【RocketMQ源码分析】深入消息存储(3)
前文回顾
CommitLog篇 ——【RocketMQ源码分析】深入消息存储(1)
ConsumeQueue篇 ——【RocketMQ源码分析】深入消息存储(2)
前面两篇已经说过了消息如何存储到CommitLog,以及ConsumeQueue的构建流程,到了第三篇,我们有一个不得不跨过的坎儿,MappedFile —— 内存文件映射。
MappedFile的存在是RocketMQ选择将消息直接存储到磁盘的关键因素,在第一篇CommitLog存储流程开篇中,我就写过一个思路。

- 即用到内存又用到本地磁盘
- 填充和交换
- 文件映射到内存
- 随机读接口去访问
这里出现的几个关键句,都离不开本篇要说的MappedFile。
RocketMQ既然要去与磁盘交互存储文件,不同IO方法在性能差距上都是千差万别的,怎么高效的与磁盘/内存进行交互,是很多涉及存储的中间件强大与否的重要标志。
这是几年前天池中间件大赛的题目,目标就是设计一个利用有限内存、较多磁盘空间来实现一个消息队列,这样看其实思路在第一篇就已经说过了,重点是他要求这个队列支持聚合操作。

这让我想到ElasticSearch的聚合场景,如果要实现那么复杂的聚合功能,也太南了吧。
不过好在题目只是要求做指定时间段的消息加和,这无非就是维护一个消息存储的偏移量与时间的存储就好了。
为了深入了解内存文件映射,我们可以来读读它的源码,这里相对于CommitLog、ConsumeQueue更加底层,更多涉及的是IO、Buffer、PageCache等知识。
从页表谈到零拷贝
在我过去学习汇编语言的时候,有两个寻址相关的寄存器。
段寄存器、变址寄存器。
在8086的年代,地址总线是20位,但寄存器16位,寻址能力有限,为了保证1M的寻址能力,是将两个16位寄存器一起使用,以段基址和偏移地址的形式,达到1M寻址能力。
这个思想在操作系统保护模式下也是一样的,假如我们有一台32位操作系统,内存4GB。
