jmeter使用手册
jmeter启动
/bin目录下的jmeter.bat启动,读取是的jmeter.properties文件启动【#language=en】;ApacheJmeter.jar启动会读取系统文件,因为系统是中文系统,所以启动界面为中文
中文windows系统的中文编码是GBK,jmeter的中文编码默认是GBK
命令启动 java -jar ApacheJMeter.jar
无图形界面启动 jmeter -n -t [jmx file] -l [results file] -e -o [path to web report folder]
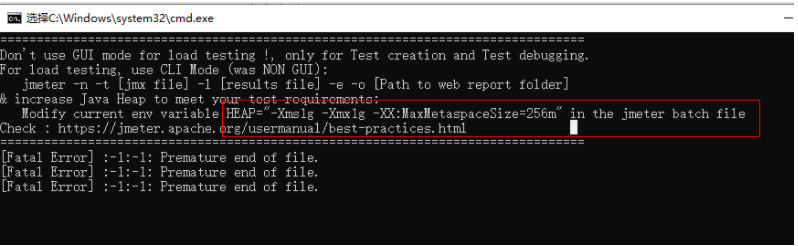
设置分配内存资源:java -Xms8g -Xmx8g -XX:MaxMetaspaceSize=2g -jar $JMETER_HOME/bin/ApacheJMeter.jar -n -t xxx.jmx -l xxxx.jtl -e -o xxdirect
修改/bin/jmeter文件内容第159行,: "${HEAP:="-Xms1g -Xmx1g -XX:MaxMetaspaceSize=256m"}",但是启动jmeter图像界面--提示语是不会改变的
编码方式
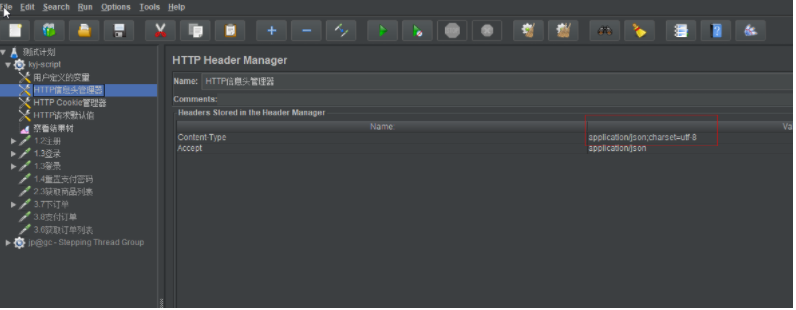
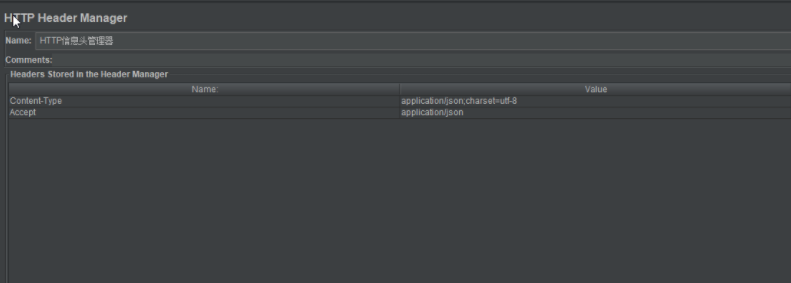
http信息头管理----Content-Type=application/json;charset=utf-8
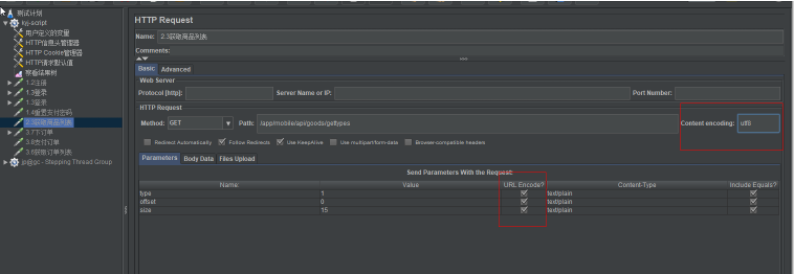
http取样器:内容编码-uft8
http内容参数:勾选编码(中文需要勾选)urlencoded编码
jmeter.properties配置文件
问题:响应报文返回值乱码?
解决:需要清楚服务器返回的编码格式,修改jmeter.properties文件中的sampleresult.default.encoding=UTF-8
jmeter工具使用
1.图形可以点击查看logcat日志面板,后面的数值,工具报错后面的数值为红色
2.0/0 前面的数值,是当前有多少个正在运行中的线程数,后面数值,是预计要启动多少个线程数

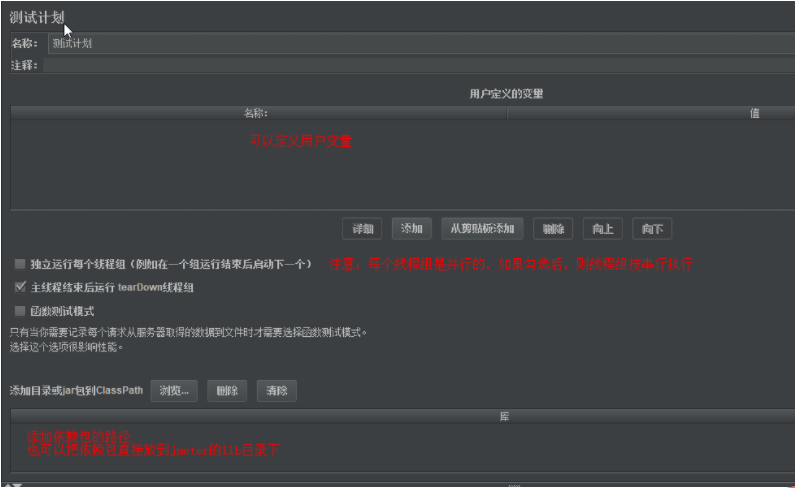
测试计划
HTTP消息头管理器---配置元件
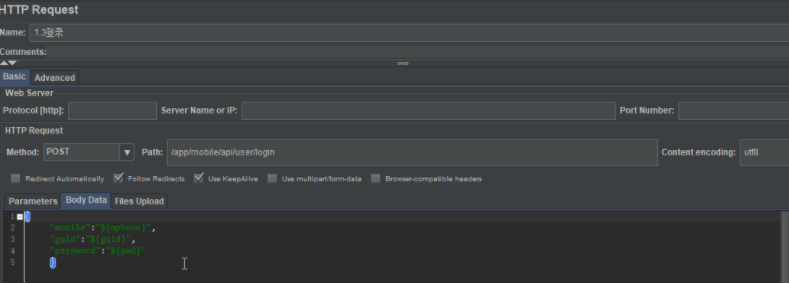
HTTP请求---取样器
-
协议是http可以不写,但是https,必须要写
-
-
请求方法:一定要看请求
-
路径:请使用/开头
-
内容编码:utf8 控制请求体中的非英文字母或者数字的值,进行utf8编码
-
消息头默认编码:application/x-www-form-urlencoded(表单格式)
-
-
自动重定向(Redirect Automatically)
-
不会记录中间过程,所以,无法提取出中间过程中需要的数据
-
-
跟随重定向(Follow Redirect)
-
默认勾选,请求会自动进行跳转到新地址上,而且会显示重定向的过程,我们可以提取出重定向过程中的数据
-
后置处理器,可以提取出定向过程中的数据
-
-
keepAlive
-
显示使用的是HTTP1.1,默认使用长链接
-
连接建立后,保持比较长的时间
-
注意:长链接--占用发起方1个端口,被测服务器使用1个连接通道,所以这个端口数量可能成为性能瓶颈(端口数量有限:1023~65535;服务器上设置系统的句柄数量)
-
解决方法:1.去掉keepalive(只是延缓了出错时间)2.修改系统的端口访问相关配置
-
-
jmeter变量
-
变量的定义与引用
[引用] ${变量名}*面试题:用户变量和用户参数的区别
