量的矛盾
-
不同的层次上进行优先级的分类
-
自定义合适的在离线混部驱逐策略策略
参考文章:
3、10W+ K8s容器数量下,携程如何打造统一弹性调度体系

 浙公网安备 33010602011771号
浙公网安备 33010602011771号