第一单元总结
一、前言
本单元的主题为表达式的识别与化简。个人认为本单元的作业难度相比Pre和先前编写的代码作业难度和工程量有着明显的提升,此外,还面临着面向对象思想的转变。这一度在开始时让我手足无措,多亏第一单元训练给我指明了方向并让我理解了递归下降的思想。
二、程序结构
2.1.第一次作业
UML类图如下所示:
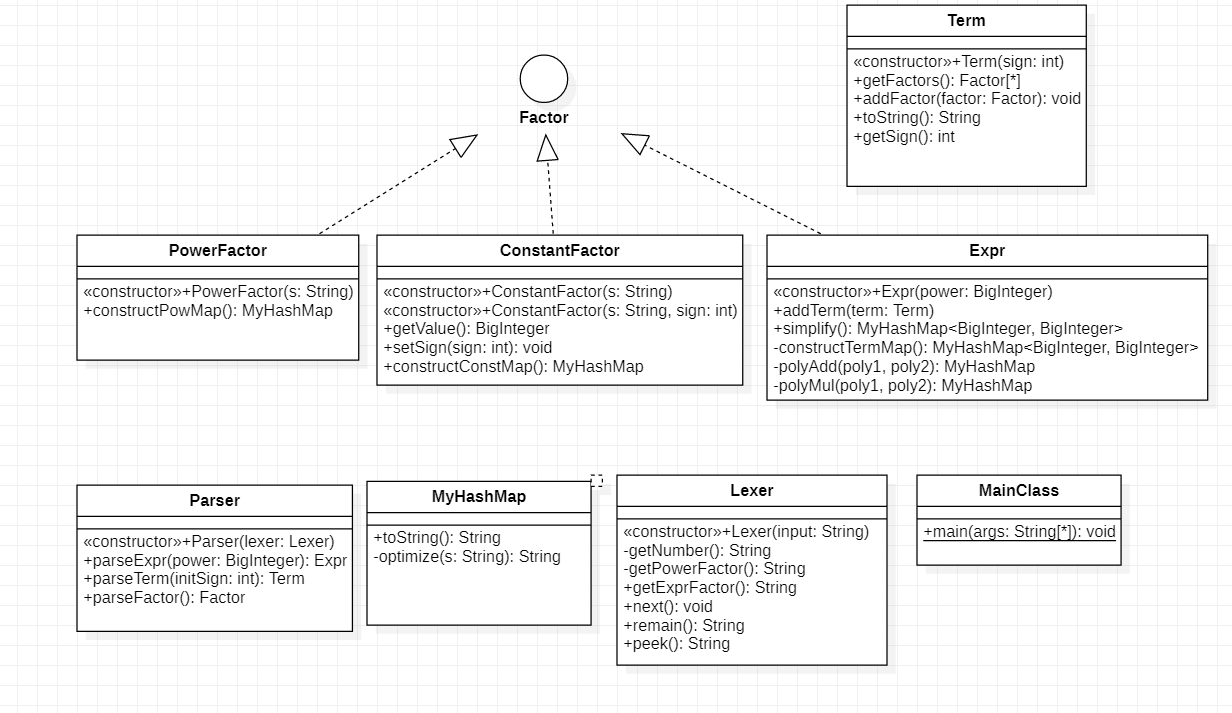
第一次作业主要参考了第一单元训练的架构,将词法分析和转换用两个类Lexer和Parser表示,使用递归下降构建表达式数据结构。
程序主要思想:
-
表达式预处理
预处理将去掉读取表达式的所有空白符,并使用正则表达式化简所有相邻的正负号。
-
表达式解析——递归下降
在Parser类中递归处理表达式的识别工作,结构为
parseExpr(), parseTerm(), parseFactor()顺序调用,在因子识别parseFactor()中,当识别到括号时,创建表达式因子,并递归调用表达式的parse操作parseExpr(). -
表达式构建
根据形式化表述,使用Expr, Term, Factor三个层次依次表示表达式、项、因子。每一级使用HashSet存储其所包含的下一级结构。PowerFactor, ConstantFactor, Expr三个类均实现了Factor接口。
-
化简时的存储结构
由于第一次作业中的基本因子仅有幂函数因子和常数因子,最终化简所得的表达式必然是一个x的多项式。故使用一个HashMap<BigInteger, BigInteger>来做表达式的化简存储结构,其中key为x的指数,value为x^{key}项的系数。
代码共460行
主要高复杂度方法如下:
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| MyHashMap.toString() | 24 | 2 | 11 | 12 |
| Expr.constructTermMap(Term) | 17 | 1 | 7 | 7 |
| Parser.parseFactor() | 15 | 3 | 8 | 8 |
| Lexer.next() | 11 | 2 | 7 | 10 |
| Expr.polyMul(MyHashMap<BigInteger, BigInteger>, MyHashMap<BigInteger, BigInteger>) | 9 | 3 | 4 | 6 |
类复杂度如下:
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| MyHashMap | 5.5 | 10 | 11 |
| Parser | 4 | 8 | 16 |
| Expr | 3.33 | 7 | 20 |
| Lexer | 2.57 | 8 | 18 |
| MainClass | 2 | 2 | 2 |