-
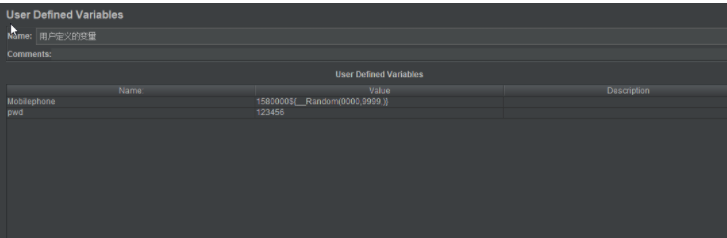
用户定义变量:全局变量,可以跨线程组被引用,在启动脚本时,获取一次值,在运行过程中,不会动态获取值
![]()
-
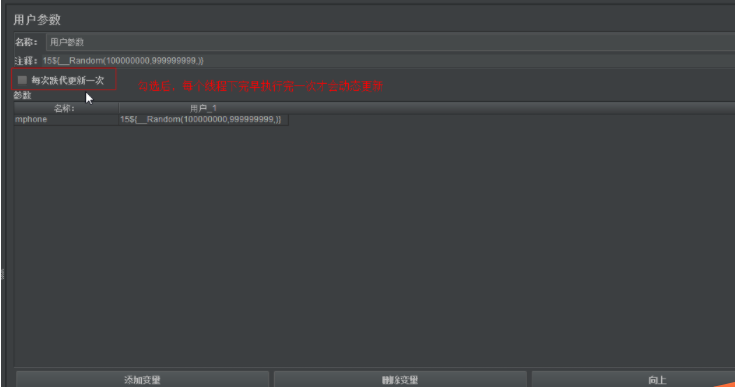
用户参数:局部变量,不能跨线程组被引用,在运行过程中,会动态获取值
![]()
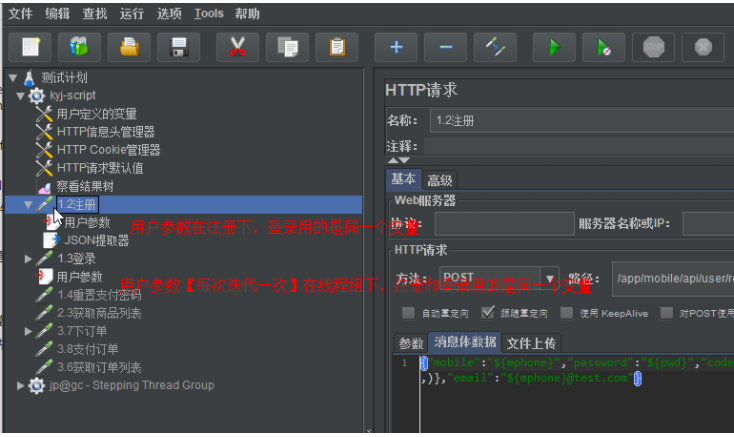
*题目:在做性能测试时,我们要注册用户,每次注册账号都不一样,然后,想要使用新注册的账号取登录,怎么让新注册的账号能登录成功?
-
把用户参数放置在注册接口下面===========符合预期
-
把用户参数放置在线程组下面,同时勾选用户参数中的【每次迭代更新一次】============符合预期
![]()
-
jmeter函数
-
Tools->函数助手
![]()
-
jmeter的函数:分两类,自带函数和扩展函数
-
自带函数:在函数助手中,可以直接使用
-
扩展函数:需要引入第三方jar包,才能在函数助手中,找到和使用;但是,这类函数,有些你找到不到帮助文档
-
-
函数:双下划线开头,函数名称,小括号,括号里面是参数,参数之间用英文逗号分隔
-
常用函数
-
__digest:自带加密算法函数
-
实现复杂的加密,就要写代码,但是不要使用beanshell 耗费性能,请使用jsr224元件(支持goovy,Java,python)
-
-
__random: 随机函数
-
__threadNum:线程的编号
-
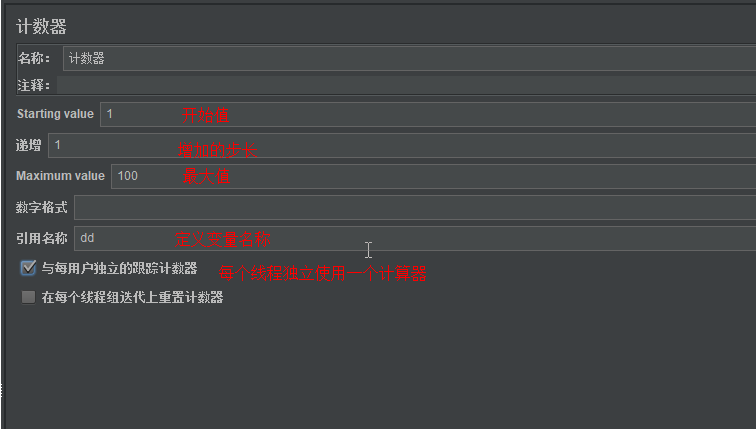
__counter:简单的数值递增函数
-
__dateTimeConvert: 时间格式转换函数
-
__RandomDate: 随机日期
-
__time: 获取当前时间戳
-
__timeShift: 时间偏移函数
-
__groovy,jexl3:运行简单代码的函数
-
__P:获取属性函数
-
__property:获取属性函数
-
__setProperty:设置属性函数
-
属性:.properties结尾的文件,都是jmeter的属性配置文件(静态属性、动态属性【jemter退出后内存会释放变量】)
![]()
-
-
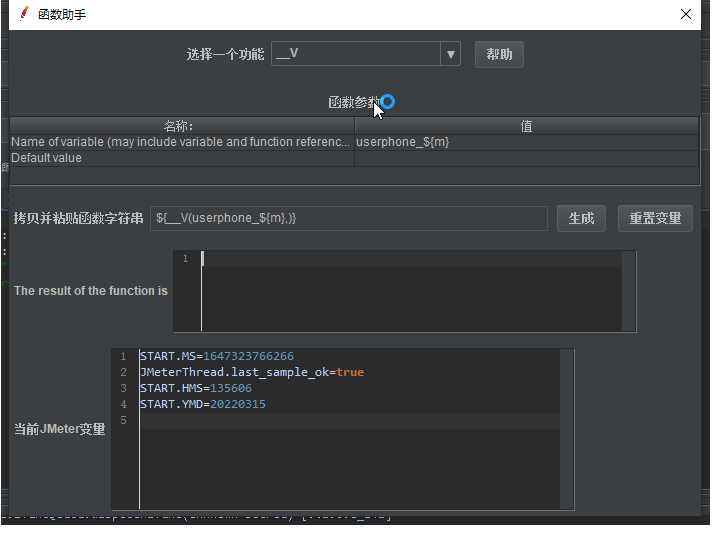
__V:变量拼接函数
-
对变量名计算,返回拼接后的变量名; ${_V(userphone${m},)}-----获取到变量${userphone_1} | ${userphone_${m}}-----失败获取不到变量
![]()
-
-
jmeter关联
-
关联:前面请求的响应动态信息,作为后续接口的传入参数,这个时候需要用关联
-
第一步:在前面的请求中添加后置处理器,提取你需要的信息(动态变化),用变量接收
-
第二步:在你要用的地方,引用前面的变量
-
-
后置处理器
-
常用的提取元件:json提取器、正则提取器
-
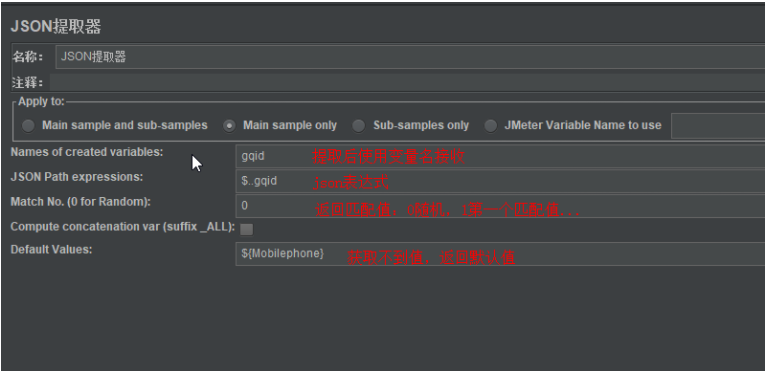
json提取器
-
json表达式提取多个
Match No:-1返回所有匹配的值;xx_matchNr=匹配的数量
-
json提取器取多个值
-
json中的key-value键值对,无序
-
在一个json提取器中,写多个json提取式用英文分号$..dd;$..cc
-
如果json提取中写了多个json提取式,此时的默认值,就必须填写,而且必须填相同数量的默认值
-
同时,也要定义相同数量的变量名jd;jk
-
Match No数量,建议填写相同数量的数值 -1;-1
-
-
Jmeter Variable Name to use: 根据填写的jmeter变量名--提取里面的值(从上个json提取结果中,进行二次提取)