我们来思考一下它的内存布局,内核空间和用户空间这是我们熟知的概念了,假如内存空间不做任何操作,按顺序性让我们去访问,首先一个大问题就是内存隔离,两个进程之间如何做到内存互不污染,这也引出了Java虚拟机内存分配的一个问题,分配之后的内存空间被垃圾回收器清理,剩下的空间大大小小可能不连续,后续一个需要占据大内存的对象可能无法存储,JVM可以选择回收-清理的方式保证没有碎片,这是因为有栈上的引用指向堆,一个大对象就算被移动也不用担心,但操作系统不同,如果想用类似JVM回收-清理的方式减少碎片内存,首先一个要面对的问题就是地址变更,后续进程在寻址时可能找不到目标。
此处需要注意
地址变更,因为后面我们也会提到,操作系统的PageCache操作不当也会引起这个问题。
还有一个问题是,这种循序的空间并不安全,所有进程之间都可以互相访问到对方的地址,这是一些修改器的常用手段。
基于以上问题,操作系统映入了保护模式,基于页表将内存空间调整为虚拟内存,与实际的物理内存区分开。
现在的页表通常是二级页表,所谓两级页表就是对页表再进行分页,一个页表内的所有页表项是连续存放的,页表本质上是一堆数据,也是以页为单位存放在内存。
第一级称为页目录表。每个页表的物理地址在页目录表中都以页目录项(PDE)的形式来存储,4MB的页表再次分页可以分为1K(4MB/4KB)个页,对每个页的描述需要4个字节,所以页目录表占用4K大小,正好是一个标准页的大小,其指向第二级表。线性地址的高10位产生第一级的索引,由索引得到的表项中,指定并选择了1K个二级表中的一个页表。
第二级称为页表,存放在一个4K大小的页面中,包含1K个表项,每个表项包含一个页的物理基地址。线性地址的中间10位产生第二级索引,可以获得包含页的物理地址的页表项。这个物理地址的高20位与线性地址的低12位形成了最终的物理地址。
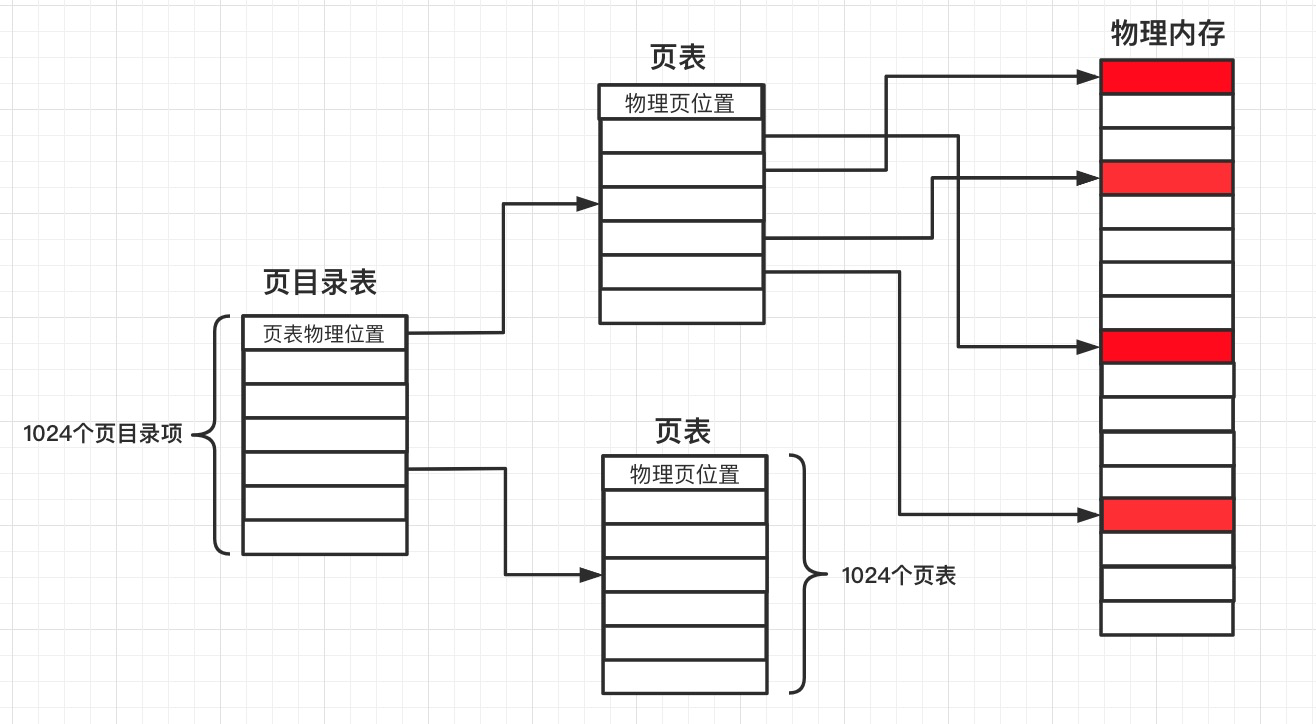
有了页表就能很好的划分进程空间,以及减少碎片空间了,对于一个进程而言,理论上最大可使用空间为4GB。基于此,操作系统的内存操作大多都是基于页(4KB).
