C语言解析WAV音频文件
C语言解析WAV音频文件
代码地址: Github : https://github.com/CasterWx/c-wave-master
目录
在计算机中有着各式各样的文件,比如说EXE这种可执行文件,JPG这种图片文件,也有我们平时看的TXT,或者C,CPP,PHP等代码文件。
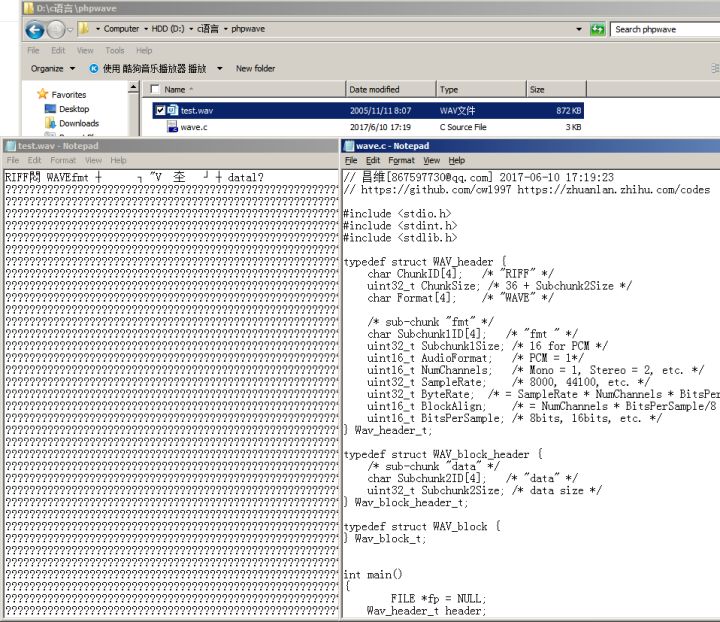
如果把这些文件用记事本或者其他纯文本编辑器打开,会发现前面这类文件打开之后基本上都是乱码,也就是非人类可读的字符,而后面这类代码或者TXT文件打开之后都是人类可读的字符串。
如果我们把这些文件统一做一个分类,那么前面的EXE,JPG之类的这种打开之后都是我们看不懂的外星球文字的文件叫做二进制文件,而后面那些文件可以称为是文本文件。
后面那种分类是文本文件很好理解,毕竟都是我们认识的文本文字,但是前面的那些乱码为什么叫他二进制文件呢?这些二进制文件是怎么被计算机识别的,为什么这些乱码就能被计算机识别,并且放出悠扬动听的音乐或者栩栩如生的图片呢?我们学编程,搞计算机的人能不能也自己写一个程序把这些数据解析出来呢?请跟听本专栏栏猪一起慢慢道来。
前言
我们将一步一步来了解C语言的一些基本库的使用,以及如何使用这些库来解析一个wav格式的音频文件,将其中的元数据(也就是该音频文件的一些属性)提取出来。因此您需要有基本的计算机基础知识以及了解C语言,最好还对音频或者信号处理感兴趣。
了解WAV音频文件
下面是百度百科的解释
WAV为微软公司(Microsoft)开发的一种声音文件格式,它符合RIFF(Resource Interchange File Format)文件规范,用于保存Windows平台的音频信息资源,被Windows平台及其应用程序所广泛支持,该格式也支持MSADPCM,CCITT A LAW等多种压缩运算法,支持多种音频数字,取样频率和声道,标准格式化的WAV文件和CD格式一样,也是44.1K的取样频率,16位量化数字,因此在声音文件质量和CD相差无几! WAV打开工具是WINDOWS的媒体播放器。
通常使用三个参数来表示声音,量化位数,取样频率和采样点振幅。量化位数分为8位,16位,24位三种,声道有单声道和立体声之分,单声道振幅数据为n1矩阵点,立体声为n2矩阵点,取样频率一般有11025Hz(11kHz) ,22050Hz(22kHz)和44100Hz(44kHz) 三种,不过尽管音质出色,但在压缩后的文件体积过大!相对其他音频格式而言是一个缺点,其文件大小的计算方式为:WAV格式文件所占容量(B) = (取样频率 X量化位数X 声道) X 时间 / 8 (字节= 8bit) 每一分钟WAV格式的音频文件的大小为10MB,其大小不随音量大小及清晰度的变化而变化。
我们通常在各种音乐播放器中下载歌曲的时候会看到各种参数,比如说普通音质的码流为128k,高品质是320k,还有无损的APE,FLAC等格式。还有的时候我们在使用各种音频格式转换工具中会遇到各种参数,比如说采样率,量化精度,以及该音频文件是单声道还是双声道等等。
我们现在都是听MP3格式的音乐,WAV现在除了Windows的录音机以外,基本上没有地方会用了,为什么还要用他来做示例呢?这是因为WAV本质上是无压缩的原始音频文件,而且他的文件结构不算非常复杂,因此可以作为我们初学者的学习示例格式。你可以按照同样的思路自己去学习其他格式。
什么是二进制文件