-
![]()
-
正则提取器
-
左边界(正则表达式)有边界
-
正则式:(.*?)匹配除换行符外的所有字符
-
模板的固定写法:$数字$ 数字对应上面第几个(表达式)
-
-
计数器元件
CSV数据元件
-
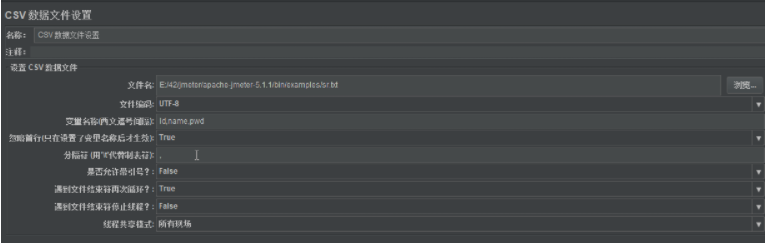
文件名:不能为空,文件【浏览】按钮,默认打开你jmx保存的地方,所以建议csv文件放在jmx脚本一起
-
建议使用txt文件
-
1.txt在中文操作系统中,默认编码是utf8,所以不会乱码,csv文件office打开保存后,默认不是utf8
-
2.txt打开时占用资源更少
-
-
文件路径:
-
相对路径:默认起始点是bin目录,在使用中,可以认为jmx文件位置作为起始点
-
相对路径起始:建议使用./sr.txt;可以跨window、linux使用
-
文件路径错误,会报错导致脚本不会执行
-
-
变量名:文件中的列对应
-
是否允许带引号:true--会自动剔除数据的一对引号
-
线程共享模式:所有线程共享--运行时会读取一次,把文件中所有内容读取到内存中;使用时,从内存中取一次值
-
遇到文件结束符再循环:true---最后一个取完后重第一个开始取;false--最后一个取完后,后面取值都是EOF
-
遇到文件结束符停止线程:true--用户取不到值就会停止用户运行,false--用户取不到值,还会运行
![]()
后置处理器
-
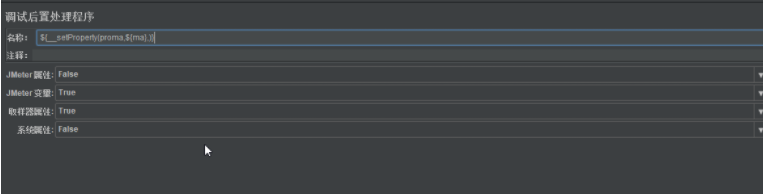
调试后置处理器(可将函数设置到名称中,下图为设置全局属性)
![]()
-
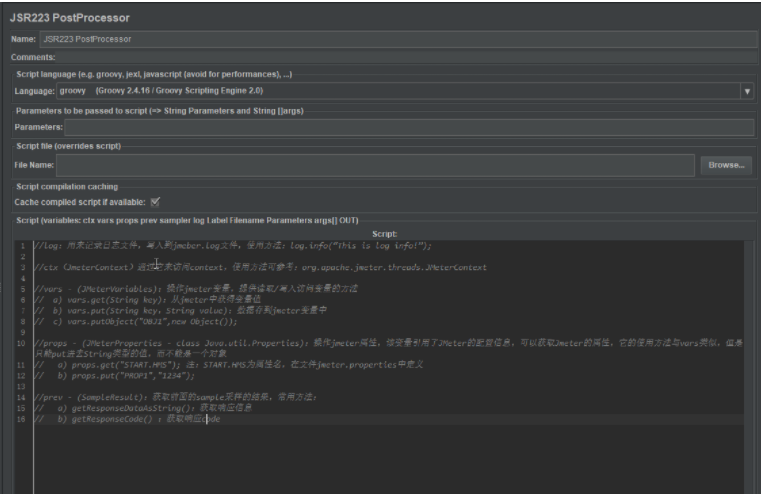
JSR223 后置处理程序
-
![]()
逻辑控制器
-
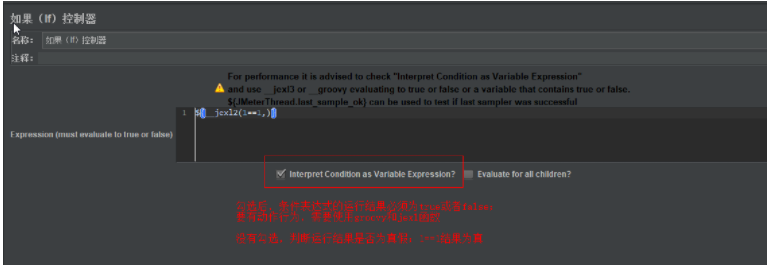
if控制器
-
![]()
-
循环控制器
-
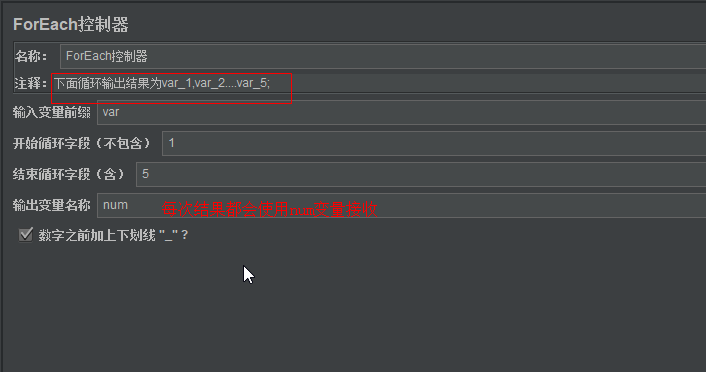
ForEach控制器
-
当我们的变量名称类似“变量名_递增的数字”我们想使用这些变量,可以使用foreach
-
-
![]()
-
仅一次控制器
-
每个线程在迭代过程中只会执行一次事务
-
例如:先登录,后执行其他操作(对登录接口做一次控制请求)
-
-
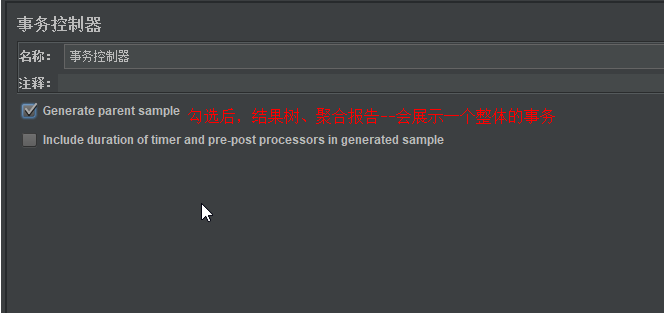
事务控制器
-
![]()
-
性能测试:先对单个接口进行性能测试,得到单接口的性能指标,然后在吧多个接口合并到一个事务下,进行模块、业务性能测试
-
jmeter中默认一个取样器执行一次请求,是一个事务
-
查看结果树
-
显示的是事务,不是取样器
-
显示顺序,已收到响应的先后顺序
-
-
聚合报告
-
聚合报告每一行,都是一次事务
-
样本就是事务的执行次数,不能直接得出并发用户数是多少
-
平均值:响应时间单位:毫秒
-
异常:标准为0.1%
-
吞吐量:性能测试中想把吞吐量tps来衡量性能指标,必须满足两个条件
-
1.并发用户数不能变---吞吐量是一个平均值,无法体现并发用户数
-
2.网络没有瓶颈
-
-
吞吐率:KB/sec
-
宽带的Mb 1B=8b
-
1Mb = 1024kb = 1024/8 KB = 128 KB/s
-
100Mb = 12800 KB/s
-
通过计算总和最大值是否接近带宽;判断是否网络瓶颈;ping命令ip测试是否有延长,丢包
-
-
-
-
临界部分控制器
-
吞吐量控制器
-
随机控制器
JDBC连接
-
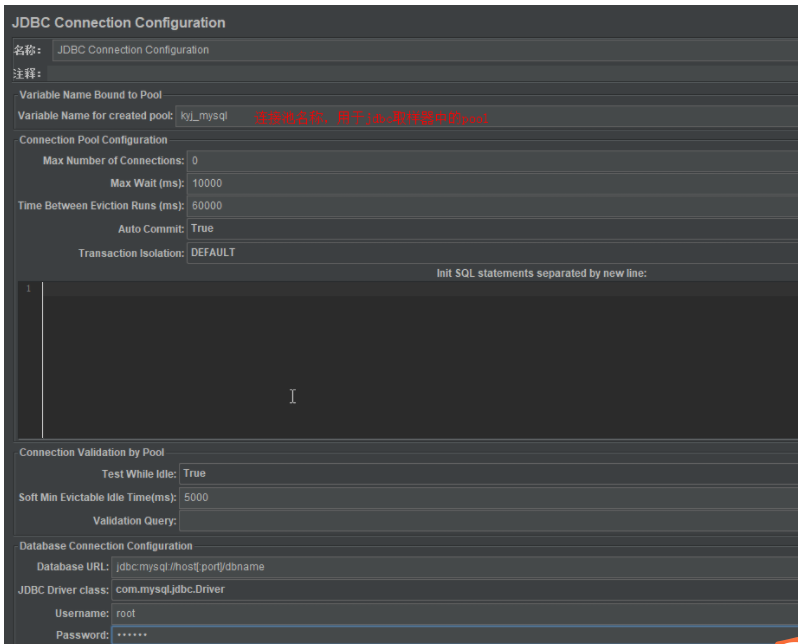
JDBC connection configuration
| 数据库 | DatabaseURL | Driverclass |
|---|---|---|
