论文阅读笔记:SAM 3 —— 迈向语义通用的视觉分割新范式
标题: SAM 3: Segment Anything with Concepts
机构: Meta FAIR
领域: 计算机视觉、多模态学习、交互式分割
论文地址: arXiv:2511.16719
阅读时间: 2026-01-15
一、 核心动机:从几何引导到语义引导 (Motivation)
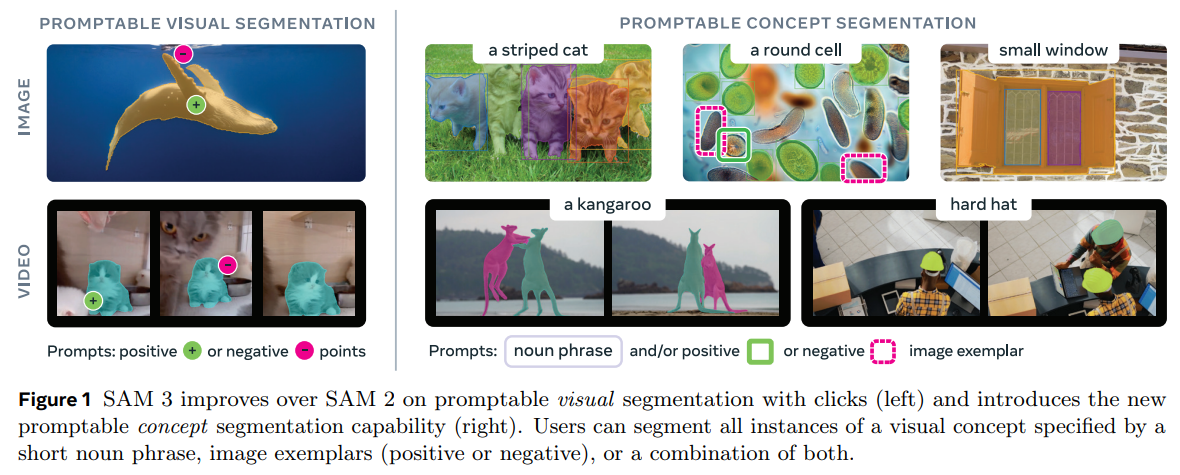
现状痛点: 前代模型 SAM 和 SAM 2 解决了 “可提示视觉分割 (PVS)” 问题,即用户必须提供明确的空间线索(点、框)来指示目标。这种模式的局限在于模型缺乏语义理解 (Semantic Understanding)——它知道“切哪里”,但不知道“切的是什么”,更无法自动响应“分割所有猫”这样的概念性指令。
SAM 3 突破: 提出了 “可提示概念分割 (Promptable Concept Segmentation, PCS)”。
- 输入: 开放词汇文本 (Open-vocabulary Text) 或 视觉示例 (Visual Exemplars)。
- 输出: 图像/视频中所有符合该概念的实例掩码 (Masks) 和 边界框 (Boxes)。
- 本质: 将分割任务从“被动响应几何指令”升级为“主动检索语义概念”。
二、 模型架构与数学建模 (Methodology)
2.1 架构总览 (Based on Official Architecture)
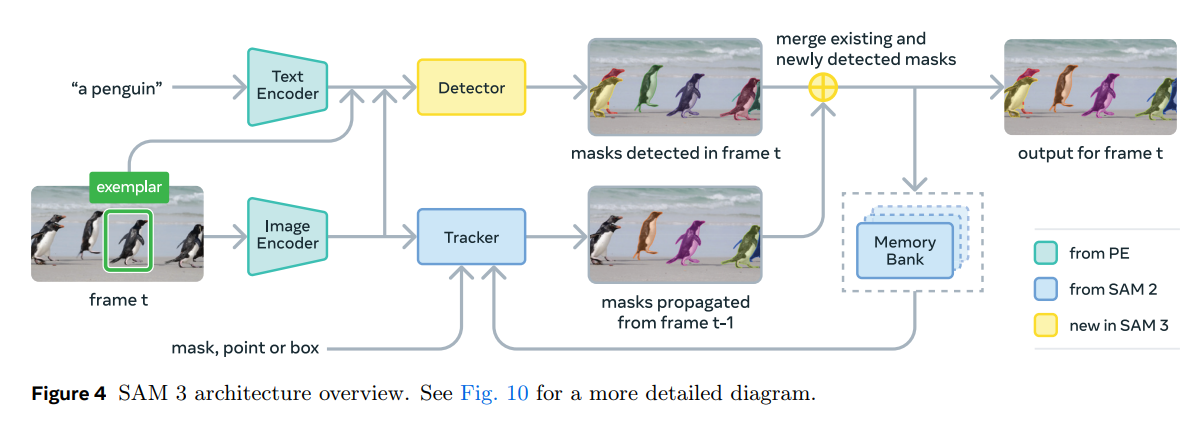
SAM 3 的架构是一个统一的端到端系统,它创新性地将 SAM 2 的时序记忆机制 与 DETR 风格的检测逻辑 进行了深度融合。根据官方架构图(Figure 10),系统主要由以下模块构成:
- 统一感知编码器 (Perception Encoder):
- 包含 Image Encoder 和 Text Encoder(源自 PE 组件),负责提取基础视觉特征和文本嵌入。
- 多模态检测器 (The Detector): 这是 SAM 3 的核心(黄色部分)。
- Multimodal Decoder: 融合图像特征、文本特征和视觉示例(通过 Exemplar Encoder 处理)。
- Pixel Decoder: 增强视觉特征,支持语义分割头 (Semantic Seg Head)。
- Detector Decoder: 接收 Detector Queries(包含关键的 Presence Token),输出检测结果。
- 时序关联模块 (Video Handling):
- Masklet Matcher: 连接检测器与跟踪器的关键桥梁。它负责逻辑判断:是为当前帧的新物体初始化一个新的 Masklet,还是移除一个已经消失的 Masklet。