| PowerFactor | 2 | 3 | 4 |
| ConstantFactor | 1.4 | 3 | 7 |
| Term | 1.4 | 3 | 7 |
高复杂度原因分析:
-
我在输出时,用MyHashMap类继承HashMap类,并复写toString方法。由于优化引入了大量if else嵌套判断语句,导致复杂度较大,从而直接导致了MyHashMap类的高复杂度。
-
另外,constructTermMap方法作为简化表达式的核心方法,由于未充分拆分导致代码较为冗长,复杂度较大。
-
Parser类由于表达式的转化存在递归结构和大量判断语句,耦合度较大。
2.2.第二次作业
UML类图如下所示:
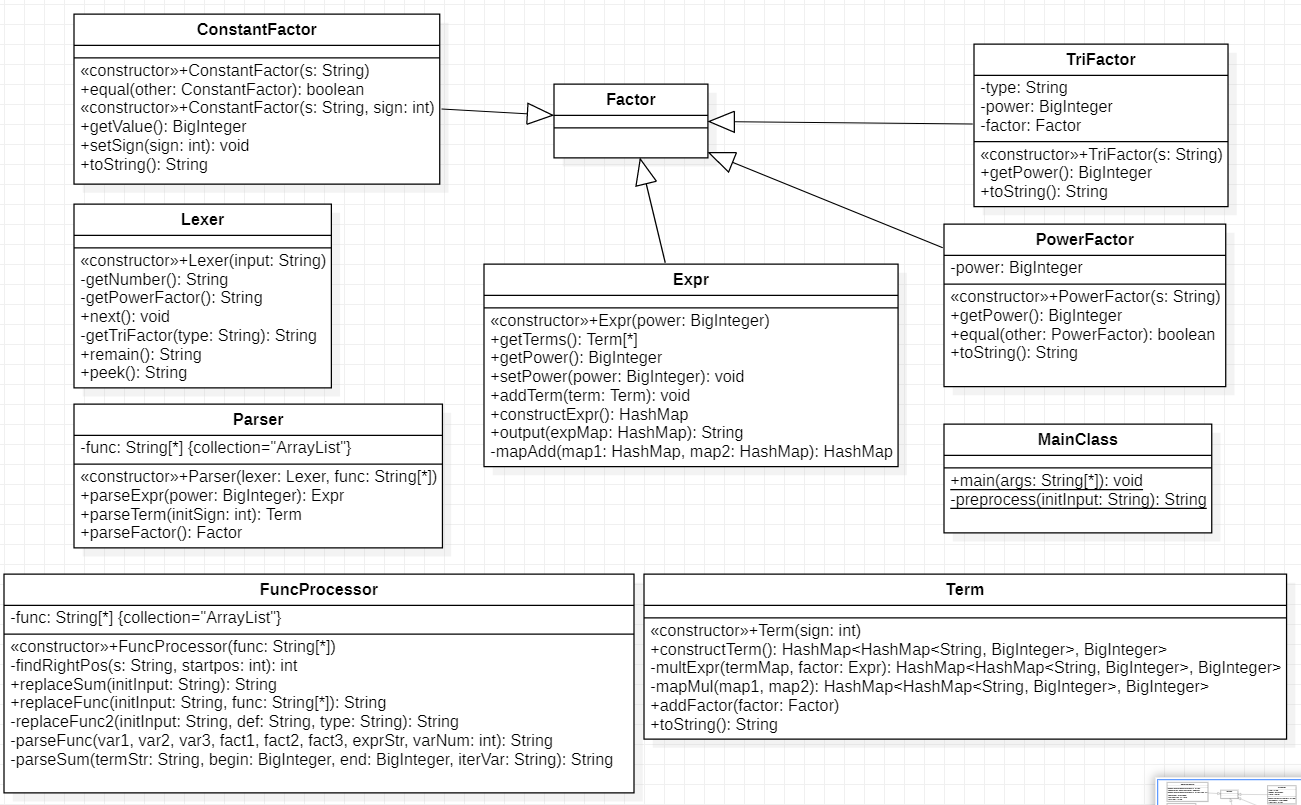
第二次作业增添了三角因子、自定义函数和求和函数三个因子,程序结构相比第一次作业主要的改动如下:
-
增添TriFactor类
和PowerFactor类似定义了三角因子,继承Factor父类。内部属性factor利用Factor类实现,此处并未局限于第二次作业三角函数内部仅有幂函数因子和常数因子的限定,为第三次作业的扩展打下基础。
-
增添FuncProcessor类
本类整合了读入表达式对自定义函数和求和函数做预处理的一些方法。我使用正则表达式识别加字符串替换的方法预先将读入的表达式进行处理,识别内部所有的自定义函数和求和函数并进行替换,再交给Lexer, Parser进行解析。
这样的预处理方法存在明显的局限性,也就是函数嵌套时难以识别到正确的括号匹配,在第三次作业中对此做了修复。
-
采用嵌套的HashMap结构化简表达式
由于三角因子的加入,化简表达式时无法再视为多项式进行处理,故使用
HashMap<HashMap<String, BigInteger>, BigInteger>这样的嵌套HashMap进行表达式的化简。其中外层HashMap的key为表达式的项,value为该项的系数;内层HashMap的key为项内因子的字符串形式,value为该因子的幂次。例如,3sin(x)x*2+2cos(x)的expMap为:
{ ( {("sin(x)", 1), ("x", 2)} , 3), ( {("cos(x)", 1)} , 2) }.另外,由于项Term和表达式Expr具有相似的结构,项内可能有表达式因子,表达式内部也有很多项,所以项和表达式在化简时是相互耦合的。故将项和表达式均构造成上述的HashMap进行统一处理,具体实现为Term.constructTerm()和Expr.constructExpr()相互嵌套。
代码共832行
主要高复杂度方法如下:
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Expr.output(HashMap<HashMap<String, BigInteger>, BigInteger>) | 50 | 2 | 17 | 17 |