| MySQL | jdbc:mysql://host[:port]/dbname | com.mysql.jdbc.Driver |
| PostgreSQL | jdbc:postgresql:{dbname} | org.postgresql.Driver |
| Oracle | jdbc:oracle:thin:@//host:port/service 或者 jdbc:oracle:thin:@(description=(address=(host={mc-name})(protocol=tcp)(port={port-no}))(connect_data=(sid={sid}))) | oracle.jdbc.OracleDriver |
| Ingress (2006) | jdbc:ingres://host:port/db[;attr=value] | ingres.jdbc.IngresDriver |
| Microsoft SQL Server (MS JDBC driver) | jdbc:sqlserver://host:port;DatabaseName=dbname | com.microsoft.sqlserver.jdbc.SQLServerDriver |
| Apache Derby | jdbc:derby://server[:port]/databaseName[;URLAttributes=value[;…]] | org.apache.derby.jdbc.ClientDriver |
*对应的数据库驱动,要放置再jmeter的lib目录下
注意:mysql5.7版本,可以使用com.mysql.jdbc.Driver;但是8版本以上的,只能使用com.mysql.cj.jdbc.Driver
-
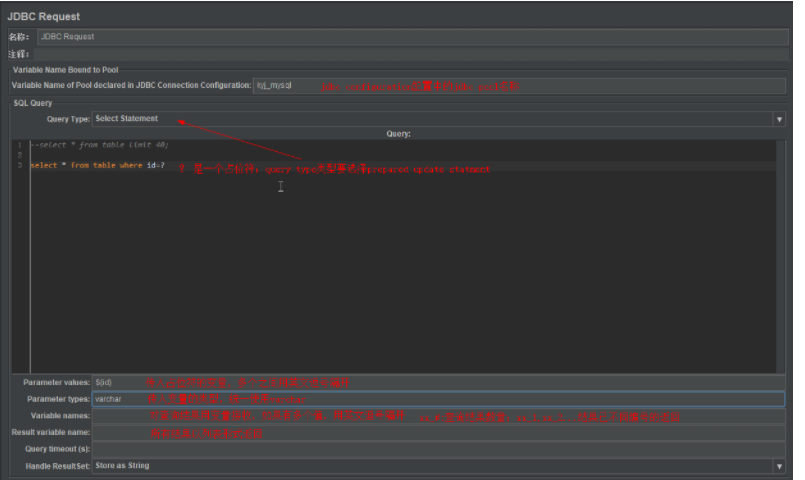
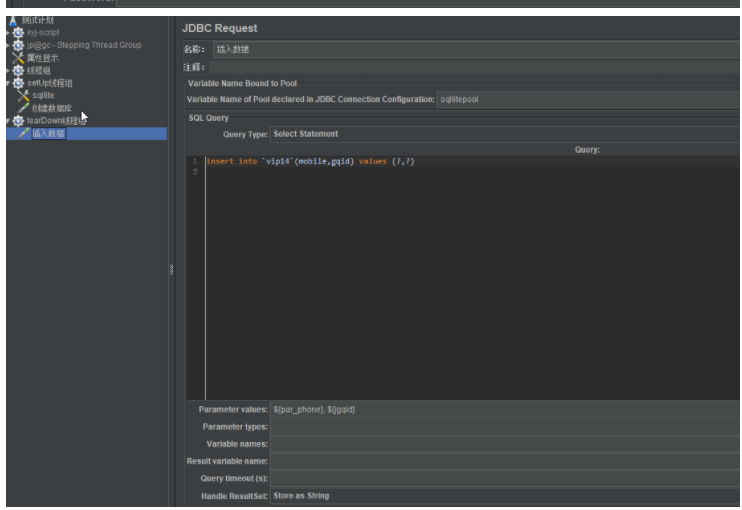
jdbc request
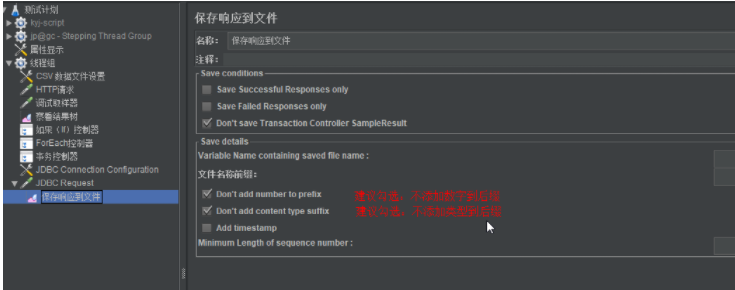
保存结果到文件
-
监听器-保存响应到文件(保存路径为jmeter的bin目录下;saved file name:文件名称)
-
![]()
-
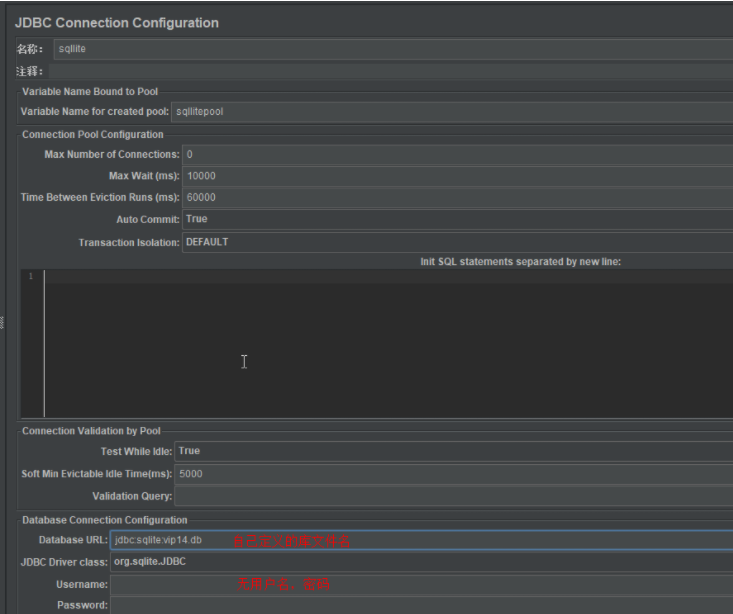
sqlite数据库:只要你的电脑有图形界面的浏览器,就有这个数据库;是一个内存数据库,不需要安装
![]()
![]()
-
jmeter元件的作用域 与 优先级
-
配置元件:最高优先级
-
常见的元件:csv配置元件,消息头管理,请求默认值,用户定义变量
-
可放置位置:测试计划下,线程组下,取样器下
-
-
发起请求元件:取样器
-
必须现有线程组下才能添加取样器
-
-
逻辑控制器:在取样器之前执行
-
要被执行,一定要有取样器
-
作用域:只会作用在它下面的取样器上
-
-
前置处理器:在取样器前执行
-
用户参数
-
可放置位置:测试计划下,线程组下,取样器下
-
-
后置处理器:对取样器执行结果进行处理
-
json提取器、正则提取器
-
-
定时器
-
可放置位置:线程组下,取样器下
-
+测试计划(相同类型的元件,从上往下执行)
-线程组
+配置元件
+逻辑控制器
+定时器
-前置处理器
-取样器
-后置处理器
-断言
-监听器
jmeter脚本-6种常用协议
soap协议:wsdl
-
soap = http + xml:http请求头+请求体用xml
-
天气预报soap接口:http://ws.webxml.com.cn/WebServices/WeatherWS.asmx?op=getRegionCountry
soap 1.1
POST /WebServices/WeatherWS.asmx HTTP/1.1
Host: ws.webxml.com.cn