二进制文件,本质上就是一种使用二进制方式存储文件内容的文件统称,我们前面有讲过使用记事本等工具打开之后看到的是乱码,那么我们怎么分析他呢,可以使用UltraEditor,HxD,C32Asm等等。比如我这里使用HxD打开Windows 7的关机音乐(C:\Windows\Media\Windows Shutdown.wav)就是这个样子,左边就是这个WAV音频文件的二进制表示,右边则是这个二进制数字对应的ASCII表示,由于像00之类的数字在ASCII中并没有有效的图像来显示,所以在这个界面的右边显示的就是一个点。而左边这些52,49之类的数字分别对应什么呢?其实这些二进制数字看似乱码,其实都是有一定的规范的,只要我们或者我们计算机上面的应用程序了解这个规范,就可以按照这个规范去解读它。
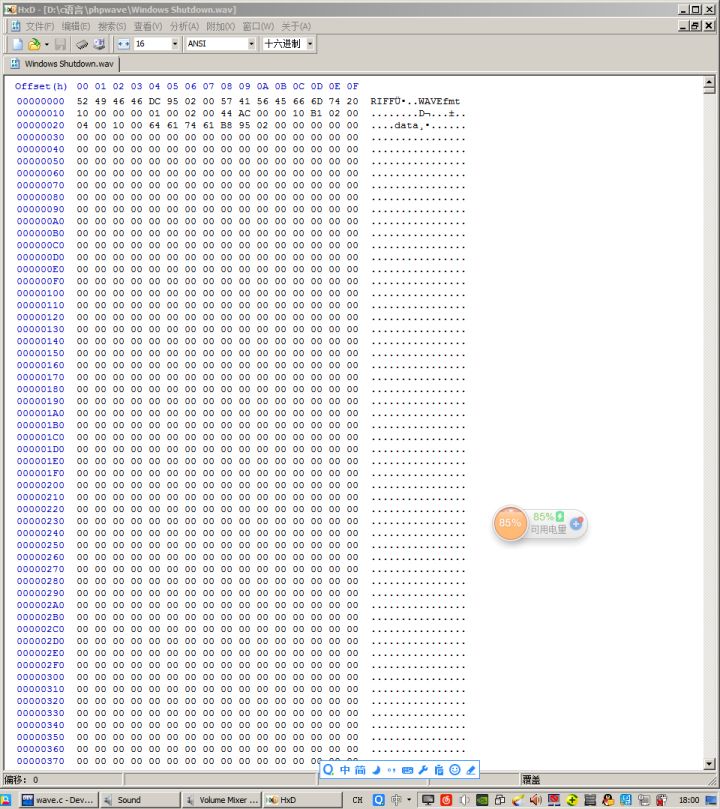
WAV的二进制格式解析
根据网络上的各种资料可以得知WAVE文件本质上就是一种RIFF格式,它可以抽象成一颗树(数据结构的一种)来看。

我们看到这张图上面,从上到下分别对应着二进制数据在文件中相对于起始位置的偏移量。每一个格子对应一个字段,field size表示每个字段所占据的大小,根据这个大小以及当前的偏移量,我们也可以计算出下一个字段的起始地址(偏移量)。
接下来我们来解释一下上面每个字段的含义。根据RIFF的规范,整个WAV文件的顶级chunk就是最顶上的ChunkID为RIFF的这个chunk,这也可以解释为什么之前那张图片中我们可以看出wav文件开头都是RIFF几个字母。而接下来的ChunkSize则表示这个chunk下的那些子chunk的大小,如果按照“树结构”来理解,那么每一个子chunk(Subchunk)则为树的树枝。而Format则为这个chunk的实际数据。
说白了一个chunk结构其实就是三个部分,第一个部分标识符用于说明这个chunk是存什么内容的,第二个部分则是说明这个chunk的内容到底有多大,用于让程序知道如果要找到下一个chunk该把地址偏移多少去读取,而第三个部分则是实际内容。
好了说完了顶级chunk,我们就来看看子chunk,第一个子chunk的Subchunk1ID在WAV文件中恒定为fmt,表示该subchunk的内容为该WAV音频文件的一些元数据,也就是该WAV音频的一些格式信息。比如说AudioFormat这个字段一般为1,表示这个WAV音频为PCM编码。NumChannels则是该WAV音频文件的声道数量。SampleRate则为采样率,ByteRate则为采样率。BlockAlign则是每个block的平均大小,它等于NumChannels * BitsPerSample/8,至于block是什么,以及它的计算公式是怎么得来的需要来看看另一个Subchunk。BitsPerSample则为每秒采样比特,有的地方称它为量化精度或者PCM位宽。(未考究)
另一个子chunk也就是Subchunk2ID是在WAV文件中恒定为data,也就是这个WAV音频文件的实际音频数据,说专业一点,这里面存储的是音频的采样数据。但是我们的音频如果是双声道,那么实际上某一个采样时刻采样的数据是由左声道和右声道共同组成的。而这个共同组成的采样我们把他成为block。前面有讲到BlockAlign = NumChannels * BitsPerSample / 8,这个现在就很好理解了,至于为什么末尾要除以8,这是因为计算机中是以8个二进制数表示一个字节,所以要除以8来求出字节数。
至于音频的持续长度,我们可以通过Subchunk2Size除以ByteRate,也就是实际音频data的chunk总长度除以每秒字节数得到持续多少秒。
C语言解析WAV音频文件
前面讲了这么多,现在问题来了,怎么编程来实现解析上面所说的这些元数据呢。C语言基本的二进制文件操作函数有fopen,fread等等。(注意是二进制文件操作函数,所以我们不讨论fgets,这是普通的文本文件操作函数)
fread是一个函数。从一个文件流中读数据,最多读取count个项,每个项size个字节,如果调用成功返回实际读取到的项个数(小于或等于count),如果不成功或读到文件末尾返回 0。
