扩散模型Difussion
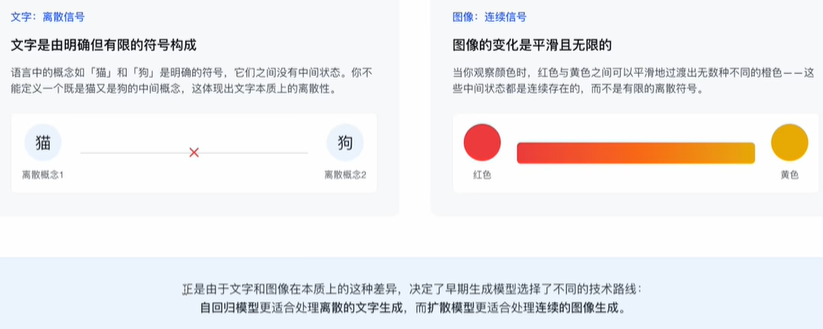
图像从现实到数字文件需要通过采样和量化;文字是简化版的世界。
这样看自回归模型适合用于工程制图,因为它准确,不需要美感(起码大部分不需要),而且对分辨率要求不高(因为复杂组件可以分子图)。理论上无论是扩散还是自回归都可以生成相同的概率分布。确实可以理解为,拟合相同数据分布的两种不同方式。但是要考虑到工程实现问题,由于现在的模型比较缺乏可解释性,我们常常会使用归纳偏置增强模型的表现,这个不同的框架就会有很大的差异。所以在工程实现上,难度是截然不同的。
自回归模型可以用扩散模型再加一层优化,结合两者优点。
当我们用扩散模型去生成图片(e.g. 城堡 大部分是金屋顶 厚城墙 特征的概率高。)的时候,其实是在让图像中的特征尽可能的向现实世界中的,你想生成/表达的概念物体(e.g. 城堡)的高概率区域去靠近/靠拢。城堡一般是尖屋顶 厚城墙。那么用扩散模型生成城堡图片时,在连续的空间中,不断的把金屋顶画得很尖、画的像屋顶,同时不断的把城墙的质地增加,让其看起来很厚。最终由于这些特征不断的被强化,所以,就会使得画出来的城堡想一个真的城堡。所以,扩散模型就是找一种概率分布,找的是一种从模糊草图,到细节逐渐清晰的一个过程。这个过程和人类去绘画的思路是基本吻合的。所以扩散模型天然的适合图像生成的任务。
当我们用扩散模型生成城堡图片时,虽然我们有金屋顶、厚城墙这种明显典型特征的预设,但是由于图像信号本身是连续的信号,所以 我们提取到的特征自然也是连续的信号,这种连续的特征使得很难明确 哪些维度对应金屋顶、哪些维度对应生成厚城墙。因为整个过程中特征是没有明确的边界的。
扩散模型生成图的过程是很直观的,但是很难判断 每个具体的特征 或多个维度特征的组合,表达的到底是怎么样的含义。扩散模型学习这些特征的时候 学到的是整体的、抽象的、很难用语言表达的感觉/范式/概念。
扩散模型学习到的是一种更加整体、抽象的感觉,就像人第一次看到宏伟的城堡时不会具体分析每个细节 而是直观地感受到那种整体的美感或直觉。这种连续的特性让扩散模型能够创造出令人惊艳的作品。因为审美本身很难用某个边界来表述、和明确的边界来定义。依靠的是大量的特征相互融合、交织和作用,使得人们感受到这是一种美的概念。这也是为何有时扩散模型能生成一些让人们感觉到很惊艳的作品。

人们在使用,自回归类模型和扩散模型,分别生成文字和图像的时候,其实,是符合人类自身使用文字和绘制图像的思路思维方式的。这背后有一种仿生学的概念,也即,人类如何做,我就让模型如何做。虽然有着方案和技术路线的差异,但是都是相对来说解决对应问题的最短路径。

图片是连续的,而自回归擅长处理离散的信号,那我们如何让自回归模型生成或处理图片,可以加一个模块,做转换。先把图片的连续信号转为离散信号后,再用自回归模型进行处理。e.g. 上图中的VQ Tokenizer
自回归模型通过VQ Tokenizer明确实现了连续特征到离散特征的转换,构建一个称为Codebook(码本)的离散特征集合,将原本连续的视觉特征映射到这个有限集合中。e.g. 城堡图片经过VQ Tokenizer之后,就会变成城堡的轮廓是什么样的、透视关系是什么样的、城堡的纹理是什么样的?城堡上面有什么?(塔尖)等,通过这样的方式把原本难以表达的隐式的连续的特征,转换为了更加明确、可控的显式的特征。虽然codebook中的特征维度不是人直接去定义的,比如尖屋顶、厚城墙 特征,但是相比于扩散模型而言,我们能够通过codebok来更清晰的理解图像的生成过程。基于此,我们可以猜想为何gemeni和GROK3在图像生成任务上比扩散模型要强。既然每一个维度都可以清洗的解释,当我们想明确的,把城堡的尖屋顶改为圆屋顶的时候,我们只需要针对那个特征维度的区域进行修改即可,而不用担心这种修改会影响图像其他部位。
网友:可是SD也用了类似于VQVAE的编解码结构构建隐空间。sd用的是vae不是vqvae。
但也有劣势,如下图所示:

劣势:如何保证codebook的训练过程和优化是足够准确的?只有这个模块不出错,才有可能生成更高质量的内容;此外,当把无限的信号映射到有限的离散特征之中,肯定会有信息损失,尤其是在复杂精细的场景中;连续的特征能更好的表达美学、直觉等类似抽象的概念;当这些连续的信号被强行离散化之后,很可能会 造成细节、整体美感等方面的质量下降。所以自回归模型很可能在高度复杂的图像生成任务上遇到瓶颈;毕竟有些美 难以用语言等显式的方式来精准表述/描述;
网友:自回归生成主要描述,或者叫做框架,扩散精细化。有点儿隐空间的意思,编辑在隐空间内完成(框架),扩散补全细节。
前半部分讲的很好,但后面讲到的VQ并不是很认同。VQ是帮助理解图像而不是生成图像的,类似的,人在理解图像时也是离散的。vq的encoder是理解图像,decoder是生成图像,一般来说要提升自回归llm的生成效果可以训完vq再精调一下decoder部分。
自回归模型与扩散模型各有适用领域,甚至联合使用也是一个很好的思路。是说vae的decoder吧,VQ我理解只是量化的步骤。一般是vqvae不是单独一个vq。去看下vqgan那片论文就清楚了。自回归模型可以用扩散模型再加一层优化,结合两者优点。这样看自回归模型适合用于工程制图,因为它准确,不需要美感(起码大部分不需要),而且对分辨率要求不高(因为复杂组件可以分子图)。理论上无论是扩散还是自回归都可以生成相同的概率分布。确实可以理解为,拟合相同数据分布的两种不同方式。但是要考虑到工程实现问题,由于现在的模型比较缺乏可解释性,我们常常会使用归纳偏置增强模型的表现,这个不同的框架就会有很大的差异。所以在工程实现上,难度是截然不同的。
讨论谁会取代谁其实意义不大。
当我们真正理解一项技术背后的原理和它的发展脉络时,我们才能在时代的浪潮中精准地选择最适合自己产品的技术方案,真正做出属于自己的判断。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号