--消息头
Content-Type: text/xml; charset=utf-8
Content-Length: length
SOAPAction: "http://WebXml.com.cn/getRegionCountry"
--请求参数
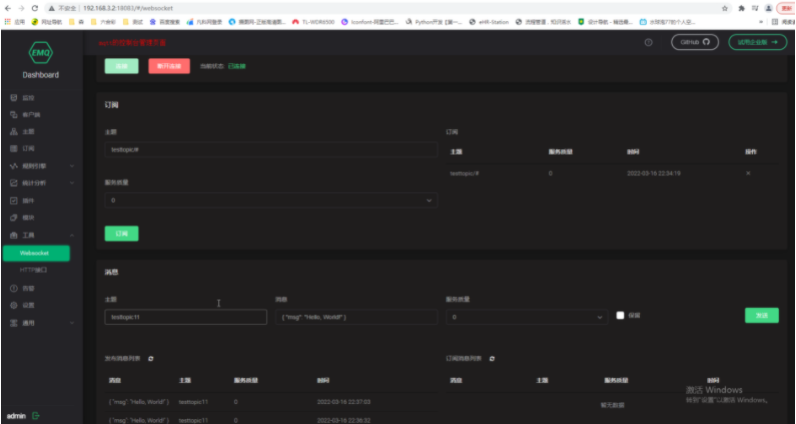
websocket协议
-
是一个基于tcp协议的全双工通信协议
-
用户端和服务端两方都可以主动发送消息
-
保活、心跳机制
-
websocket、socket、webservice
-
websocket是网络通信应用层的协议
-
socket代码与代码之间调用的协议---主要应用在游戏、微服务
-
webservice服务 ==soap服务
-
-
websocket测试服务启动
-
vir-dubbo虚拟机的/root目录下执行
sh stwebsocketserver.sh
[root@k8s-node2 ~]# sh stwebsocketserver.sh
# 启动文件
Wed, 16 Mar 2022 22:00:47 +0800 | INFO | server | | Serving using application : /usr/local/bin/python3 -m websocketdemo.py
# 端口8189
Wed, 16 Mar 2022 22:00:47 +0800 | INFO | server | | Starting WebSocket server : ws://k8s-node2:8189/ -
-
jmeter写websocket脚本
-
1.下载插件管理器jmeter-plugins-manager-1.7.jar、放置lib目录下
-
2.启动jmeter,在选项--plugins-manager安装websocket sampler by peter doornbosch插件
-
WebSocket Open Connection
-
connection:协议: ws、wss ws无加密数据传输、wss进行数据加密传输
-
-
WebSocket Single Write Sampler: 用户端向服务器端发生请求指令,但是,这个指令没有返回消息
-
connection
-
use existing connection: 使用已经建立的连接
-
setup new connection: 新建立一个连接
-
-
data
-
text: 文本
-
binary: 二进制
-
-
request data:请求体
-
-
WebSocket Single Read Sampler:用户端读取服务器的指令执行结果
-
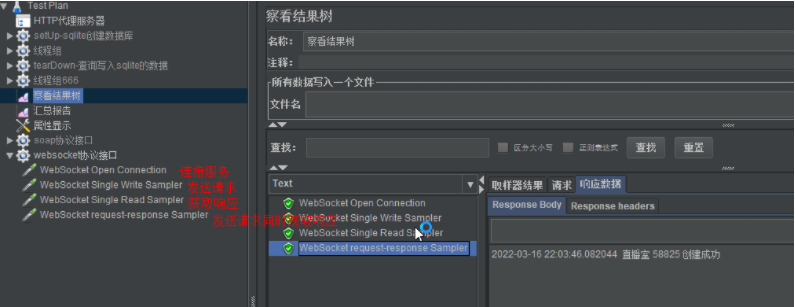
WebSocket request-response Sampler: 用户端向服务器端发请求,然后读取执行结果
-
MQ:消息队列
-
mqtt: 一个国内开源的项目
``| 端口 | 说明
``| 1883 | MQTT / TCP 协议端口可以被外部访问
``| 11883 | MQTT / TCP 协议内部端口只能当前机器自身访问
``| 8883 | MQTT / SSL 协议端口
``| 8083 | MQTT / WS 协议端口
``| 8084 | MQTT / WSS 协议端口
``| 18083 | MQTT / HTTP 协议端口, HTTP管理台访问端口,用户名admin,密码public
-
启动mq服务
# vir-dubbo虚拟机
[root@k8s-node2 ~]# cd /root
[root@k8s-node2 ~]# sh stmqttserver.sh
● emqx.service - emqx daemon