它的函数原型为
size_t fread ( void *buffer, size_t size, size_t count, FILE *stream) ;
而且C语言还有一种类型叫做结构体,它在内存中是顺序存储的。刚好我们也已经得知了WAV文件在文件中的顺序以及该顺序中每个部分对应的含义,那么我们可以事先根据前面所说的WAV文件结构来定义好一个struct,然后在main主函数中初始化这个struct,并且通过fread的第一个参数带入初始化好的这个struct,那么执行之后就会自动读取该文件,并且按照顺序自动把这些元数据填充进了我们初始化好的struct中。我们便可以直接从struct中取到这些元数据了。
代码如下:
wave.c
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include "wave.h"
int main()
{
FILE *fp = NULL;
Wav wav;
RIFF_t riff;
FMT_t fmt;
Data_t data;
fp = fopen("test.wav", "rb");
if (!fp) {
printf("can't open audio file\n");
exit(1);
}
fread(&wav, 1, sizeof(wav), fp);
riff = wav.riff;
fmt = wav.fmt;
data = wav.data;
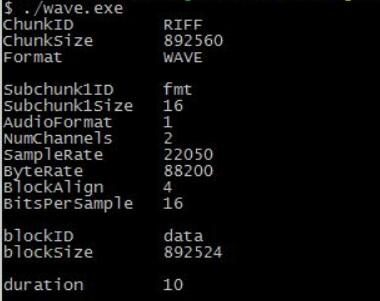
printf("ChunkID \t%c%c%c%c\n", riff.ChunkID[0], riff.ChunkID[1], riff.ChunkID[2], riff.ChunkID[3]);
printf("ChunkSize \t%d\n", riff.ChunkSize);
printf("Format \t\t%c%c%c%c\n", riff.Format[0], riff.Format[1], riff.Format[2], riff.Format[3]);
printf("\n");
printf("Subchunk1ID \t%c%c%c%c\n", fmt.Subchunk1ID[0], fmt.Subchunk1ID[1], fmt.Subchunk1ID[2], fmt.Subchunk1ID[3]);
printf("Subchunk1Size \t%d\n", fmt.Subchunk1Size);
printf("AudioFormat \t%d\n", fmt.AudioFormat);
printf("NumChannels \t%d\n", fmt.NumChannels);
printf("SampleRate \t%d\n", fmt.SampleRate);
printf("ByteRate \t%d\n", fmt.ByteRate);
printf("BlockAlign \t%d\n", fmt.BlockAlign);
printf("BitsPerSample \t%d\n", fmt.BitsPerSample);
printf("\n");
printf("blockID \t%c%c%c%c\n", data.Subchunk2ID[0], data.Subchunk2ID[1], data.Subchunk2ID[2], data.Subchunk2ID[3]);
printf("blockSize \t%d\n", data.Subchunk2Size);
printf("\n");