| Term.constructTerm() | 39 | 1 | 14 | 14 |
| FuncProcessor.replaceFunc2(String, String, String) | 30 | 12 | 11 | 14 |
| FuncProcessor.replaceSum(String) | 18 | 9 | 8 | 9 |
| Term.mapMul(HashMap<HashMap<String, BigInteger>, BigInteger>, HashMap<HashMap<String, BigInteger>, BigInteger>) | 17 | 3 | 6 | 8 |
| Parser.parseFactor() | 16 | 4 | 11 | 11 |
| Lexer.next() | 15 | 2 | 11 | 14 |
| FuncProcessor.parseFunc(String, String, String, String, String, String, String, ...) | 10 | 1 | 6 | 6 |
| Lexer.getTriFactor(String) | 8 | 1 | 6 | 8 |
类复杂度如下:
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| FuncProcessor | 5.86 | 14 | 41 |
| Term | 5.17 | 14 | 31 |
| Parser | 4 | 8 | 16 |
| Expr | 3.5 | 14 | 28 |
| Lexer | 3.43 | 10 | 24 |
| TriFactor | 3.33 | 5 | 10 |
| MainClass | 2 | 2 | 4 |
| PowerFactor | 1.75 | 3 | 7 |
| ConstantFactor | 1.33 | 3 | 8 |
| Factor | 0 |
与第一次作业对比可发现,由于题目变得更加复杂,我原本的架构由于对耦合的优化不够,代码复杂度大量膨胀。对这部分的优化主要在第三次作业中进行。
本次作业的高复杂度方法主要集中于化简输出和最初预处理自定义函数和求和函数两个模块。Term.constructTerm()由于其对不同类型Factor的分类和大量的HashMap操作使得复杂度很高。Expr.output同样由于优化复杂度大大提高。
2.3第三次作业
UML类图如下所示:
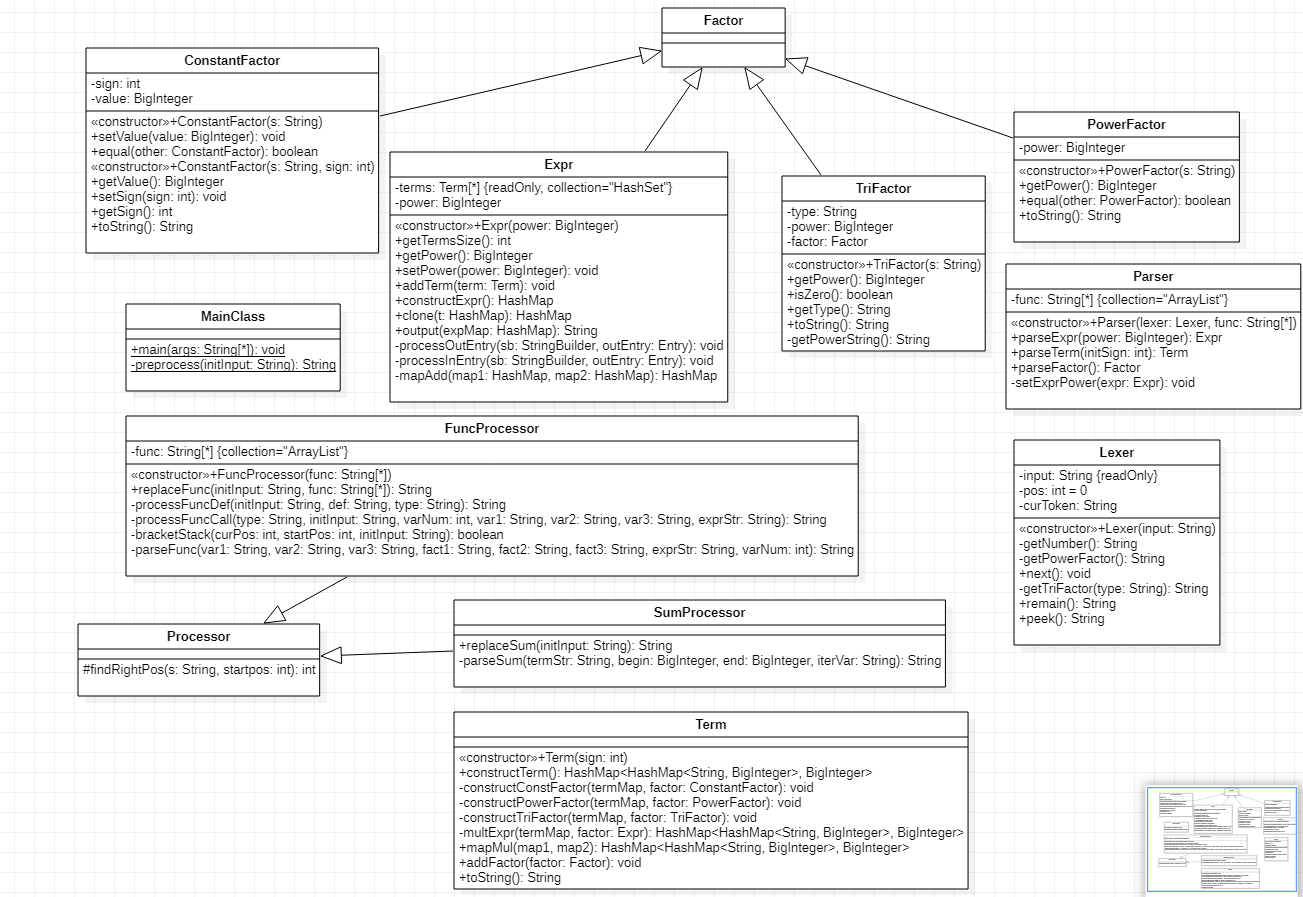
第三次作业增加了表达式的多层嵌套和函数调用的多层嵌套,三角因子的内部也支持所有的因子。程序结构相比第二次作业,主要改动如下:
-
调整Processor类