Loaded: loaded (/usr/lib/systemd/system/emqx.service; enabled; vendor preset: disabled)
Active: active (running) since 三 2022-03-16 21:37:00 CST; 33min ago
Process: 993 ExecStart=/bin/sh /usr/bin/emqx start (code=exited, status=0/SUCCESS)
Main PID: 1451 (run_erl)
Tasks: 32
-
如何性能测试
-
发布者一般发送一条消息,多个消费者获取信息;性能瓶颈在消费者
-
所以一般对模拟多个消费者获取信息的压力测试
-
-
plugins-manager安装MQTT Protocol Support
-
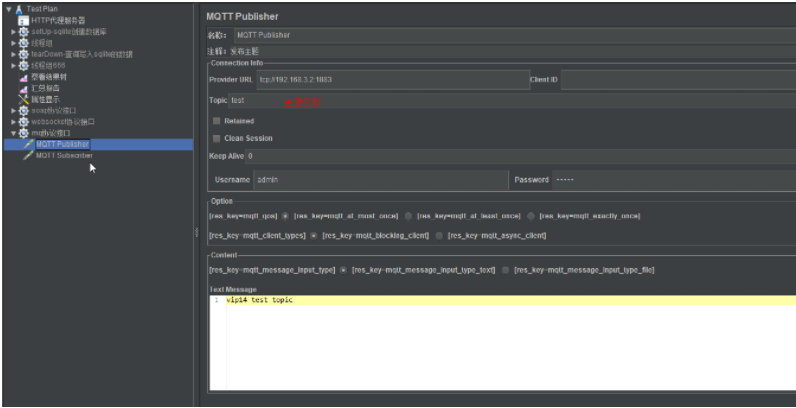
MQTT Publisher:发布主题
-
MQTT Subscriber:消费主题
-
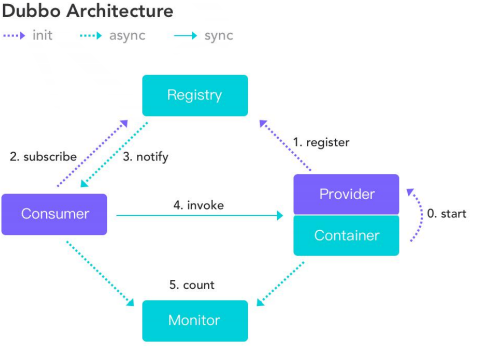
Dubbo协议
Dubbo 是一款高性能、轻量级的开源 java RPC 框架,它提供了三大核心能力:面 向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
-
启动dubbo服务
[root@k8s-node2 ~]# cd ~
[root@k8s-node2 ~]# sh stdubboserver.sh
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... no zookeeper to stop (could not find file /tmp/zookeeper/zookeeper_server.pid)
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
./service.sh: 第 25 行:kill: (2341) - 没有那个进程
=== stop futureloan-member-service
=== futureloan-member-service process stop success
=== start futureloan-member-service
./service.sh: 第 25 行:kill: (2372) - 没有那个进程
=== stop futureloan-member2-service
=== futureloan-member2-service process stop success
=== start futureloan-member2-service
-
jmeter测试dubbo服务
-
把jmeter-plugins-dubbo-2.7.3-jar-with-dependencies.jar 放到jmeter的lib/ext文件夹下面重启jmeter
-
引入这个包之后,jmeter启动会变慢,在不适用dubbo协议的时候,把jar移除出去
-
-
添加Dubbo取样器
-
registry setting注册中心设置
-
Protocol :选择项目中使用的zookeeper注册中心
-
Address:ip:20181
-
-
interface setting接口设置
-
点击【Get Provider List】按钮
-
弹窗中点击yes
-
Interface:显示刚获取的接口信息
-
Method:显示刚获取的方法信息
-
Args:根据dubbo接口文档,填写参数
-
-
-
普通性能场景
jmeter默认使用1g的内存资源,一般的情况,一台电脑,发起http请求,大概能虚拟出2000以内的并发用户数
2000,只是说能产生这么多的线程数,并不代表,这些人的请求就一定成功;
