import pandas as pd
import numpy as np
import matplotlib as mp
from pandas.core.algorithms import SelectN, diff
import seaborn as se
from matplotlib import pyplot as plt
import wordcloud
import jieba
import logging
from PIL import Image
##设置中文
plt.rcParams["font.sans-serif"]=['Microsoft YaHei']
plt.rcParams["axes.unicode_minus"]=False
##读取csv数据
file_path1='./2019-10-01_2021-05-30_accrued_income_iPhone.CSV'
df1=pd.read_csv(file_path1)
##更改设置日期时间格式
df1['date']=pd.to_datetime(df1['date'])
print(df1)
print(df1.info())
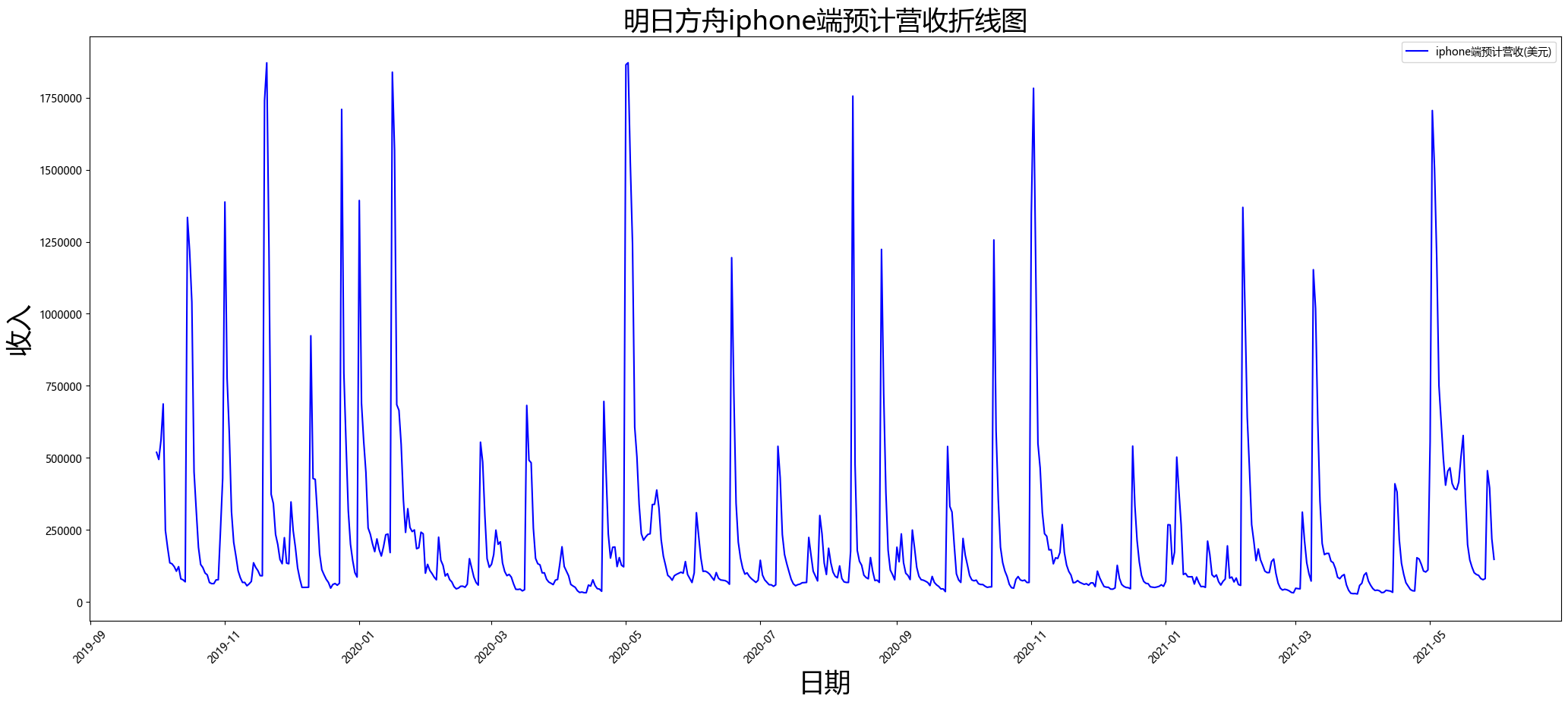
##绘制折线图
##设置画布
plt.figure(figsize=(25,10),dpi=100)
##设置y轴为标注计数法
plt.ticklabel_format(axis='y',style='plain',useOffset=False,useLocale=False)
##画图
plt.plot(df1['date'],df1['accrued_income_iPhone'],label='iphone端预计营收(美元)',color="b")
##设置横纵轴和标题
plt.legend(loc='upper right')
plt.xticks(rotation=45)
plt.xlabel('日期',fontsize=25)
plt.ylabel('收入',fontsize=25)
plt.title('明日方舟iphone端预计营收折线图',fontsize=25)
plt.show()
date accrued_income_iPhone
0 2019-10-01 519152
1 2019-10-02 494288
2 2019-10-03 561249
3 2019-10-04 687069
4 2019-10-05 248241
.. ... ...
