Python 第三方库Knn算法
一、Knn第三方库参数及涉及的函数参数介绍(亦可见刘建平老师的博客:https://www.cnblogs.com/pinard/p/6065607.html)
(1)neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1)
- n_neighbors:用于指定近邻样本个数K,默认为5
- weights:用于指定近邻样本的投票权重,默认为'uniform',表示所有近邻样本的投票权重一样;如果为'distance',则表示投票权重与距离成反比,即近邻样本与未知类别的样本点距离越远,权重越小,反之,权重越大
- algorithm:用于指定近邻样本的搜寻算法,如果为'ball_tree',则表示使用球树搜寻法寻找近邻样本;如果为'kd_tree',则表示使用KD树搜寻法寻找近邻样本;如果为'brute',则表示使用暴力搜寻法寻找近邻样本。默认为'auto',表示KNN算法会根据数据特征自动选择最佳的搜寻算法
- leaf_size:用于指定球树或KD树叶子节点所包含的最小样本量,它用于控制树的生长条件,会影响树的查询速度,默认为30
- metric:用于指定距离的度量指标,默认为闵可夫斯基距离
- p:当参数metric为闵可夫斯基距离时,p=1,表示计算点之间的曼哈顿距离;p=2,表示计算点之间的欧氏距离;该参数的默认值为2
- metric_params:为metric参数所对应的距离指标添加关键字参数
- n_jobs:用于设置KNN算法并行计算所需的CPU数量,默认为1表示仅使用1个CPU运行算法,即不使用并行运算功能
官方链接:https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
(2)sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=’warn’, n_jobs=None, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’, error_score=’raise-deprecating’)[source]¶
- estimator:训练模型函数
- X:用于该模型训练的特征值
- y:用于该模型训练的标签值
- cv:交叉验证迭代的次数
- n_jobs:用于设置交叉验证算法并行计算所需的CPU数量,默认为1表示仅使用1个CPU运行算法,即不使用并行运算功能
官方链接:https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html
(3)train_test_split(test_size,train_size,random_state,shuffle ,stratify)
- test_size:为int数值时,表示选取样本数量,为浮点型时,便是百分比。
- train_size:与test_size参数差不多
- random_state:随机生成树的种子,与np.random.random(12)相仿
- shuffle :是否进行洗牌操作
- stratify:如果shuffle 为None,则进行分层标签
官方链接: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
二、Knn算法实战(知识接收水平判别)
(1)实验步骤
- 加载数据并划分为训练集和测试集
- 交叉验证选取最优K值
- 将不同K值的得分进行可视化(可选)
- 将最优K值进行模型训练及混淆矩阵可视化
- 模型整体准确率及报告输出
(2)代码实现
- 选取最优K值
1 def data_set(): 2 """ 3 加载数据并构造训练集和测试集为模型准备 4 """ 5 #导入第三方库 6 import pandas as pd 7 from sklearn import model_selection 8 # 导入数据 9 Knowledge = pd.read_excel(r'Knowledge.xlsx') 10 # 将数据集拆分为训练集和测试集 11 predictors = Knowledge.columns[:-1] #提取特征名 12 X_train, X_test, y_train, y_test = model_selection.train_test_split(Knowledge[predictors], Knowledge.UNS, 13 test_size = 0.25, random_state = 1234) 14 return X_train, X_test, y_train, y_test
1 def choose_bestK(X_train,y_train): 2 """选取K值最优解""" 3 #导入第三方库 4 import numpy as np 5 from sklearn import neighbors 6 from sklearn import model_selection 7 8 #设置K值最大值 9 K = np.arange(1,np.ceil(np.log2(Knowledge.shape[0]))) 10 #构建空列表用于存储平均准确率 11 accureccy = [] 12 for k in K: 13 # 使用10重交叉验证的方法,比对每一个k值下KNN模型的预测准确率 14 cv_result = model_selection.cross_val_score(neighbors.KNeighborsClassifier(n_neighbors=int(k),weights='distance'), 15 X_train, y_train, cv = 10, scoring='accuracy') 16 accureccy.append(cv_result.mean()) 17 arg_maxK = np.array(accureccy).argmax() 18 return K,accureccy,arg_maxK