printf("duration \t%d\n", data.Subchunk2Size / fmt.ByteRate);
}
wave.h
typedef struct WAV_RIFF {
/* chunk "riff" */
char ChunkID[4]; /* "RIFF" */
/* sub-chunk-size */
uint32_t ChunkSize; /* 36 + Subchunk2Size */
/* sub-chunk-data */
char Format[4]; /* "WAVE" */
} RIFF_t;
typedef struct WAV_FMT {
/* sub-chunk "fmt" */
char Subchunk1ID[4]; /* "fmt " */
/* sub-chunk-size */
uint32_t Subchunk1Size; /* 16 for PCM */
/* sub-chunk-data */
uint16_t AudioFormat; /* PCM = 1*/
uint16_t NumChannels; /* Mono = 1, Stereo = 2, etc. */
uint32_t SampleRate; /* 8000, 44100, etc. */
uint32_t ByteRate; /* = SampleRate * NumChannels * BitsPerSample/8 */
uint16_t BlockAlign; /* = NumChannels * BitsPerSample/8 */
uint16_t BitsPerSample; /* 8bits, 16bits, etc. */
} FMT_t;
typedef struct WAV_data {
/* sub-chunk "data" */
char Subchunk2ID[4]; /* "data" */
/* sub-chunk-size */
uint32_t Subchunk2Size; /* data size */
/* sub-chunk-data */
// Data_block_t block;
} Data_t;
//typedef struct WAV_data_block {
//} Data_block_t;
typedef struct WAV_fotmat {
RIFF_t riff;
FMT_t fmt;
Data_t data;
} Wav;
执行结果
两个细节
1、fopen的时候我们的mode要设置为"rb",r表示read,b表示binary,也就是二进制读取方式。这一点是和读取传统的文本文件格式有所区别的。
2、struct类型里面我用的是uint32_t等类型,而不是传统的int,short等等,这是为了考虑到不同的编译器,不同的平台下对于int类型分配的内存空间不一致的问题。而这些类型是由stdint.h头文件提供的,因此我们需要在头部导入它。
总结
其实任何二进制数据都是有着属于它自己的解析规范,这就有点像我们学计算机网络的时候所说的“协议”,只要我们遵循这个规范或者“协议”,那么我们就可以将该文件真正隐含的信息读取出来。
我们这里仅仅是读取了一段WAV音频文件的元数据,没有把它的data chunk,也就是实际音频的数字信号读取出来,因为这涉及到数模信号的转换等知识,超出了我们的研究范围,
作者: AntzUhl
首发地址博客园:http://www.cnblogs.com/LexMoon/
代码均可在Github上找到(求Star) : Github
个人博客 : http://antzuhl.cn/
公众号 |
 |
赞助
支付宝 |
微信 |
 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号