603 2021-05-26 80903
604 2021-05-27 455368
605 2021-05-28 395334
606 2021-05-29 218846
607 2021-05-30 147614
[608 rows x 2 columns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 608 entries, 0 to 607
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 608 non-null datetime64[ns]
1 accrued_income_iPhone 608 non-null int64
dtypes: datetime64[ns](1), int64(1)
memory usage: 9.6 KB
None
![]()
##读取csv数据
file_path2='./bilibili.csv'
file_path3='./Sina_Visitor_System.csv'
df2=pd.read_csv(file_path2)
df3=pd.read_csv(file_path3)
##设置日期格式
df2['date']=pd.to_datetime(df2['date'])
df3['date']=pd.to_datetime(df3['date'])
##抓取需要数据
df2=df2[df2['date']>='2019-09-30']
df3=df3[df3['date']>='2019-09-30']
print(df2.head())
print(df2.info())
print(df3.head())
print(df3.info())
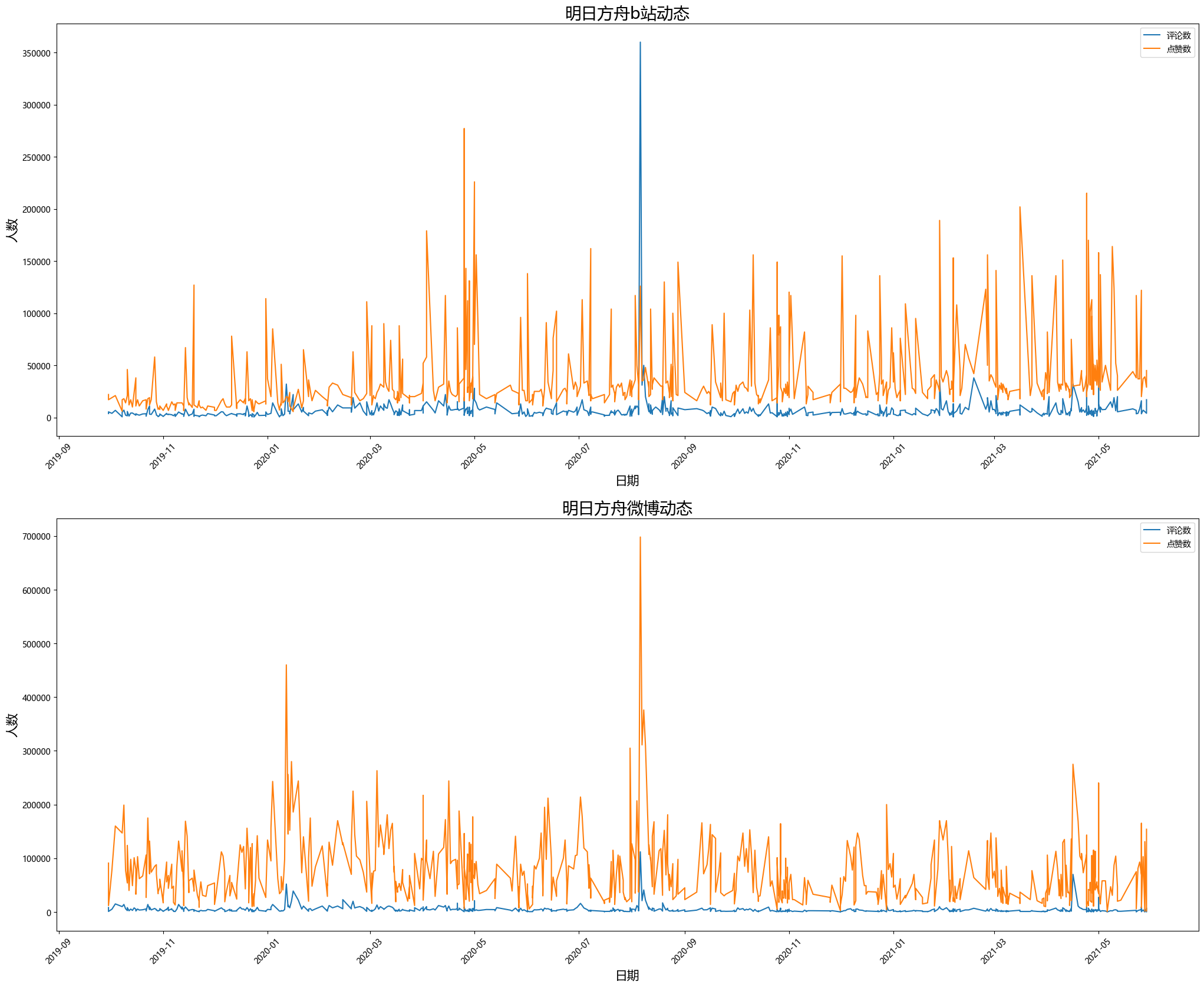
##分别绘制折线图
#设置画布
plt.figure(figsize=(25,20),dpi=100)
##生成图一
plt.subplot(2,1,1)#要生成两行一列,这是第一个图plt.subplot('行','列','编号')
##画图——折线图
# plt.plot(df2['date'],df2['reshare_bilibili'],label='转发数')
plt.plot(df2['date'],df2['comment_bilibili'],label='评论数')
plt.plot(df2['date'],df2['like_bilibili'],label='点赞数')
#设置横纵轴,标题
plt.legend(loc='upper right')
plt.xticks(rotation=45)
plt.xlabel('日期',fontsize=15)
plt.ylabel('人数',fontsize=15)
plt.title('明日方舟b站动态',fontsize=20)
#生成图二
plt.subplot(2,1,2)
##折线图
# plt.plot(df3['date'],df3['reshare_sina'],label='转发数')
plt.plot(df3['date'],df3['comment_sina'],label='评论数')
plt.plot(df3['date'],df3['like_sina'],label='点赞数')
#设置横纵轴,标题
plt.legend(loc='upper right')
plt.xticks(rotation=45)
plt.xlabel('日期',fontsize=15)
plt.ylabel('人数',fontsize=15)
plt.title('明日方舟微博动态',fontsize=20)
plt.show()
