K_Means聚类算法的研究与改进
数据挖掘通常被称为数据中的知识发现
数据挖掘的方法有很多,包括决策树分析、分类、聚类、关联规则、预言、估值、可视化等等。
聚类分析(Clustering Analysis)又被称作群分析它是一种统计的分析方法,是指将抽象的集合划分成为由类似的对象组成的对象类(即簇)的一个过程。
主要包括:基于划分的聚类算法,基于层次的聚类算法,基于密度的聚类算法、基于网格的聚类算法和基于模型的聚类算法。

我们把聚类称作一种观察式的学习方式而不是示例式的学习方式。在很多实际应用中,它通常作为数据预处理的关键步骤,是进行分析和处理数据的基础。
在开始聚类之前,用户并不知道要把数据划分成几类,也不清楚分组的标准。在有些聚类算法中,如K-Means算法需要事先给出聚类的数目值,而这个值是凭用户的经验所得。
1974年Everitt给出了关于聚类的如下定义:相似的实体在同一个类簇中,不同的实体在不同的类簇中,并且位于同一个类簇中的任意点之间的距离要小于不同类簇中的任意点的距离。根据聚类的相关定义,可以得到它的形式化描述如下:


proximity:接近,距离。
数据类型:
1.区间标度变量。
2.二元变量。布尔变量(权重相同的是对称的二元变量如男女性别,权重不同的是不对称二元变量,如疾病的阴性阳性)。
3.标称变量:标称变量也被称为分类变量,它属于一种二元变量。标称变量可以取多于两个状态的值(如红绿灯三个状态)。
4.序数变量:与标称变量最大的区别就是他的序数是有意义的,如部门的等级排序(1.连续序数变量2,离散序数变量)。
5.复合类型变量。
6.向量对象变量
 没太明白。
没太明白。
数据结构(将对象进行存储)
数据矩阵(Data Matrix) p个变量表示n个对象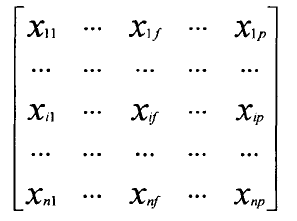
相异度矩阵(Dissimilarity Matrix):对象-对象结构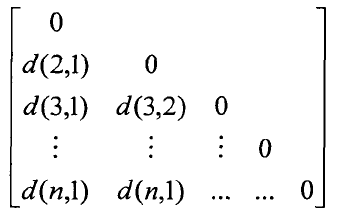
其中,d(i,j)表示对象i与j对象之间的相异度。通常,d(i,j)是一个非负值,对象i与对象j之间越相似,其值越接近于0;
两个对象越不同,其值越大。因为d(i,j)=d(j,i),并且d(i,j)=0,因此相异度矩阵中的对角线上的值全为0。