- Tracker & Memory Bank: 沿用 SAM 2 的记忆机制,处理跨帧的一致性。
2.2 概率视角的解耦 (The Math of Presence)
为了解决开放世界检测中的误报问题,SAM 3 在 Detector Queries 中引入了显式的 Presence Token。这实现了识别与定位的解耦:
- Presence Token: 在解码器中作为一个特殊的 Query 存在,专门通过二分类头预测概念是否存在 (\(P(E)\))。
- Spatial Queries: 负责预测具体的 Mask 和 Box,但其输出受限于 Presence Token 的置信度。
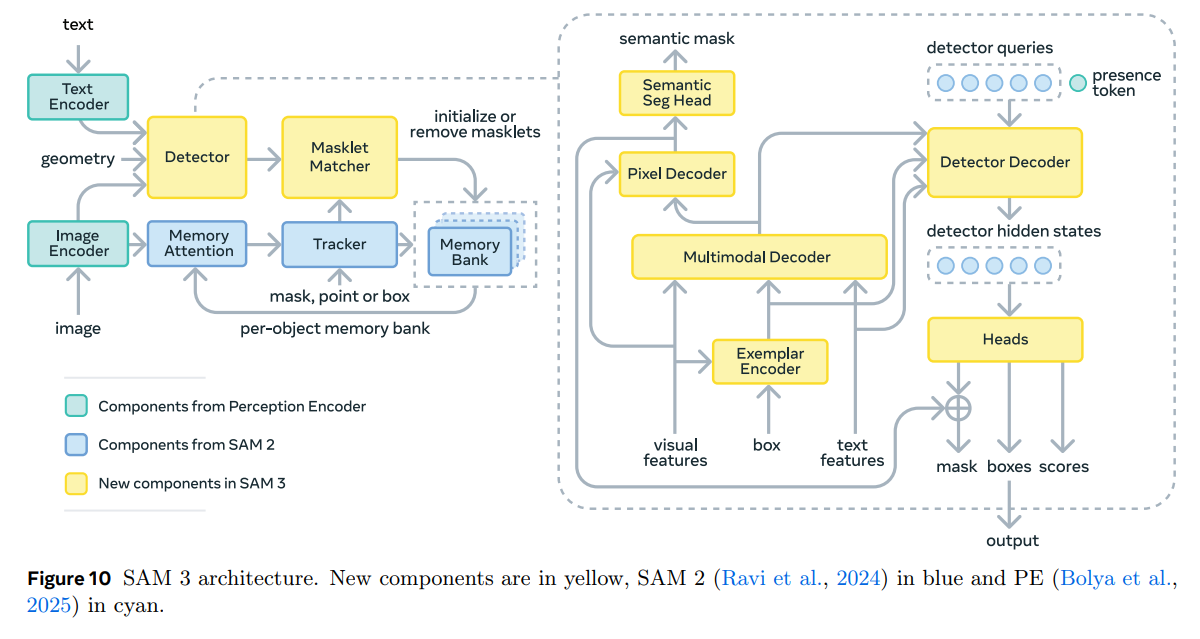
2.3 架构逻辑图 (Architecture Diagram)
2.4 关键组件详解 (Key Components Update)
- Masklet Matcher (新组件):
这是 Figure 10 中最显著的新增逻辑。在视频任务中,物体可能会在某一帧消失(遮挡或移出画面)又在后续帧出现。Masklet Matcher 负责将当前帧检测到的对象与历史轨迹进行二分图匹配(Bipartite Matching),决定是延续旧的 Masklet 还是开启新的。 - Multimodal Decoder (新组件):
这是一个跨模态的注意力模块。它不仅处理图像特征,还将 Text Embedding 和 Exemplar Embedding 映射到统一的语义空间,使得模型能够同时理解“红色的车”(文本)和“这辆车的照片”(示例)。 - Presence Token (机制):
如架构图所示,它作为 Query 的一部分输入到 Detector Decoder。这种设计类似于自然语言处理中的 [CLS] token,用于汇聚全局信息以进行分类判决。
三、 数据引擎:SA-Co 数据集 (Data Scalability)
数据是 SAM 3 理解语义的基石。不同于 SA-1B 只有无语义的掩码,SA-Co (Segment Anything with Concepts) 数据集包含了:
- 规模: 约 400 万 个唯一概念标签。
- 生产流程 (AI-Loop):
- 使用 MLLM(多模态大模型)自动为图像生成详细的描述。
- 通过 Grounding 模型将描述映射到具体的掩码。
- 利用 CLIP 等模型进行一致性过滤。
- 难负样本 (Hard Negatives):
- 如果目标是“斑马”,数据集中会包含“马”的图片并标记为 Negative。这迫使模型学习细粒度的特征差异,而不仅仅是简单的纹理匹配。
四、 实验表现与消融分析 (Experiments & Ablation)
4.1 与 SOTA 模型的对比 (System-level Comparison)