虚拟内存的映入使得操作系统管理划分内存更加方便,实际进行虚拟地址映射到物理地址的单元是MMU,mmap内存文件映射也是一样,通过MMU映射到文件。
为了解决磁盘IO效率低下的问题,操作系统在进程空间内增加了一片空间,用于与磁盘文件进行地址映射,这部分内存也是虚拟内存地址,通过指针操作这部分内存,系统会自动将处理过的页写回对应的磁盘文件位置,就不需要去调用系统read、write等函数,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
这部分内存映射需要维护一份页表,用于管理内存——文件地址的映射关系,如果当前虚拟内存地址找不到对应的物理地址,就会发生所谓的缺页,缺页时系统会根据地址偏移量在PageCache中查看目标地址是否已经缓存过了,如果有就直接指向该PageCache地址,如果没有就需要将目标文件加载入PageCache中。
通过mmap的映射功能,就能避免IO操作,直接去操作内存,这就是所谓的零拷贝技术。
下面将要从几幅图说起IO到零拷贝。
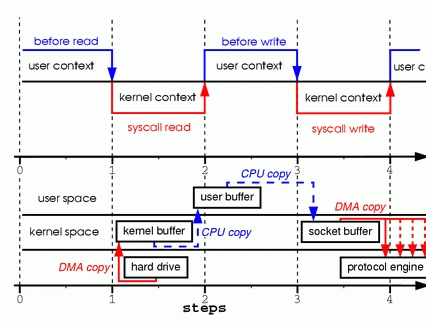