标题 标题链接 date content-ellipsis \
293 NaN NaN 2019-09-30 互动抽奖 #明日方舟# #明日方舟bilibili账号突破两百万粉丝纪念# *在10月1日...
294 NaN NaN 2019-09-30 #明日方舟#【常驻标准寻访预告】起止时间:10月3日04:00~10月17日03:59寻访说...
295 NaN NaN 2019-10-02 #明日方舟#【新增干员】//红云“红云,猎人。给我工作吧,你不会失望的。”————————...
296 NaN NaN 2019-10-04 #明日方舟#微型故事集「战地秘闻」任务赠送干员//炎客“警醒能延续你的生命。”———————...
297 NaN NaN 2019-10-08 互动抽奖 #明日方舟# #明日方舟bilibili账号突破两百万粉丝纪念# *在10月1日...
reshare_bilibili comment_bilibili like_bilibili
293 76000 3734 22000
294 207 5372 17000
295 203 3946 19000
296 382 6822 21000
297 167 589 5976
<class 'pandas.core.frame.DataFrame'>
Int64Index: 664 entries, 293 to 956
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 标题 264 non-null object
1 标题链接 264 non-null object
2 date 664 non-null datetime64[ns]
3 content-ellipsis 497 non-null object
4 reshare_bilibili 664 non-null object
5 comment_bilibili 664 non-null int64
6 like_bilibili 664 non-null int64
dtypes: datetime64[ns](1), int64(2), object(4)
memory usage: 41.5+ KB
None
weibo-text date surl-text \
497 #明日方舟#【常驻标准寻访预告】起止时间:10月3日04:00~10月17日03:59寻访说... 2019-09-30 #明日方舟#
498 #明日方舟# 9月30日16:00闪断更新公告感谢您对《明日方舟》的关注与支持。《明日方舟》... 2019-09-30 #明日方舟#
499 #明日方舟#【新增干员】//红云“红云,猎人。给我工作吧,你不会失望的。”————————红... 2019-10-02 #明日方舟#
500 #明日方舟# 微型故事集「战地秘闻」任务赠送干员//炎客“警醒能延续你的生命。”——————... 2019-10-04 #明日方舟#
501 #明日方舟#【新增干员】//送葬人“罗德岛的博士,你好。我是与贵司签署了清理协议的拉特兰公民... 2019-10-08 #明日方舟#
reshare_sina comment_sina like_sina
497 4194 8308 91000
498 134 984 12000
499 3641 5151 78000
500 11000 15000 160000
501 12000 10000 147000
<class 'pandas.core.frame.DataFrame'>
Int64Index: 667 entries, 497 to 1163
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 weibo-text 667 non-null object
1 date 667 non-null datetime64[ns]
2 surl-text 631 non-null object
3 reshare_sina 667 non-null int64
4 comment_sina 667 non-null int64
5 like_sina 667 non-null int64
dtypes: datetime64[ns](1), int64(3), object(2)
memory usage: 36.5+ KB
None
![]()
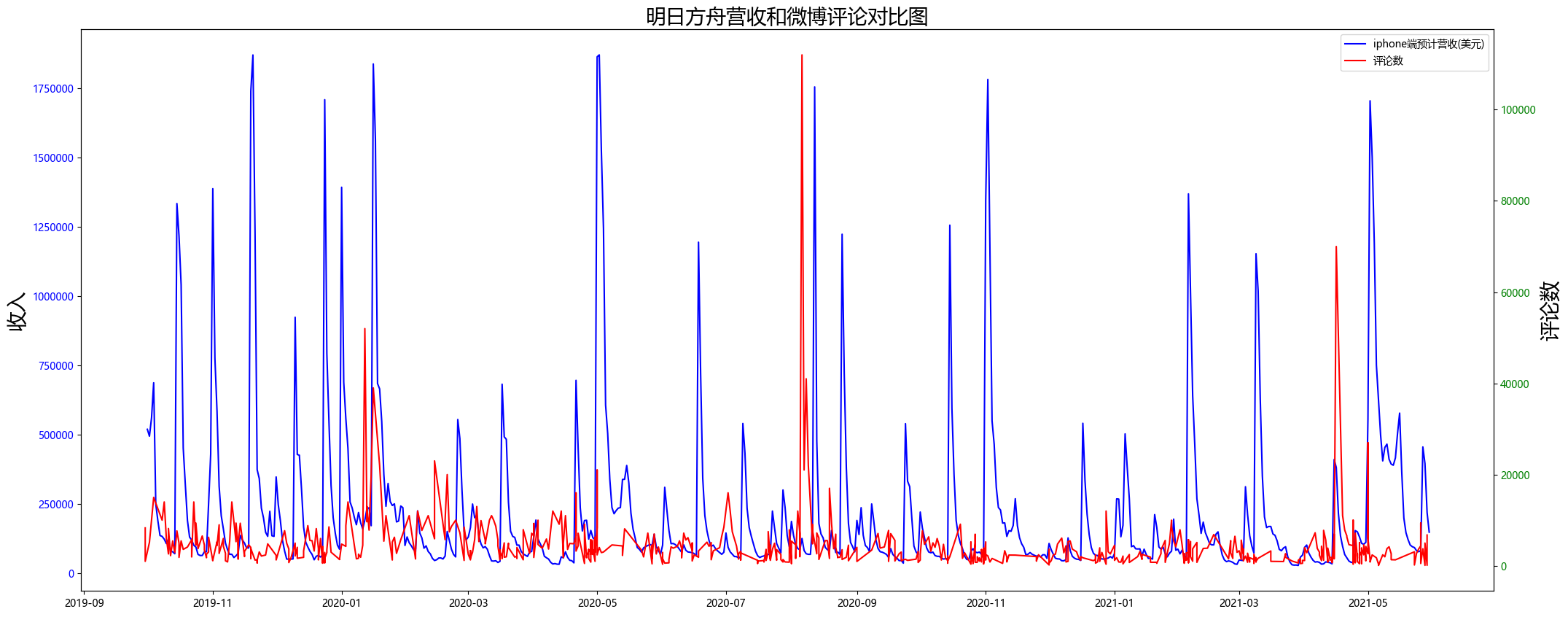
##设置画布
fig,ax1=plt.subplots(figsize=(25,10))
plt.title('明日方舟营收和微博评论对比图',fontsize=20)
plt.ticklabel_format(axis='y',style='plain',useOffset=False,useLocale=False)
##画图