一旦,你的项目,并发用户数,要超过2k,就使用 分布式
产生100以内的并发用户数,差不多用1-2s就可以了;100-500左右,ramp-up时间2-3s就可以;500以上 5-10s就可以
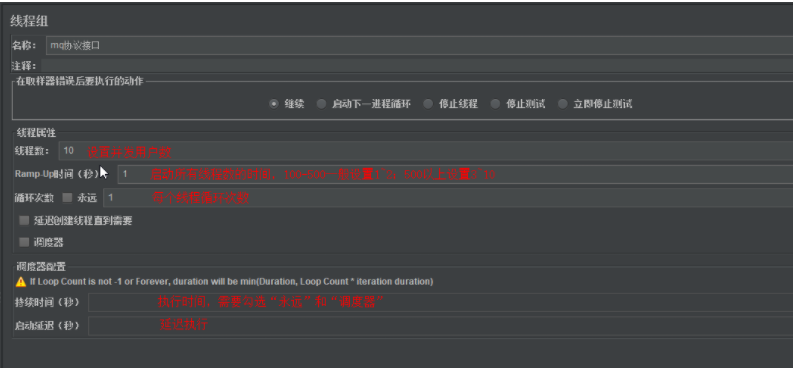
性能场景设计
引入插件jpgc,插件管理 > available plugin 搜索 jpgc空格, 勾选,点击 apply changes and restart
负载场景-jp@gc - Stepping Thread Group
Stepping Thread Group 阶梯线程组,逐步增加并发用户数-----负载测试
next add 10 threads every 30 seconds, using ramp-up 5 seconds,
每5s增加10个 持续运行30
then hold load for 60 seconds
是线程全部启动完成后 持续运行60S
负载测试场景设计,坚持一个原则,缓起步,快结束
# 监听器
Active Threads Over Time: 随着时间变化的活跃线程数图
Response Times Over Time: 随着时间变化的响应时间图-------类似于心电图
Transactions per Second: TPS
# 如何判断最大可接受的并发用户数?
1、看tps是否有连续性的报错,如果有,说明,**已经出问题了**,我们就需要来分析是否有性能问题。那么此时,的并发用户数,很可能已经超过最大可接受的并发用户数。
2、看平均响应时间线是否操作1.5s----现在我们的系统 能接受的最大并发用户数区间在30-40之间
3、看tps有没有明显下降趋势
预估 并发用户数和tps
# 粗略计算并发用户数
+ 粗略的算一下,50个并发用户数的情况
+ 假设,50个人,每个人1秒钟,发1个请求-------请求频率为1 我假设了tps为1
+ 那么1秒钟总共请求50次
+ 1分钟 50*60= 3000次
+ 1小时 3000*60 =180000次 18w次
+ 1天 18w*24h = 432w次 假设就是请求注册接口, 那就是说注册接口1天的请求量是432w次
+ 生产环境中,产品日均访问量是多少?
+ 假设,我们生产环境日均访问量少于432w, 假设tps=1,那么我们的生产环境并发用户数小于50的
# 二八原则计算
+ 二八原则: 80%的请求发生在20%的时间里
+ 假设我们的生产环境日均访问量 在500w
+ 500w0.8=400w
+ 24\*0.2\*3600=17280s
+ tps= 400w/17280= 232tps
+ 顺带: 我们生产有多少在线用户,我们的并发用户数,大概是在线用户的5%-10%(行业经验)
也就是说 生产如果在线用户有1000人,我们的并发用户数,可能只有50-100人
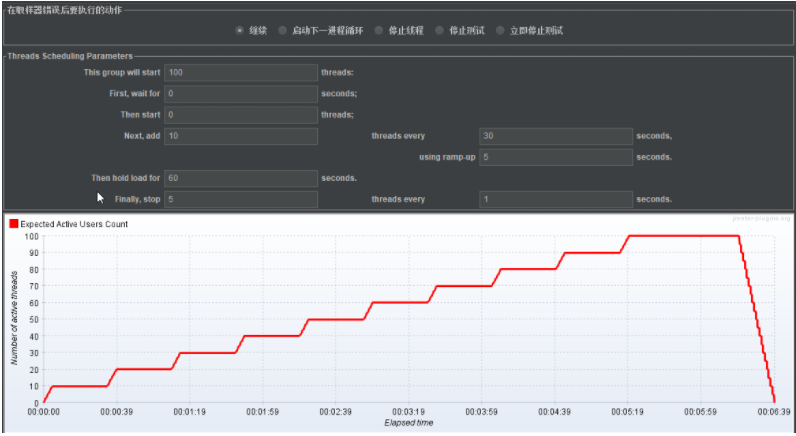
+ Active Threads Over Time
``+ 看相同用户数的一段时间
+ Response Times Over Time 响应时间
``+ 在相同用户的一段时间内,看响应时间的平均线是多少
``+ 看在多少并发用户数的那一段时间内,我们的平均响应时间的线,超过1.5s秒,这个时候,我们的并发用户数,就已经超过了我们最大可接受的并发用户数了。
``+ 1.5s是怎么来的呢?
``+ 这个是因为,我们做的是接口的性能测试,http协议的接口性能测试中,行业的标准是1.5s是用户可接受的界限,超过了就不能接受。
``+ 1.5s在jmeter中,有一个apdex用户满意度指数
+ Transactions per Second TPS图
``+ 看tps中,在多少并发用户数时,出现连续性的失败,此时的并发用户数,超过我们可接受的最大并发用户数。
``+ 我们第一反应是服务器处理不过来而失败。
``+ 但是,也需要具体问题具体分析
``+ 如: Address already in use: connect
``+ 或: connect refused
``+ 或: connect timeout
``+ 这些报错,大多都是你发起方电脑配置的问题
``+ tps出现明显下降趋势,也说明这个时候的并发用户数,已经超过最大可接受的并发用户数
``+ tps的线,一般情况是,随着并发用户数增加,tps的趋势是上升或平缓,出现明显下降趋势,说明出现拐点
+ 看tps和平均响应时间两的判断结果。
``+ 假设: 60个并发用户数的时候tps连续报错,40个并发用户数时,平均响应时间已经超过1.5s
``+ 最终得到最大并发用户数: 小于40的
``+ 假设: 30个并发用户数的时候tps连续报错,40个并发用户数时,平均响应时间已经超过1.5s
``+ 最终得到最大并发用户数: 小于30的
聚合报告:
每一行,代表一种事务
我们判断的已经是行业的平均标准是接口的平均响应时间1.5s
90%: 在总的样本中,有90%的请求样本,的响应时间小于等于这个时间
如果90%的时间小于1.5s,说明,产品的响应时间大多小于1.5s产品是比较稳定。
异常率:行业标准是 小于等于0.1
什么时候才能看聚合报告中的数据?
