
【搜索】其一 排列、组合、子集生成
搜索是基础的编程技术,是基础中的基础,非常非常重要,而且也有难度。需要认真学习。
搜索体现了暴力法的思想,有很多用途:
- 很多问题只能用暴力搜索解决,如猜密码。
- 对小规模的数据,完全足够,而且简单不易出错。
- 暴力法往往用于参照,可以从它出发,逐步思考更高级的算法,而且在生成测试数据进行对拍上面很有用。
- 暴力法往往可以进行优化,使用剪枝跳过不符合要求的情况,减少搜索空间。
搜索的主要技术是枚举、排列组合、DFS和BFS,搭配上栈、队列、树、图等数据结构,相应的有递归的实现。
这是【搜索技术】的第一篇文章,可能会有第零篇是枚举。第二篇是BFS,第三篇是DFS、回溯和剪枝。之后会介绍高级搜索技术——如A*,双向广搜,迭代加深搜索,IDA*等。
一、递归生成排列
1. next_permutation 【字典序】
首先,我们要掌握的是排列的生成。排列有两种情况:
- 打印n个数据的全排列,排列总数
n*(n-1)*...*1=n!; - 从n个数据中任意选出m个数据进行全排列,有
n*(n-1)*...*(n-m+1)=n!/(n-m)!种情况。
由于暴力法总是需要考虑到所有的情况,而用递归编程往往可以轻松实现这一点,因此我们考虑用递归实现上面的两种函数。
先用STL的next_permutation实现全排列的打印,事先用sort排序得到最小排列,然后用next_permutation可以从小到大得到所有排列,优点在于是现成的函数,按照字典序。
关于next_permutation的实现解析,见STL next_permutation和prev_permutation的原理和具体实现。
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
int data[] = {5, 2, 1, 4};
sort(data, data + 4);
do {
for (int i = 0; i < 4; ++i)
cout << data[i] << " ";
cout << endl;
} while (next_permutation(data, data + 4));
return 0;
}
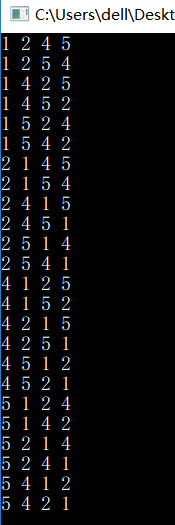
2. 递归-交换法
(a). 全排列
但是重点在于下面的★★★ 递归求全排列。
思路如下:设数字为a, b, c, d, e, ..., z共有\(N\)个数字,那么就是\(N!\)种情况,第一个数字有N种情况,第二个有N-1种情况,依次类推,那我们如何表达所有可能的数据呢?
(1). 让第一个位置的数变换出N种情况,下面的实现方法是将第一个数a和自己及其后的所有数字进行交换。由于第一个数不同,所以这些N个排列毫无疑问都是不同的!
a b c d e ... z 层1
b a c d e ... z 层2
c b a d e ... z
...
z b c d e ... a
(2). 让第二个位置的数变化出N-1种情况,即将第二个数和自己及其后的所有数字进行交换,这样第二个数就不同了,由此产生的N-1个排列都不同。
// 从层1递归进入,因此第一个数字都是a
a b c d e ... z
a c b d e ... z
a d c b e ... z
a e c d b ... z
...
a z c d e ... b
// 从层2递归进入,因此第一个数字都是b
b a c d e ... z
b c a d e ... z
b d c a e ... z
b e c d a ... z
...