plot1=ax1.plot(df1['date'],df1['accrued_income_iPhone'],color='b',label='iphone端预计营收(美元)')
ax1.set_ylabel('收入',fontsize=20)
for tl in ax1.get_yticklabels():
tl.set_color('b')
ax2=ax1.twinx()
plot2=ax2.plot(df3['date'],df3['comment_sina'],color='r',label='评论数')
ax2.set_ylabel('评论数',fontsize=20)
for tl in ax2.get_yticklabels():
tl.set_color('g')
lines = plot1 + plot2
ax1.legend(lines, [l.get_label() for l in lines])
plt.show()
![]()
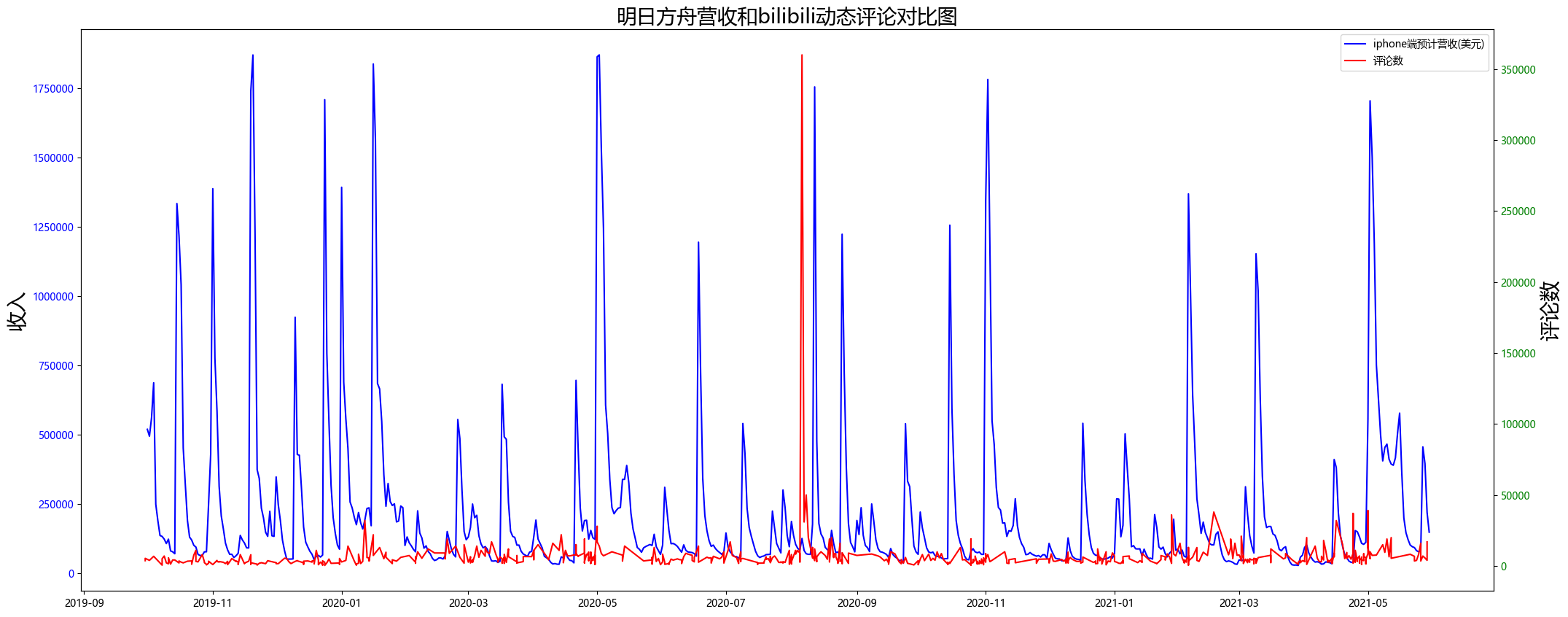
##设置画布
fig,ax1=plt.subplots(figsize=(25,10))
plt.title('明日方舟营收和bilibili动态评论对比图',fontsize=20)
plt.ticklabel_format(axis='y',style='plain',useOffset=False,useLocale=False)
##画图
plot1=ax1.plot(df1['date'],df1['accrued_income_iPhone'],color='b',label='iphone端预计营收(美元)')
ax1.set_ylabel('收入',fontsize=20)
for tl in ax1.get_yticklabels():
tl.set_color('b')
ax2=ax1.twinx()
plot2=ax2.plot(df2['date'],df2['comment_bilibili'],color='r',label='评论数')
ax2.set_ylabel('评论数',fontsize=20)
for tl in ax2.get_yticklabels():
tl.set_color('g')
lines = plot1 + plot2
ax1.legend(lines, [l.get_label() for l in lines])
plt.show()
![]()
##载入文件
file_path4='./20200806_bilibili.csv'
##文件调整
#昵称,uid,等级,
df4=pd.read_csv(file_path4,header=None,names=['name','uid','level','comment','like','time'],lineterminator="\n",low_memory=False, error_bad_lines=False)
df4.to_csv('tf.csv',index=False)
df4['level'].replace(np.nan, 0, inplace=True)
df4['level'].replace(np.inf, 0, inplace=True)
df4['uid'].replace(np.nan, 0, inplace=True)
df4['uid'].replace(np.inf, 0, inplace=True)
df4['like'].replace(np.nan, 0, inplace=True)
df4['like'].replace(np.inf, 0, inplace=True)
df4['uid']=df4['uid'].astype('int')
df4['level']=df4['level'].astype('int')
print(df4)
print(df4.info())
name uid level comment like \
0 \tSuper丶过 84018702 6 啊啊啊啊啊啊啊啊啊啊啊啊蒂蒂时装!!!! 14659
1 \t要考深大的Dancy 76813331 5 找了好久,捞不动啊,头子[doge] 473
2 \t417508306 417508306 4 顶,你可是带功臣 374
3 \t月习Z24 339794357 5 捞不动啊[doge] 76
4 \t十-星尘 386262987 5 愿望实现了是吧[doge] 85
... ... ... ... ... ...
354026 \t山巘之竹 23862202 5 近卫方舟 0
354027 \t不懂浪漫的锐萌萌 41941359 5 90发没有出黑[笑哭] 0
354028 \t香蕉丨君 12671223 6 蒂蒂 0
354029 \t西风眠 631159 5 斯卡蒂泳装!! 0
354030 \t爱次砂糖桔 364668474 5 斯卡蒂! 0
time
0 2020-08-0610:33:59\r