这是最普通的文件服务器传输文件过程,首先在内核态将文件从物理设备读取到内核空间,这是一次直接直接内存拷贝,然后用户进程需要从内核中将数据读取到用户进程空间,完成读的流程,这是一次CPU拷贝,至此,读的过程完成了,进程需要将数据发送给客户端,这时有需要将数据放到内核空间的socket处,之后通过协议层发送出去。
这整个流程需要两次CPU拷贝、两次直接内存拷贝,还需要不断在内核态用户态切换。(第一种:四次)
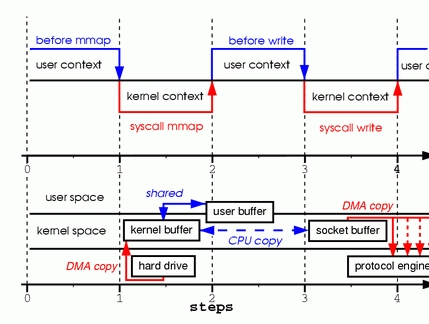
第二种模型是引入了mmap,在内核空间与用户空间建立映射关系,就可以让socket空间直接操作内核空间就能完成拷贝功能,还不需要在内核态用户态之间切换,write系统调用使内核将数据从原始内核缓冲区复制到与套接字关联的内核缓冲区中。
这个方式使用mmap代替了read,虽然看上去减少了拷贝,但是缺存在风险。当映射一个文件到内存,然后调用write,在另一个进程write同一个文件时,就会发生系统错误。(第二种:三次)
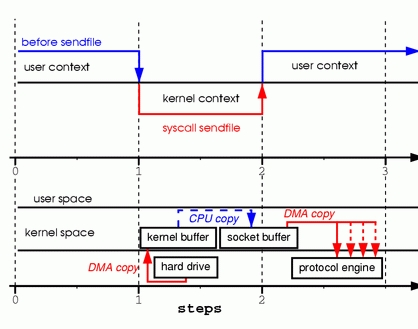