将函数和求和函数的预处理分开成两个类以降低类复杂度。在自定义函数的替换时,与第二次作业正则表达式匹配整个函数调用不同,为了处理嵌套调用,本次仅使用正则表达式匹配函数名f, g, h. 在函数调用参数的解析方面,使用堆栈原理寻找与之匹配的左右括号以及内部的每一个逗号,最终进行字符串替换。此方法的思维量较低,但工程量较大,最终使得此模块的相关方法复杂度较大。
在自定义函数和求和函数的处理方面,另一种办法是对自定义函数调用和求和函数都设计新的类继承Factor,当做因子在Parser中做解析,后通过类中的代入方法进行计算,由于构思本方法需要时间较多,我在时间吃紧的条件下,还是选择了实现较为简易的字符串替换方法。
-
TriFactor内部factor的解析
把TriFactor的括号内部当成一个一般因子处理,创建新的Lexer和Parser,调用parseFactor()方法进行解析,以解决三角嵌套问题。此外,在内部为表达式因子的toString方法中调用了Expr.output()方法生成所需的字符串作为外层表达式内层HashMap的键。
代码共965行
主要高复杂度方法如下:
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| FuncProcessor.processFuncCall(String, String, int, String, String, String, String) | 31 | 12 | 14 | 15 |
| SumProcessor.replaceSum(String) | 21 | 9 | 9 | 10 |
| Term.mapMul(HashMap<HashMap<String, BigInteger>, BigInteger>, HashMap<HashMap<String, BigInteger>, BigInteger>) | 17 | 3 | 6 | 8 |
| Expr.processOutEntry(StringBuilder, Entry<HashMap<String, BigInteger>, BigInteger>) | 15 | 1 | 7 | 7 |
| Lexer.next() | 15 | 2 | 11 | 14 |
| Expr.processInEntry(StringBuilder, Entry<HashMap<String, BigInteger>, BigInteger>) | 10 | 1 | 8 | 8 |
| FuncProcessor.parseFunc(String, String, String, String, String, String, String, ...) | 10 | 1 | 6 | 6 |
类复杂度如下:
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| SumProcessor | 6.5 | 10 | 13 |
| FuncProcessor | 5 | 12 | 30 |
| Processor | 4 | 4 | 4 |
| Term | 3.55 | 8 | 39 |