b z c d e ... a
如此继续重复以上步骤,每次都会减少数字的规模,直到用完所有数字。
#include <iostream>
using namespace std;
// 排列
int data[] = {1, 2, 3, 4, 5, 6, 8, 9, 10, 32, 15, 18, 33}; // 求排列的数据
#define Swap(a, b) { int temp = a; a = b; b = temp; }
int num = 0; // 排列的个数
/* 全排列 */
void fullPermutation(int begin, int end) {
//之所以begain==end表示结束,是因为对最后一层,只有一个数据,不用进行交换
if (begin == end) { // 这个排列包含了所有数据
++num; // 排列计数
for (int i = 0; i <= 9; ++i) // 输出这个排列
cout << data[i] << " ";
cout << endl;
} else {
for (int i = begin; i <= end; ++i) {
Swap(data[begin], data[i]); // 第1个数n种情况,与后面交换形成这n种情况...以此类推
fullPermutation(begin + 1, end);
Swap(data[begin], data[i]);
}
}
}
int main() {
fullPermutation(0, 9); // 3628800种情况 10*9*8*7...*1
cout << num << endl;
return 0;
}
(b). 部分数的全排列
如果只用★★★ 打印n个数中任意m个数的全排列,就改一下上面的代码就可以了:
为什么这么改?重点是任意m个数,由于我们采用交换的方式,因此数组data中前面m个数的排列就会表现出我们需要的所有结果。
当然,这样得到的部分数的排列不是按字典序的。
#include <iostream>
using namespace std;
int data[] = {1, 2, 3, 4, 5, 6, 8, 9, 10, 32, 15, 18, 33}; // 求排列的数据
#define Swap(a, b) { int temp = a; a = b; b = temp; }
/* 打印n个数中任意m个数的全排列, 共n!/(n-m)!个 */
int m = 3;
void permutation(int begin, int end) {
if (begin == m) {
++num;
for (int i = 0; i < m; ++i)
cout << data[i] << " ";
cout << endl;
} else {
for (int i = begin; i <= end; ++i) {
Swap(data[begin], data[i]);
permutation(begin + 1, end);
Swap(data[begin], data[i]);
}
}
}
int main() {
permutation(0, 9); // 720种情况 10!/(10-3)!=10*9*8=720
cout << num << endl;
return 0;
}
★★★ 3. 递归-选择法【字典序】
我们很容易注意到一件事,上面的递归-交换法固然可以求出全排列,但是它得到的结果不是按照字典序的,即使输入的数据是最小的排列(即已经从小到大排序):
\(e.g.\) 用上面的例子,a b c ... z最后一类是以\(z\)开头的排列,上述的方法将\(a\)和\(z\)交换,递归下去得到以\(z\)开始的第一个排列——z b c ... a;而以\(z\)开头的最小的排列应该是z a b c ... y。因此使得整个全排列不符合字典序。
(a). 全排列
那么我们有什么方法呢?下面的是我写的代码,通过选择进行。如果输入的是最小的排列,那么它会按照字典序输出全排列;如果输入的是随意的一个排列,它得到的全排列不按照字典序。
思想:假设输入的是最小的排列。每次函数调用都有一个\(for\)循环,\(i=0\),从\([i, end]\)的全部数据中,从0开始选择一个以前没选择的数据(这就是\([i, end]\)区间没有被选择的数据中最小的数),进入下一个递归。这样第一个得到的就是输入的排列。
\(e.g.\) 第一个先是选择了\(1\),得到了\(1\)开头的所有排列;然后选择\(2\),第二层又选择\(1\)......,得到\(2\)开头的所有排列;...
如果对\(n\)个数据每个数据选择\(n\)次,最后判断得到的数列是否符合条件,那么应该是\(O(n^n) \ ?\)的复杂度;如果是每次暴力判断这个数据使用过了没有,那复杂度减少了一些,但还是爆表。
所以下面使用了一个\(vis\)的bool数组,判断这个位序上的数据是否已被使用。...
#include <iostream>
using namespace std;
// 排列
int data[] = {1, 2, 3, 4, 5, 6, 8, 9, 10, 32, 15, 18, 33}; // 求排列的数据
#define Swap(a, b) { int temp = a; a = b; b = temp; }
int num = 0; // 排列的个数
/* 全排列 */
bool vis[10] = {0};
vector<int> vi;
void allPermutation(int k, int end) { //这里的k表示该选择排列中位序为k的数
if (k > end) {
++num;
for (int i = 0; i < vi.size(); ++i)
cout << vi[i] << " ";
cout << endl;
return;
}
for (int i = 0; i <= end; ++i) {
if (vis[i] == true) continue; //之前已经在该排列使用过了
vi.push_back(data[i]);
vis[i] = true; //标记这个位序的元素被使用了
allPermutation(k + 1, end);
vi.pop_back();
vis[i] = false;
}
}
int main() {
allPermutation(0, 9); // 3628800种情况 10*9*8*7...*1
cout << num << endl;
return 0;
}
使用allPermutation(0, 2)结果如下:

(b). 部分数的全排列
只打印n个数中任意m个数的全排列,改一下上面的代码就可以了,结果也是按照字典序的:
#include <iostream>
using namespace std;
// 排列
int data[] = {1, 2, 3, 4, 5, 6, 8, 9, 10, 32, 15, 18, 33}; // 求排列的数据
#define Swap(a, b) { int temp = a; a = b; b = temp; }
int num = 0; // 排列的个数
bool vis[10] = {0};
vector<int> vi;
int M = 3;
void Permutation(int k, int end) {
if (k == M) {
++num;
for (int i = 0; i < vi.size(); ++i)
cout << vi[i] << " ";
cout << endl;
return;
}
for (int i = 0; i <= end; ++i) {
if (vis[i] == true) continue;
vi.push_back(data[i]);
vis[i] = true;
Permutation(k + 1, end);
vi.pop_back();
vis[i] = false;
}
}
int main() {
Permutation(0, 9); // 720种
cout << num << endl;
return 0;
}
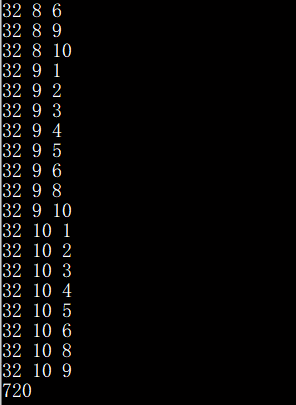
二、子集生成
不需要输出全排列,只需要输出组合,即子集(集合内部的元素是没有顺序的)。
一个包含n个元素的集合{a, b, c, d ... z},子集共有2n个,为{∮},{a},{b},... ,{a, b, c, d, ... z}。
那么,如何求子集呢?