1 2020-08-0610:51:30\r
2 2020-08-0610:51:32\r
3 2020-08-0610:51:58\r
4 2020-08-0610:52:32\r
... ...
354026 2020-08-0610:32:44\r
354027 2020-08-0610:32:44\r
354028 2020-08-0610:32:43\r
354029 2020-08-0610:32:43\r
354030 2020-08-0610:32:43
[354031 rows x 6 columns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 354031 entries, 0 to 354030
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 354030 non-null object
1 uid 354031 non-null int32
2 level 354031 non-null int32
3 comment 354030 non-null object
4 like 354031 non-null int64
5 time 354031 non-null object
dtypes: int32(2), int64(1), object(3)
memory usage: 13.5+ MB
None
##分析弹幕和发帖数
count_user_id=df4['uid'].unique()
print('总发帖数为:',len(df4['comment']))
print('参与发帖的用户数为:',len(count_user_id))
总发帖数为: 354031
参与发帖的用户数为: 32259
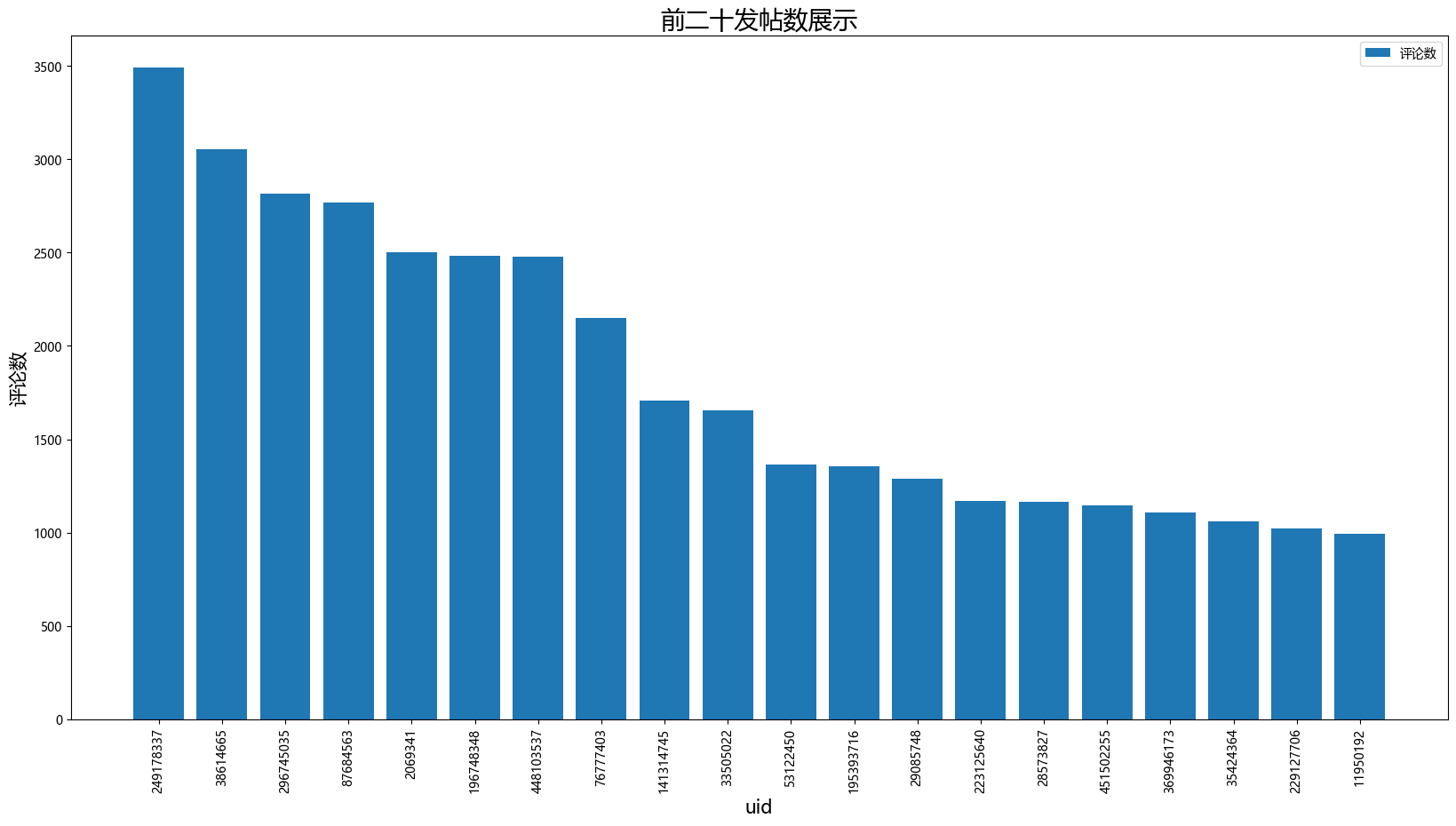
##前二十为发帖数展示
data1=df4.groupby(['uid']).count()
data1=data1.sort_values(by=['comment'],ascending=[False]).head(20)
data1['uid']=data1.index.astype('str')
print(data1)
plt.figure(figsize=(20,10))
plt.xticks(rotation=90)
plt.xlabel('uid',fontsize=15)
plt.ylabel('评论数',fontsize=15)
plt.title('前二十发帖数展示',fontsize=20)
plt.ticklabel_format(axis='y',style='plain',useOffset=False,useLocale=False)
plt.bar(data1['uid'],data1['comment'],label='评论数')
plt.legend(loc='upper right')
plt.show()
name level comment like time uid
uid
249178337 3491 3491 3491 3491 3491 249178337
38614665 3052 3052 3052 3052 3052 38614665
296745035 2814 2814 2814 2814 2814 296745035
87684563 2768 2768 2768 2768 2768 87684563
2069341 2502 2502 2502 2502 2502 2069341
196748348 2481 2481 2481 2481 2481 196748348
448103537 2477 2477 2477 2477 2477 448103537
76777403 2150 2150 2150 2150 2150 76777403
141314745 1707 1707 1707 1707 1707 141314745
33505022 1654 1654 1654 1654 1654 33505022
53122450 1364 1364 1364 1364 1364 53122450
195393716 1355 1355 1355 1355 1355 195393716
29085748 1287 1287 1287 1287 1287 29085748
223125640 1167 1167 1167 1167 1167 223125640
28573827 1166 1166 1166 1166 1166 28573827
451502255 1144 1144 1144 1144 1144 451502255
369946173 1106 1106 1106 1106 1106 369946173
35424364 1061 1061 1061 1061 1061 35424364