两个前提条件: 并发用户数不变 + 网络没有瓶颈
11KB/s
1Mb = 12.8KB/s
面向目标场景
达到多少tps:bzm - Arrivals Thread Group
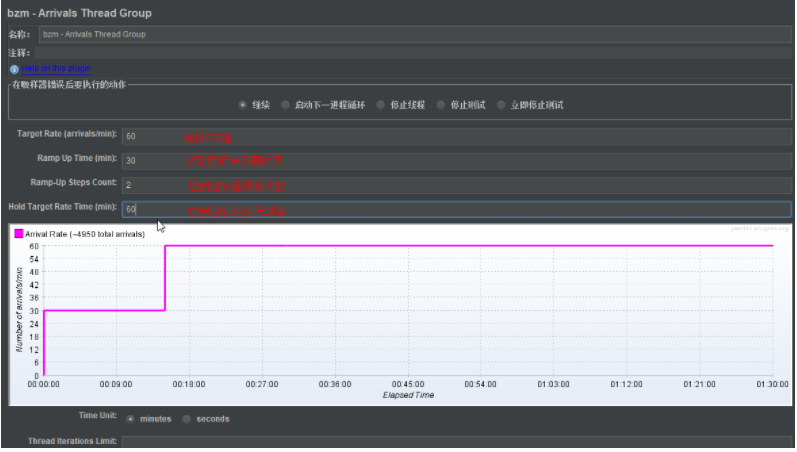
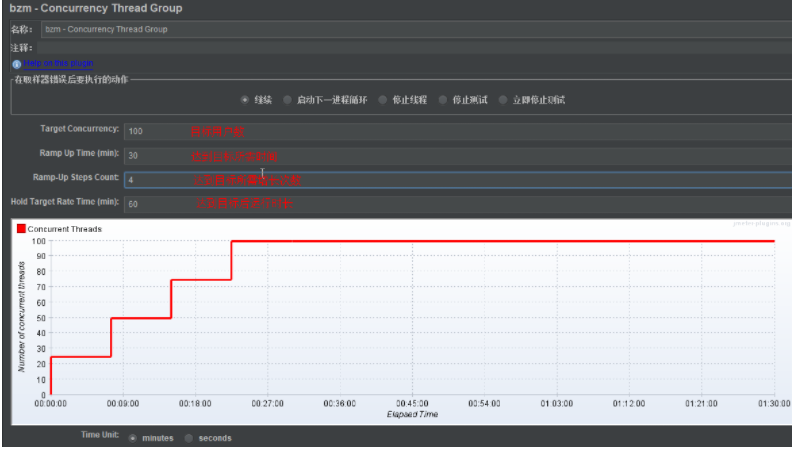
达到多少用户并发数:bzm - Concurrency Thread Group
+ 假设: 需要验证,接口是否能支持1000个并发用户数
+ 类似秒杀的需求(2000)
+ 1、2000线程数,运行1--------这个是不准确(但是没有经验的人一般这么设计)
+ 2、真正的2000线程数,循环运行一段时间(几十秒到几分钟)
+ target Concurrency :目标多少并发用户数T
+ ramp-up:用多长时间M
+ ramp-up step count: 次数N
+ 我用M时间内,我有N次调整的机会,来灵活调整并发用户数,看我们的系统是否能支持T这个目标并发用户数。
下图:我用30s的时间内,有4次灵活调整并发用户数的机会,来测试服务器,看服务器能否支持100并发用户数的目标。
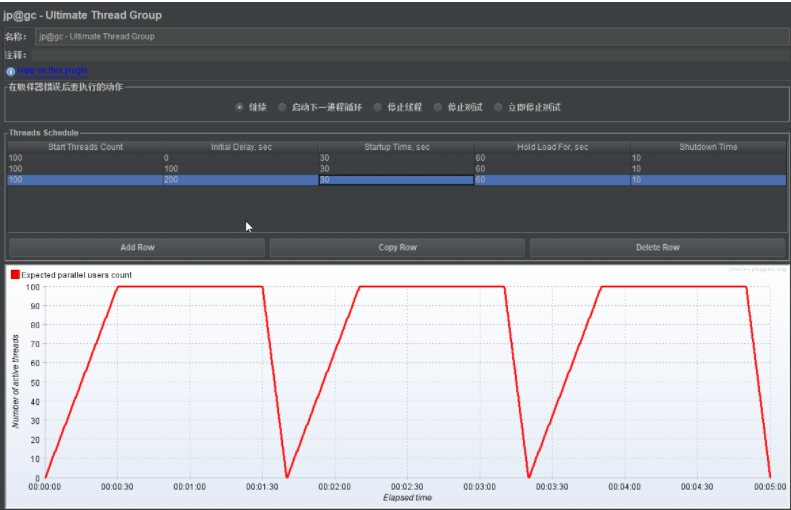
时间规律场景-jp@gc - Ultimate Thread Group
+ 有时间规律Ultimate Thread Group终极线程组
+ 初始化延迟时间(Initial Delay): >= 上一行所有时间之和(Initial Delay + Startup Time + Hold Load For + Shutdowm Time)
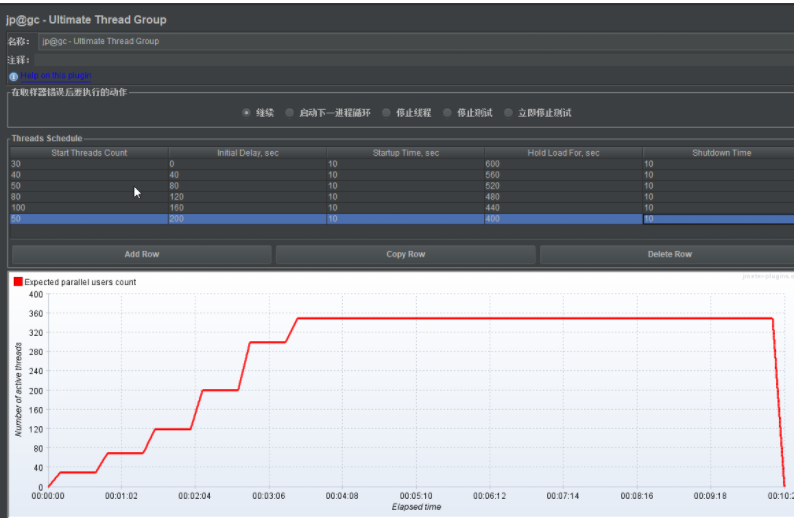
思考题目: 用Ultimate Thread Group 这个线程组去设计一个阶梯线程组负载测试场景。
Stepping Thread Group用这个设计的负载测试场景,每次的递增步长都是相等的。
设计思路:
初始化时间(Initial)= 上一行的初始化的时间initial delay + 启动时间starttime时间 + 你期望它运行时间
持续运行时间(Hold )= 上一行的所有时间之和,减去,当前这一行的时间之和
混合场景
不同数量的并发用户数,使用不同的接口,向服务器同时发起请求。
-----要使用多个线程组
-----多个线程组之间,默认是并行执行
-----多个线程组之间,参数值是不能直接跨线程组别调用的
要跨线程组被调用,需要用 属性 、文件嫁接法
日均访问量 500w 估算最终得到是tps
10%访问量在 注册接口 ===tps
30%访问量在 登录接口 ==tps
50%商品访问 接口上 ==tps
10% 下单 接口 ==tps

 浙公网安备 33010602011771号
浙公网安备 33010602011771号