1. 递归求子集
用递归的写法,就是对{a, b, c, d, ... , z}每个元素都有选和不选两种选择,因此对n个元素有2*2*...*2=\(2^n\)种可能,算法复杂度同上。
#include <iostream>
#include <vector>
using namespace std;
vector<int> subset;
void recurSubset(int begin, int end) {
if (begin > end) {
for (auto i : subset)
cout << i << " ";
cout << endl;
return;
}
subset.push_back(begin); // 选择这一元素
recurSubset(begin + 1, end);
subset.pop_back(); // 不选
recurSubset(begin + 1, end);
}
int main() {
recurSubset(0, 3); // 16种情况
return 0;
}
★★★ 2. 迭代求子集
迭代的写法,用n和二进制对应就很直观了。如n=3和{a, b, c}:
| 子集 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 二进制数 | 0 0 0 | 0 0 1 | 0 1 0 | 0 1 1 | 1 0 0 | 1 0 1 | 1 1 0 | 1 1 1 |
因此,每个子集对应一个二进制数,二进制数的每个1都对应这个子集中的一个元素,而且子集中的元素没有什么顺序。通过检查每个二进制数中的1打印相关的元素可以得到所有的子集。由于有\(2^n\)个子集,因此算法的复杂度为\(O(2^n)\)。
无疑,我更喜欢★★★迭代生成子集的写法,简单。·
#include <iostream>
#include <vector>
using namespace std;
void printSubset(int n) {
int total = (1 << n);
for (int i = 0; i < total; ++i) { //2^n个子集
for (int j = 0; j < n; ++j) // 每个集合要遍历n个元素, 看是否含有这个元素
if (i & (1 << j)) cout << j << " ";
cout << endl;
}
}
int main() {
printSubset(4); // 16种情况
return 0;
}
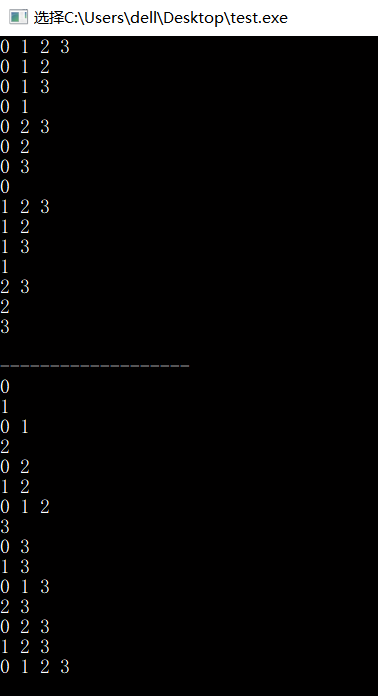
三、组合生成
从n个数据中任意选出m个数据进行组合,有n*(n-1)*...*(n-m+1)/m!=n!/[(n-m)!*m!]种情况。从全排列到任意m个数的排列,再到任意m个数的组合,解的数量越来越小。组合的总数之所以要除以m!,是因为这m个数会形成\(m!\)个排列,这些排列都是一样的组合。
我们思考一下该怎么做。从排列的两种代码改是肯定不可能的...emm,也不是不可能,在Permutation的基础上用set<vector<int>>保存每一个大小为m的排列,当然,这些排列都先进行排序,...,最后剩下的就是需要的组合了。这也可以用剪枝保持每m个数组合有序,从而选出来,当然,需要原始数据事先进行排序。
1. 递归求组合【DFS+剪枝】
第一种代码就是这样了。DFS+剪枝,剪去无序的组合。
#include <iostream>
#include <vector>
using namespace std;
int info[] = {2, 4, 5, 7, 9, 12}; // 15种情况
vector<int> c;
int t = 4;
void Combination(int begin, int end) {
if (c.size() == t) {
for (auto i : c)
cout << i << " ";
cout << endl;
return;
}
for (int i = begin; i <= end; ++i) {
if (!c.empty() && info[i] < c[c.size() - 1])
continue;
c.push_back(info[i]);
combination(i + 1, end); // i + 1, 这样不会重复自己