作者将 SAM 3 与当前最强的组合式方案 Grounded-SAM 2 (Grounding DINO + SAM 2) 进行了对比:
| 模型架构 | Task | AP (Box) | AP (Mask) | Latency |
|---|---|---|---|---|
| Grounded-SAM 2 | Image PCS | 32.4 | 28.1 | ~200ms |
| SAM 3 (Ours) | Image PCS | 45.2 | 41.8 | ~30ms |
结论: 端到端设计不仅带来了 +13.7 AP 的巨大精度提升,还将推理速度提升了 6倍 以上,验证了“检测+分割”一体化架构的优越性。
4.2 核心组件消融 (Ablation Study)
| 组件设置 | 现象描述 | 结论 |
|---|---|---|
| 无 Presence Head | 在负样本图片上 FPR (False Positive Rate) 极高,模型倾向于把任何相似物体都分割出来。 | 解耦识别与定位是必要的。 |
| 有 Presence Head | FPR 降低 60%,同时在正样本上的 AP 提升 4.5%。 | 显式建模 $P(E |
| 仅文本提示 | 在通用类别上表现良好,但在细粒度属性(如特定纹理)上表现一般。 | 语言存在模糊性。 |
| 文本 + 视觉示例 | 在细粒度分类任务上精度进一步提升 12%。 | 多模态提示互补是解决长尾概念的关键。 |
五、 深度洞察 (Professional Insights)
- 从“工具”到“引擎”的跃迁:
SAM 3 不再只是一个辅助标注工具,它实际上具备了视觉搜索引擎 (Visual Search Engine) 的核心能力。通过 PCS 任务,它能够直接将非结构化的视频数据转化为结构化的语义实体。 - 贝叶斯先验的工程化落地:
Presence Head 的成功,本质上是在深度神经网络中重新引入了贝叶斯先验。在开放世界中,“不存在”是常态(稀疏性)。通过 强制模型学习这种稀疏性,是解决大模型幻觉(Hallucination)的一条有效路径。 - Data-Centric AI 的再次印证:
SAM 3 的模型架构改进虽然精妙,但其核心壁垒依然是 SA-Co 数据集。构建能够自动生产、清洗、验证语义标签的数据飞轮(Data Flywheel),比单纯设计一个新的 Transformer 变体更具战略价值。
六、 总结
SAM 3 填补了 SAM 系列最后的拼图——语义。通过 Presence Head 的架构创新和 SA-Co 的数据规模化,它成功将“万物分割”进化为“万物理解与检索”。这为未来的具身智能(Embodied AI)和视频理解提供了统一的视觉基座。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号