第三种模型,基于Linux新增引入的sendfile系统调用,不仅能减少文件拷贝,还能减少系统切换,sendfile可以直接完成内核空间的拷贝流程,从内核空间拷贝到套接字空间,由此跳过了用户空间。(第三种:三次)
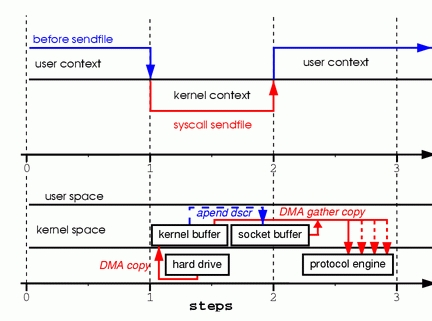
第四种模型,在内核版本2.4中,对sendfile进行了优化,可以直接从内核空间将数据发送到协议器,还消除了到套接字区域的数据拷贝,对于用户级应用程序没有任何变化。(第四种:两次)
综上,数据发送的流程中数据不会结果多余的拷贝,内核与用户态空间内都不会有多余的备份,这就是所谓的零拷贝技术,基于sendfile与mmap。
说回RocketMQ
MQ是IO使用的大户,MMap、FileChannel、RandomAccessFile是MQ文件操作最常使用的方法。
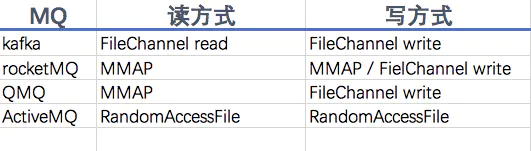
RocketMQ支持MMap与FileChannel,默认使用MMap,在PageCache繁忙时,会使用FileChannel,同样也可以避免PageCache竞争锁。