229127706 1022 1022 1022 1022 1022 229127706
11950192 995 995 995 995 995 11950192
![]()
#用户发帖分析
def suma(i):
data2=df4.groupby(['uid']).count()
data2=data2.sort_values(by=['comment'],ascending=[False]).head(i)
a=data2['comment'].sum()
print(a)
suma(0)
suma(8074)
suma(16149)
suma(24223)
0
313274
335202
345995
##词云分析
def wordcloudp(i):
data2=df4.groupby(['uid']).count() #按照uid分类
data2=data2.sort_values(by=['comment'],ascending=[False]).head(i) #排序
data2['uid']=data2.index.astype('str')
b=data2['uid'].astype('int')
c=df4.loc[~df4['uid'].isin(b)]
print(len(c))
data3=c['comment'].tolist()
data3=str(data3)
ls=jieba.lcut(data3)
txt="".join(ls)
STOPWORDS.update(['doge','微笑','OK','星星眼','妙啊','调皮','歪嘴','打call','呲牙','滑稽','吃瓜',
'辣眼睛','嗑瓜子','笑哭','脱单doge','给心心','嘟嘟','喜欢','酸了','奸笑','喜极而泣','疑惑','害羞','大哭',
'嫌弃','哦呼','笑','偷笑','惊讶','捂脸','阴险','囧','呆','尴尬','鼓掌','点赞','无语','惊喜','大笑','抠鼻',
'灵魂出窍','委屈','傲娇','疼','冷','生病','吓','哈欠','翻白眼','再见','思考','嘘声','捂眼','吐','奋斗',
'墨镜','难过','撇嘴','抓狂','生气','口罩','热词系列_知识增加','2233娘_大笑','支持','热词系列_吹爆','妙啊',
'tv_doge','热词系列_大师球','热词系列_爱了爱了'])
mask = np.array(Image.open("./background01.jpg"))
comment_wc = WordCloud(
background_color='black',
mask=mask,
width=3000,
height=3000,
margin=1,
max_words=2000,
mode='RGBA',
color_func=lambda *args, **kwargs: "white",
stopwords=set(STOPWORDS),
font_path="msyh.ttc")
comment_wc.generate(txt)
plt.imshow(comment_wc)
plt.axis('off')
plt.show()
wordcloudp(0)
wordcloudp(8074)
wordcloudp(16149)
wordcloudp(24223)
![]()
##载入文件
file_path5='./20210416_bilibili.csv'
##文件调整
df5=pd.read_csv(file_path5,header=None,names=['name','uid','level','comment','like','time'],lineterminator="\n",low_memory=False, error_bad_lines=False)
df5.to_csv('tf.csv',index=False)
df5['level'].replace(np.nan, 0, inplace=True)
df5['level'].replace(np.inf, 0, inplace=True)
df5['uid'].replace(np.nan, 0, inplace=True)
df5['uid'].replace(np.inf, 0, inplace=True)
df5['uid']=df5['uid'].astype('int')
df5['level']=df5['level'].astype('int')
print(df5)
print(df5.info())
name uid level \
0 \t愿与六花再次相逢 8689126 6
1 \t巴别塔的菜鸡 481064550 4
2 \t愿与六花再次相逢 8689126 6
3 \t梦忆丶髅髅宫 14669819 6
4 \t巴别塔的菜鸡 481064550 4
... ... ... ...