c.pop_back();
}
}

2. 递归求组合【递归求子集基础上】
第二种方法,和上面的DFS版本是同样的递归思想,但是出发点不同。
我们发现子集中元素是无序的,而且n个数中任意k个数的组合就是n个数的一个大小为k的子集。
为了看清楚做个示例:对于int info[] = {2, 4, 5, 7, 9, 12};,其子集如下,标红的就是要求的组合。
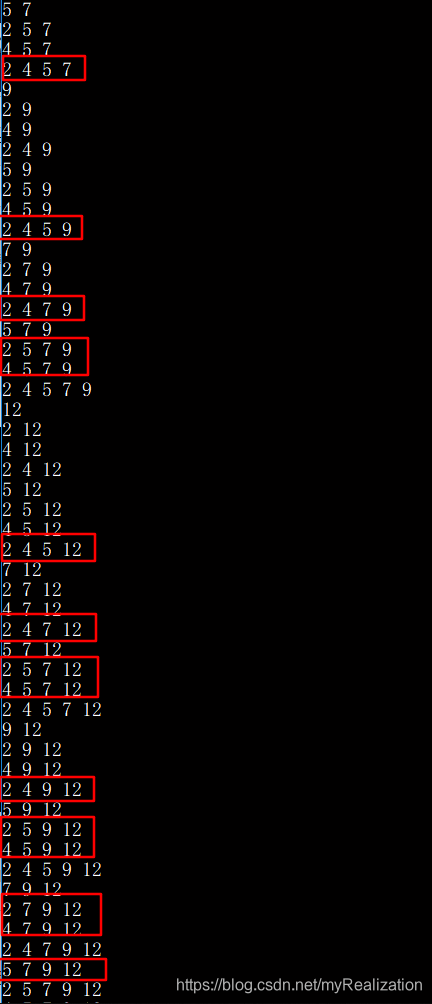
因此我们在上面打印子集的代码上面修改一下就可以了,从递归求子集的代码修改,只输出大小为k的子集。
#include <iostream>
#include <vector>
using namespace std;
int info[] = {2, 4, 5, 7, 9, 12}; // 15种情况
vector<int> vi;
int k = 4;
void recurCombine(int begin, int end) {
if (vi.size() == k) { //子集大小为k
for (auto i : vi)
cout << i << " ";
cout << endl;
return;
} else if (begin > end) return; //数组边界
vi.push_back(info[begin]); // 选择这一元素
recurCombine(begin + 1, end);
vi.pop_back(); // 不选
recurCombine(begin + 1, end);
}
int main() {
recurCombine(0, 5);
return 0;
}

★★★ 3. 迭代求组合【迭代求子集基础上】
这里是从迭代子集的基础上进行修改。
由于每一个子集对应一个二进制数,要找还有k个元素的子集,就转化为查找1的个数为k的二进制数。像上面一样数,就是初级版本的代码。
int k = 4;
void Combination(int n) {
int tot = (1 << n);
for (int i = 0; i < tot; ++i) {
int knum = 0;
for (int j = 0; j < n; ++j)
if (i & (1 << j)) ++knum;
if (knum == k) {
for (int j = 0; j < n; ++j)
if (i & (1 << j)) cout << info[j] << " ";
cout << endl;
}
}
}
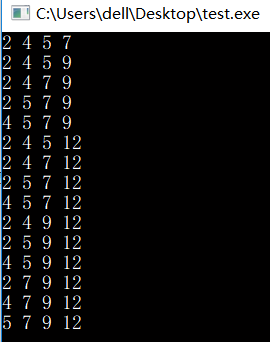
当然,有点麻烦,必须数过一次才知道1的个数,即n位二进制数必须数n次,可以减少一些复杂度。用i = i & (i - 1)可以直接定位二进制数中最低位的1的位置,跳过中间的0,并把这一位1消掉,每次消除一个1,操作次数是1的个数。如i = 7,三次操作就等于0:
1011 & (1011 - 1) = 1011 & 1010 = 1010
1010 & (1010 - 1) = 1010 & 1001 = 1000
1000 & (1000 - 1) = 1000 & 0111 = 0000
改写一下上面的代码,★★★求组合的模板:
void Combination(int n, int k) {
int tot = (1 << n);
for (int i = 0; i < tot; ++i) {
int num = 0, kk = i; //num统计i中1的个数;kk用于处理i
while (kk) {
kk = kk & (kk - 1); //清除kk中最低位的1
++num; //统计1的个数
}
if (num == k) { //二进制的1有k个, 符合要求
for (int j = 0; j < n; ++j)
if (i & (1 << j)) cout << info[j] << " ";
cout << endl;
}
}
}
四、总结
这篇文章花了我不少时间,总结了我写过的多种排列组合的代码。
总之,排列组合的代码是很多搜索问题的基础,也是模板。同时,排列组合也会涉及到计数问题,在数学类题目中有广泛的运用,必须掌握!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号