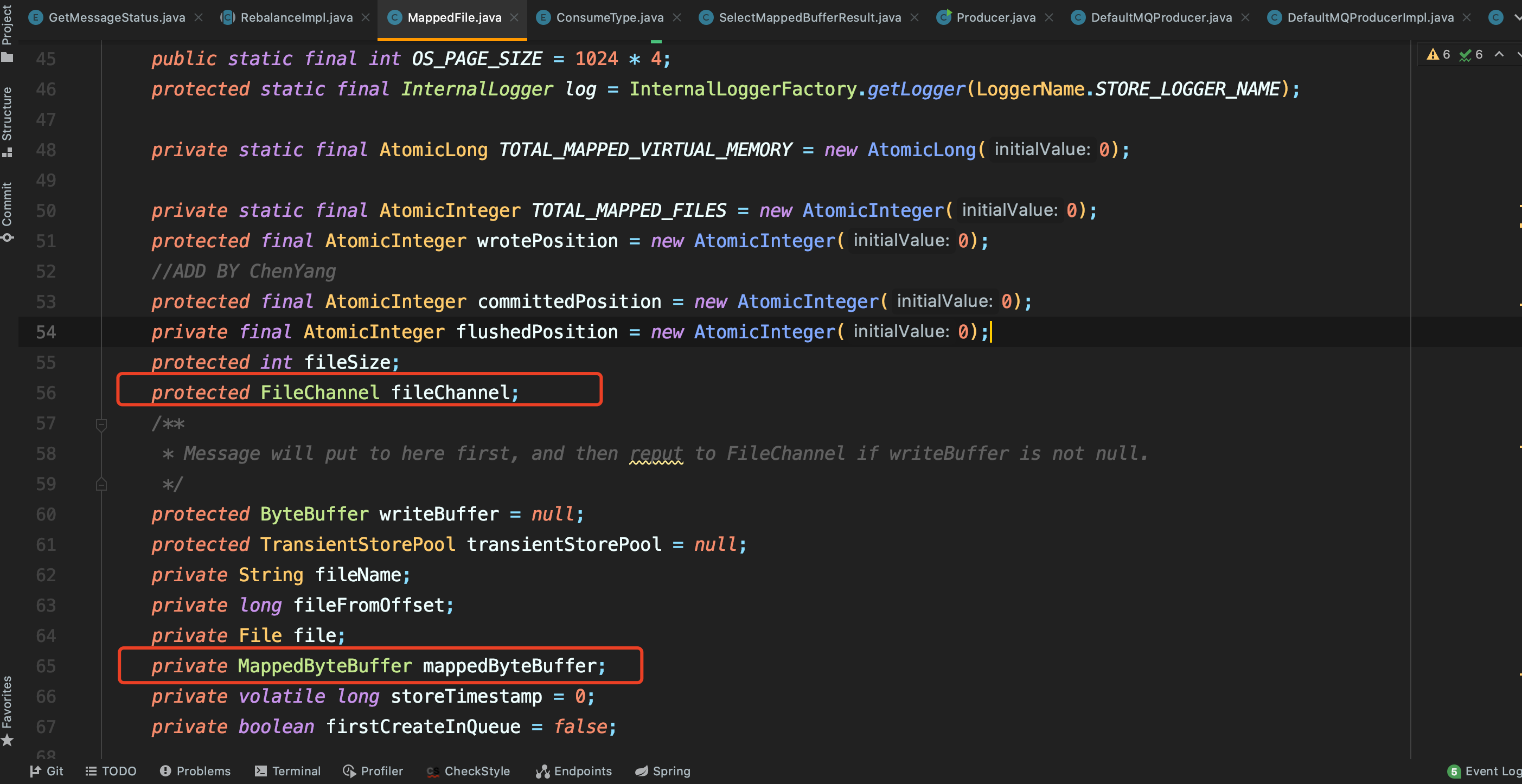
在MappedFile类中,可以看到FileChannel与MappedByteBuffer两个变量,在Java代码中可以通过FileChannel的map方法将文件映射到虚拟内存。
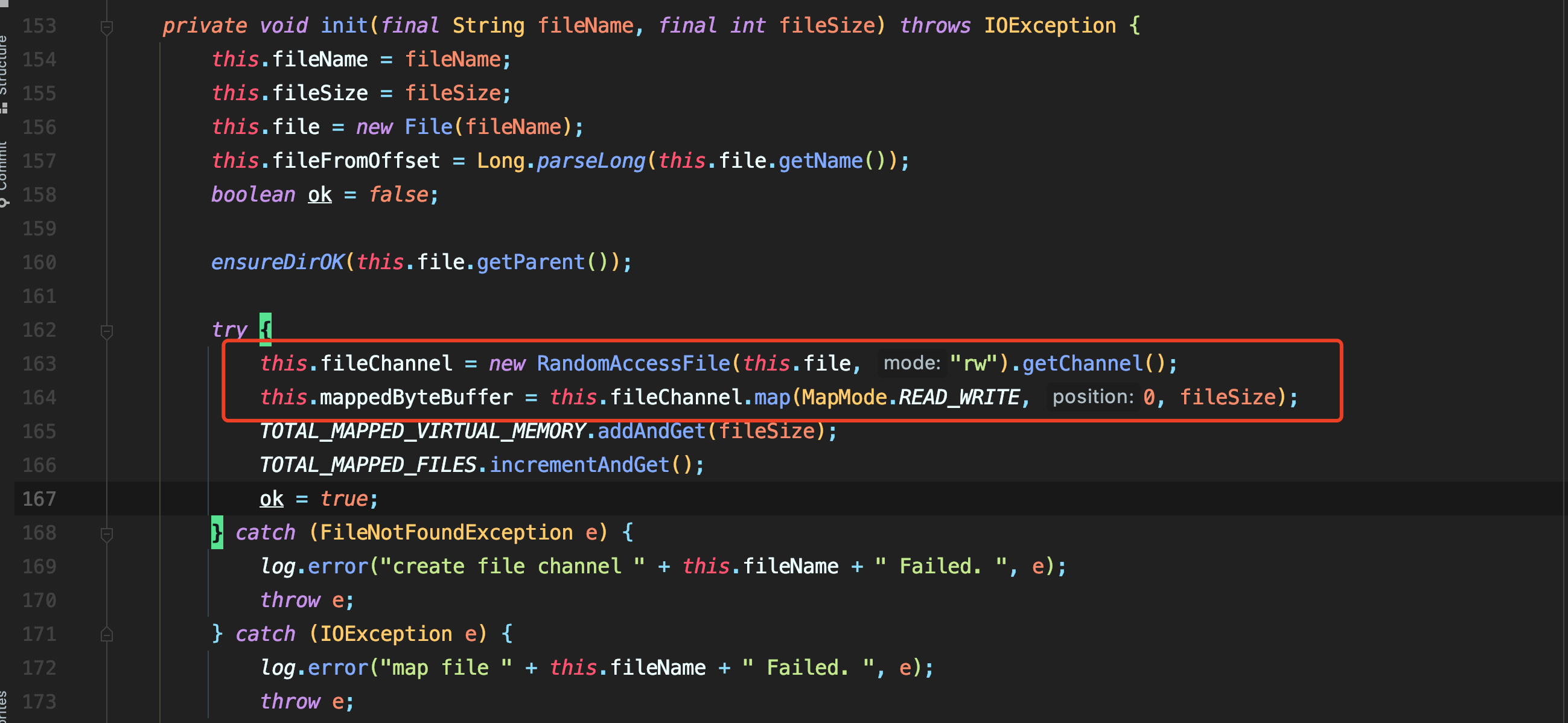
在MappedFile的init方法中也可以看到mmap初始化的过程。
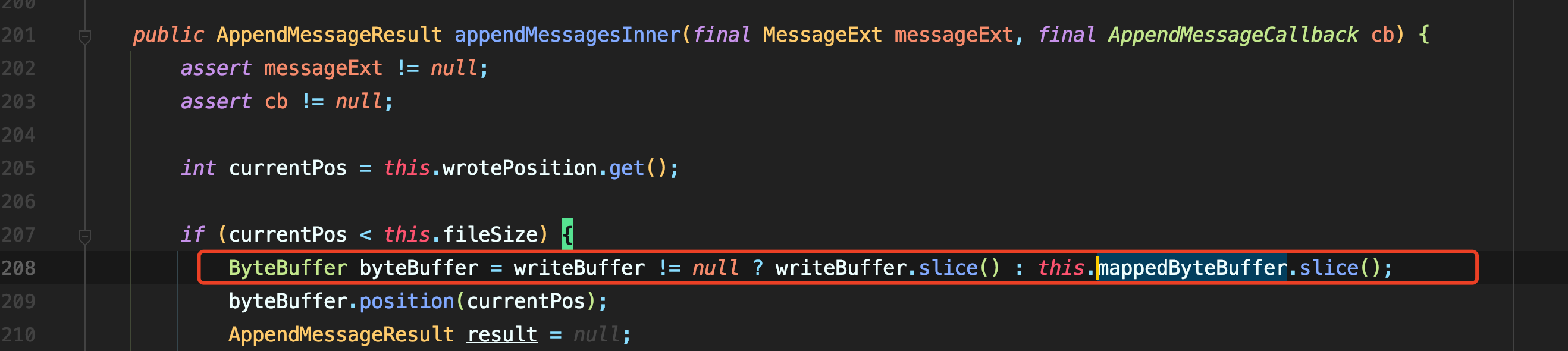
在实际的写入流程中,操作的buffer可能是mmap也可能是TransientStorePool申请来的直接内存,避免页面被换出到交换区。
TransientStorePool是否启用根据TransientStorePoolEnable确定,当开启时,表示优先使用堆外内存存储数据,通过Commit线程刷到内存映射Buffer中。
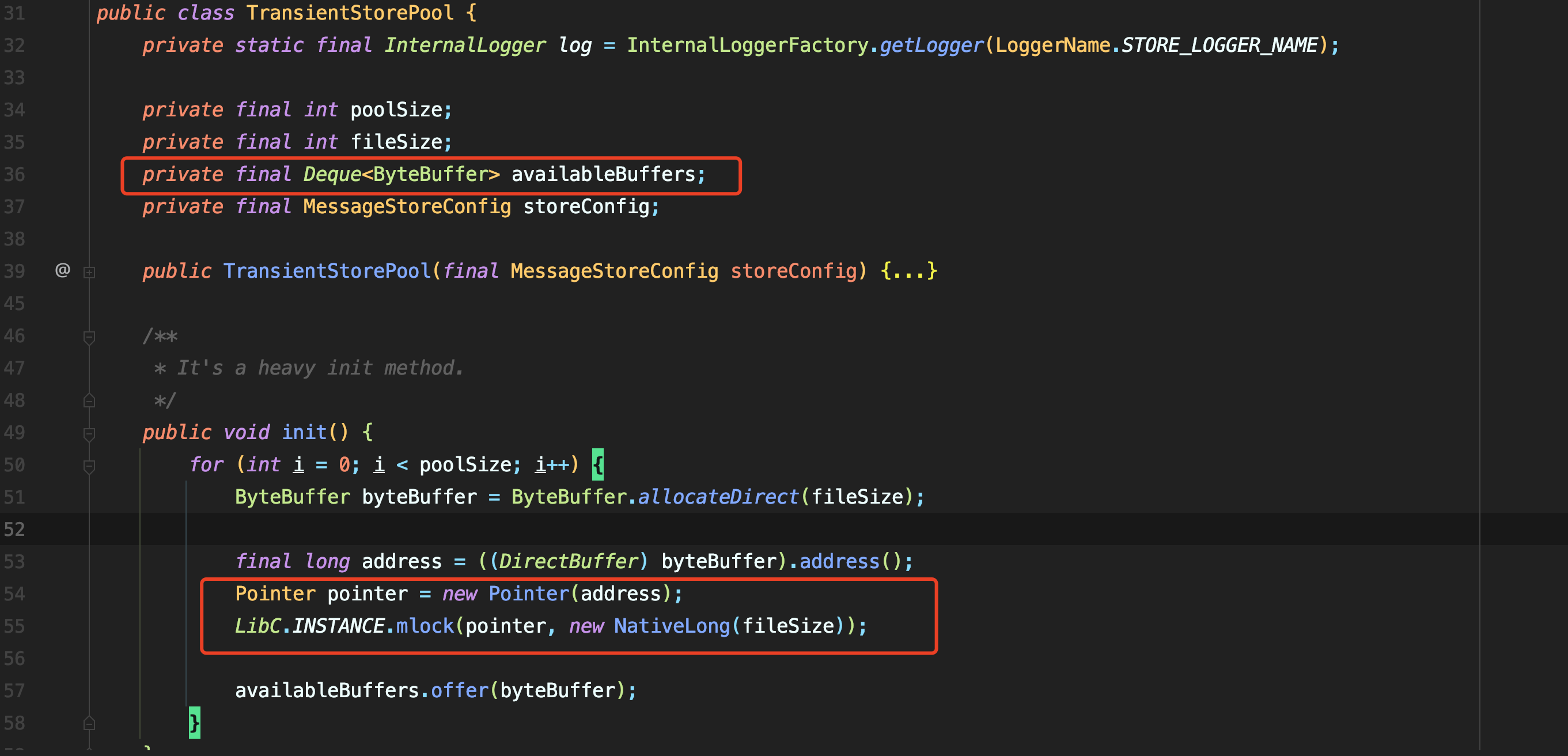
TransientStorePool是一个简易的池化类,其中包含了池的大小,每个单元存储的大小,存储单元的队列以及存储配置类。具体的初始化操作可以在init方法中看到有循环使用allocateDirect申请JVM外的内存空间,相比于allocate申请到的JVM内的内存,堆外内存操作更加迅速,免去了数据从堆外再次拷贝到堆内的流程。
申请到内存后,取到了申请的内存地址。
Pointer pointer = new Pointer(address);
LibC.INSTANCE.mlock(pointer, new NativeLong(fileSize));
拿到地址后,创建一个指向该处的指针,调用本地链接库的方法,将该地址的内存锁住,防止释放。
综上,相信你已经对页表、文件系统IO操作有了一定的认识了。
作者: AntzUhl
首发地址博客园:http://www.cnblogs.com/LexMoon/
代码均可在Github上找到(求Star) : Github
个人博客 : http://antzuhl.cn/
公众号 |
 |
赞助
支付宝 |
微信 |
 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号