32747 \t缇丶背 622589918 4
32748 \tcaduceus攻略组 281766906 5
32749 \t缇丶背 622589918 4
32750 \t-宅系の男生- 487524248 4
32751 \t芳泽霞--- 18687790 5
comment like \
0 鹰角啊。敌人描述别让它自己滚动了行不行啊。[灵魂出窍]看着太费劲了。 3401
1 嗯呢,看过内卫介绍看了好几遍没看懂,最后搜了一下发现锁输出最高的那个[喜极而泣] 193
2 而且优先攻击没在国度内的我方角色。 47
3 小火龙+赛爹 内卫没走过来就融化了 0
4 回复错人了吧 1
... ... ...
32747 又是你啊 0
32748 哟 方舟评论区常客啊 0
32749 你不也是常客吗[吃瓜]我方舟已经快毕业了怎么就不能来了 0
32750 那可是阴阳空格小号 0
32751 地生五金池,普通池不能给限定垫刀,复刻没奖励,锁定每周可得的合成玉上限,现在开始出强度一无是... 2
time
0 2021-04-1614:51:40\r
1 2021-04-1614:54:45\r
2 2021-04-1614:56:00\r
3 2021-04-1616:54:40\r
4 2021-04-1616:56:17\r
... ...
32747 2021-04-1911:55:47\r
32748 2021-04-1911:57:15\r
32749 2021-04-1912:01:30\r
32750 2021-04-1914:40:10\r
32751 2021-04-1715:16:33\r
[32752 rows x 6 columns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32752 entries, 0 to 32751
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 32752 non-null object
1 uid 32752 non-null int32
2 level 32752 non-null int32
3 comment 32752 non-null object
4 like 32752 non-null int64
5 time 32752 non-null object
dtypes: int32(2), int64(1), object(3)
memory usage: 1.2+ MB
None
##分析弹幕和发帖数
count_user_id=df5['uid'].unique()
print('总发帖数为:',len(df5['comment']))
print('参与发帖的用户数为:',len(count_user_id))
总发帖数为: 32752
参与发帖的用户数为: 8045
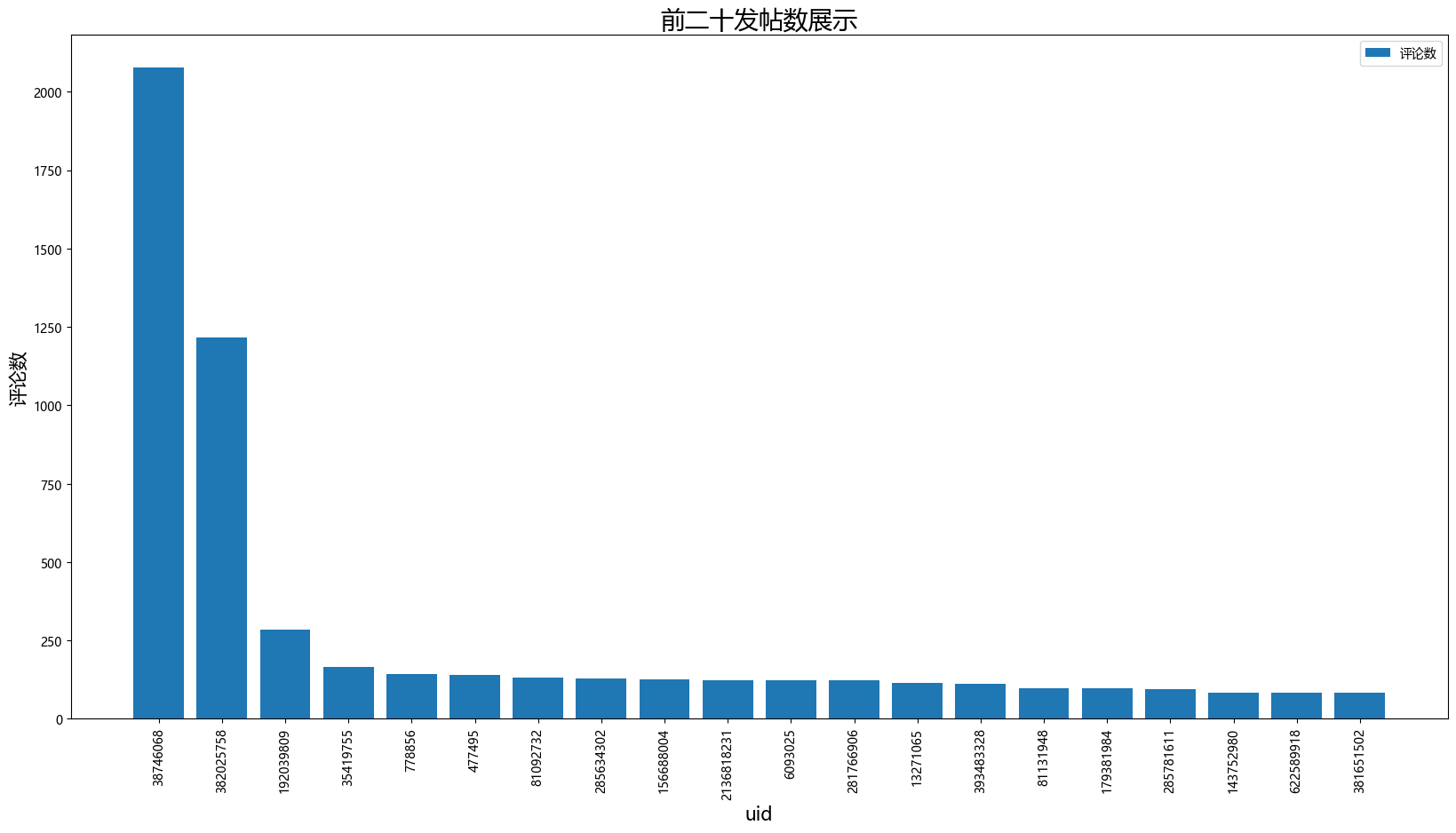
##前二十为发帖数展示
data4=df5.groupby(['uid']).count()
data4=data4.sort_values(by=['comment'],ascending=[False]).head(20)
data4['uid']=data4.index.astype('str')
print(data4)
plt.figure(figsize=(20,10))
plt.xticks(rotation=90)
plt.xlabel('uid',fontsize=15)
plt.ylabel('评论数',fontsize=15)
plt.title('前二十发帖数展示',fontsize=20)
plt.ticklabel_format(axis='y',style='plain',useOffset=False,useLocale=False)
plt.bar(data4['uid'],data4['comment'],label='评论数')
plt.legend(loc='upper right')
plt.show()
name level comment like time uid
uid
38746068 2077 2077 2077 2077 2077 38746068
382025758 1217 1217 1217 1217 1217 382025758
192039809 285 285 285 285 285 192039809