| Lexer | 3.43 | 10 | 24 |
| Parser | 3.4 | 6 | 17 |
| Expr | 3.18 | 6 | 35 |
| TriFactor | 2.67 | 6 | 16 |
| MainClass | 2 | 2 | 4 |
| PowerFactor | 1.75 | 3 | 7 |
| ConstantFactor | 1.25 | 3 | 10 |
| Factor | 0 |
本次作业做了大量的方法拆分和功能再整理,使得整体的方法复杂度有所下降,最明显的即为Expr.output(), 在将其拆分为Expr.processInEntry()和Expr.processOutEntry()后复杂度大大降低。但由于预处理求和函数和自定义函数的算法较为复杂导致SumProcessor和FuncProcessor及其相关方法的复杂度仍居高不下。
三、优缺点
3.1优点
-
由于分三层次递归下降解析的总体架构在第一次作业中已明确,在迭代开发的过程中未进行大规模重构。基本思想一脉相承,迭代时不必推倒重来。
3.2缺点
-
未做充分的化简,例如在第二次作业中未做cos(0)类的优化,第三次作业未做倍角公式优化导致性能分缺失。
-
自定义函数及求和函数的字符串替换方法复杂度较大,可迭代性不足,对自定义函数和求和函数建模的方法虽然更佳,由于作业时间吃紧并未采用,略显遗憾。
四、主要Bug以及互测策略
4.1主要bug
由于测试不够充分,我的bug大部分为低级错误,在今后的作业中需要多加改正,多做测试。
第一次作业中未考虑指数前的的‘+’
第三次作业中对于sin(0)0特判顺序错误导致输出0,还有三角因子toString方法对于sin(cos(x)2)这样的输入中指数判断有误。
本单元作业的bug主要还是出在化简和输出阶段。这可能与此过程方法复杂度大有一定相关。
4.2互测
互测时我采取的是选取易错数据手动测试的方法,由于优化过程容易出现错误,故在互测中重点查看优化部分的代码(例如将“1*"直接替换为空串的暴力优化[捂脸])。
此外,还构造了边界数据,例如构造上下限均超int范围的求和函数和大数的幂等。
由于我每次hack均是已在本地测到bug才上传,故准确率较高,但由于数据范围有限,覆盖面不够广。
五、架构设计体验
在第一周的开发初始,我的思路还较为混乱。在做完训练后,学到了递归处理的精妙之处后,我脑海里的架构才逐渐成型。
六、心得体会
学期伊始,OO课的第一单元就让我体会到了本课程的硬度。第一次作业花费了我的大量的课后时间。但完成本单元的收获也确实与努力成正比,本次设计成功地锻炼了我的代码熟练程度和Java的编程思想,也让我体会到了测试的重要性,我一度认为中测过了就基本正确,不必再过多测试,但第三次作业的强测和互测让我因这个误解吃了大亏,下一次打算试着自己写一写评测机。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号