1 def visual(K,accureccy,arg_maxK): 2 """对不同K值得分进行可视化""" 3 #导入第三方库 4 import matplotlib.pyplot as plt 5 6 # 中文和负号的正常显示 7 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] 8 plt.rcParams['axes.unicode_minus'] = False 9 10 plt.plot(K,accureccy) 11 plt.scatter(K,accureccy) 12 plt.text(K[arg_max], accuracy[arg_max], '最佳k值为%s' %int(K[arg_max])) 13 # 显示图形 14 plt.show()
1 if __name__=='__main__': 2 """代码测试""" 3 X_train, X_test, y_train, y_test=data_set() 4 K,accureccy,arg_maxK = choose_bestK(X_train,y_train) 5 visual(K,accureccy,arg_maxK)
结果:
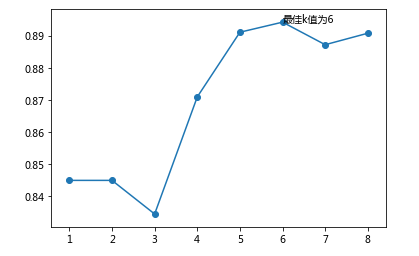
- 模型训练并用混淆矩阵可视化
1 def Model_train_predict(K,X_train, y_train,X_test): 2 """模型训练及预测""" 3 #导入第三方库 4 from sklearn import neighbors 5 6 # 重新构建模型,并将最佳的近邻个数设置为6 7 knn_class = neighbors.KNeighborsClassifier(n_neighbors = K, weights = 'distance') 8 # 模型拟合 9 knn_class.fit(X_train, y_train) 10 # 模型在测试数据集上的预测 11 predict = knn_class.predict(X_test) 12 # 构建混淆矩阵 13 cm = pd.crosstab(predict,y_test) 14 return cm,predict
1 def Confusion_matrix_hp(cm): 2 """构造混淆矩阵热度图""" 3 #导入第三方库 4 from sklearn import metrics 5 import seaborn as sns 6 7 # 将混淆矩阵构造成数据框,并加上字段名和行名称,用于行或列的含义说明 8 cm = pd.DataFrame(cm) 9 # 绘制热力图 10 sns.heatmap(cm, annot = True,cmap = 'GnBu') 11 # 添加x轴和y轴的标签 12 plt.xlabel(' Real Lable') 13 plt.ylabel(' Predict Lable') 14 # 图形显示 15 plt.show()
1 if __name__=='__main__': 2 """代码测试""" 3 X_train, X_test, y_train, y_test=data_set() 4 K,accureccy,arg_maxK = choose_bestK(X_train,y_train) 5 cm,predict = Model_train_predict(K,X_train, y_train,X_test,y_test) 6 Confusion_matrix_hp(cm)
结果:
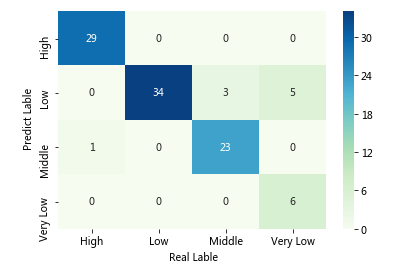
- 模型整体准确率及报告输出
1 def score_report(y_test,predict): 2 """模型准确率及报告输出""" 3 # 导入第三方模块 4 from sklearn impmetricsrics 5 6 # 模型整体的预测准确率 7 total_score=metrics.scorer.accuracy_score(y_test, predict) 8 # 分类模型的评估报告 9 report = metrics.classification_report(y_test, predict) 10 return total_score,report
1 if __name__=='__main__': 2 3 """代码测试""" 4 X_train, X_test, y_train, y_test=data_set() 5 K,accureccy,arg_maxK = choose_bestK(X_train,y_train) 6 cm,predict = Model_train_predict(K,X_train, y_train,X_test,y_test) 7 total_score,report = score_report(y_test,predict) 8 print(total_score,"\n",report)
结果:
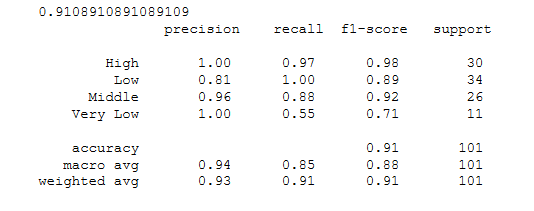
借鉴:《从零开始学Python数据分析与挖掘》 PPT


 浙公网安备 33010602011771号
浙公网安备 33010602011771号