35419755 165 165 165 165 165 35419755
778856 143 143 143 143 143 778856
477495 141 141 141 141 141 477495
81092732 132 132 132 132 132 81092732
285634302 128 128 128 128 128 285634302
156688004 127 127 127 127 127 156688004
2136818231 122 122 122 122 122 2136818231
6093025 122 122 122 122 122 6093025
281766906 122 122 122 122 122 281766906
13271065 116 116 116 116 116 13271065
393483328 112 112 112 112 112 393483328
81131948 98 98 98 98 98 81131948
179381984 97 97 97 97 97 179381984
285781611 94 94 94 94 94 285781611
143752980 84 84 84 84 84 143752980
622589918 84 84 84 84 84 622589918
381651502 83 83 83 83 83 381651502
![]()
#用户发帖分析
def sumb(i):
data5=df5.groupby(['uid']).count()
data5=data5.sort_values(by=['comment'],ascending=[False]).head(i)
a=data5['comment'].sum()
print(a)
sumb(2015)
sumb(4030)
sumb(6045)
24253
28682
30752
##词云分析
def wordcloudq(i):
data6=df5.groupby(['uid']).count()
data6=data6.sort_values(by=['comment'],ascending=[False]).head(i)
data6['uid']=data6.index.astype('str')
b=data6['uid'].astype('int')
c=df5.loc[~df5['uid'].isin(b)]
print(len(c))
data7=c['comment'].tolist()
data7=str(data7)
ls=jieba.lcut(data7)
txt="".join(ls)
STOPWORDS.update(['doge','微笑','OK','星星眼','妙啊','调皮','歪嘴','打call','呲牙','滑稽','吃瓜',
'辣眼睛','嗑瓜子','笑哭','脱单doge','给心心','嘟嘟','喜欢','酸了','奸笑','喜极而泣','疑惑','害羞','大哭',
'嫌弃','哦呼','笑','偷笑','惊讶','捂脸','阴险','囧','呆','尴尬','鼓掌','点赞','无语','惊喜','大笑','抠鼻',
'灵魂出窍','委屈','傲娇','疼','冷','生病','吓','哈欠','翻白眼','再见','思考','嘘声','捂眼','吐','奋斗',
'墨镜','难过','撇嘴','抓狂','生气','口罩'])
mask = np.array(Image.open("./background01.jpg"))
comment_wc = WordCloud(
background_color='black',
mask=mask,
#width=400,
#height=200,
#margin=1,
max_words=200,
mode='RGBA',
color_func=lambda *args, **kwargs: "white",
stopwords=set(STOPWORDS),
font_path="msyh.ttc")
comment_wc.generate(txt)
plt.imshow(comment_wc)
plt.axis('off')
plt.show()
wordcloudq(0)
wordcloudq(2015)
wordcloudq(4030)
wordcloudq(6045)











 浙公网安备 33010602011771号
浙公网安备 33010602011771号