数据标准化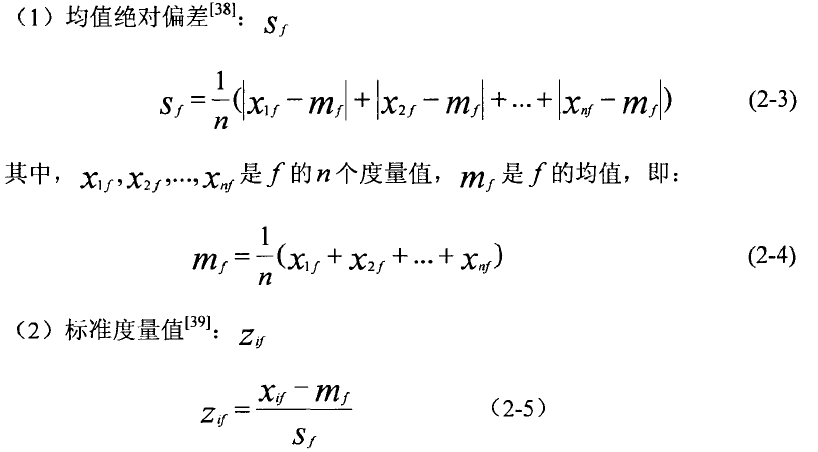 (2)表示Xif在整个数据中离中间的偏差程度。
(2)表示Xif在整个数据中离中间的偏差程度。
相似度
1.区间标度度量
通常,描述区间标度变量对象间的相似度(或相异度)利用的是对象之间的距离进行计算。
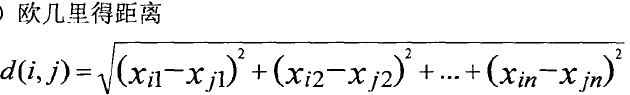
加权欧几里得距离![]()
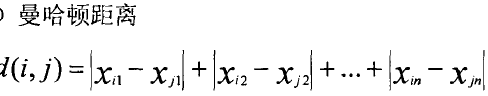
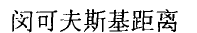
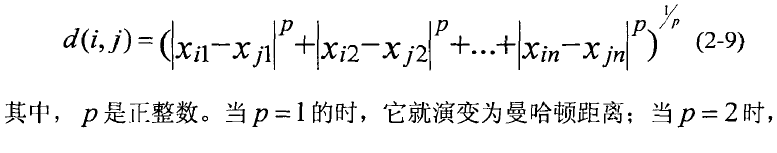
2.二元变量
两种度量方法:
非对称二元相异度和对称二元相异度。这两种度量方法都是基于相依表来描述的。
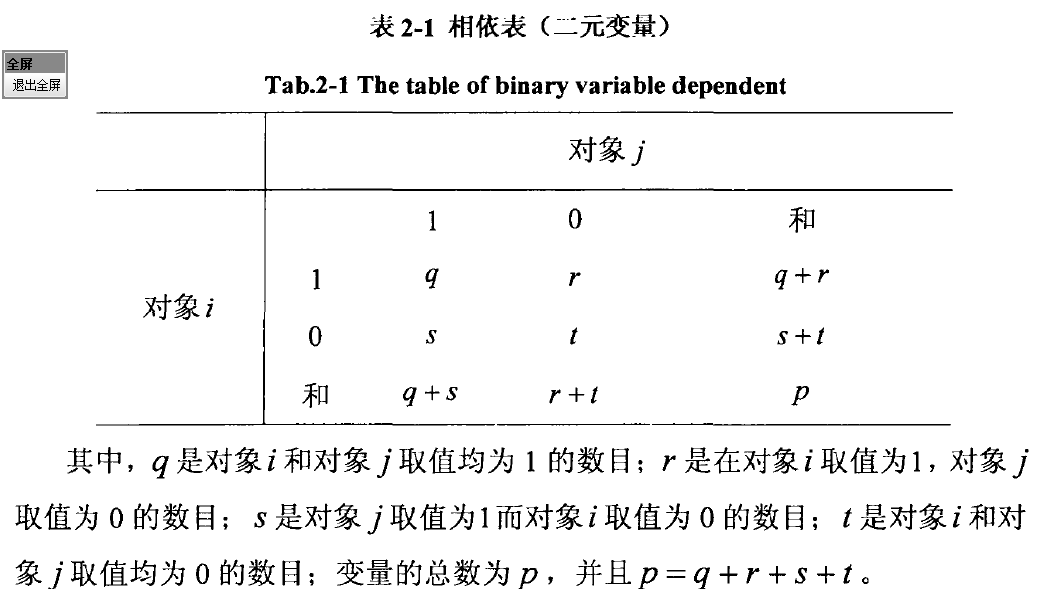
(1)对称二元相异度(具有相同的权重)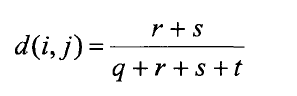
(2)非对称的二元相异度(两个都取值为的称为负匹配,而两个都取值为的情况称为正匹配。因为对于非对称的二元变量,正匹配较之负匹配的取值更加的有意义,因此,这样的二元变量经常被认为“一元的”,即只有一个状态。)相异度为 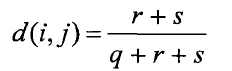 相似度jaccard系数记为
相似度jaccard系数记为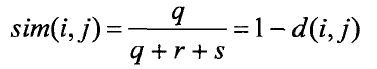
3.标称变量
可以根据不匹配率进行计算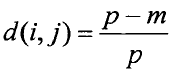 m是匹配的数目,即对象i和j取值相同状态的数目;p代表全部数目的变量。
m是匹配的数目,即对象i和j取值相同状态的数目;p代表全部数目的变量。
4.序数变量
的相异度
不懂!!
5.复合类型变量(有两种方法)
(1)将变量按照类型进行分组,对每种类型的变量进行单独的聚类分析。然而,在实际应用中,不同类型变量的聚类分析产生兼容的结果的可能性很小。
(2)对所有类型的变量进行一次聚类,即将所有类型的变量一起处理。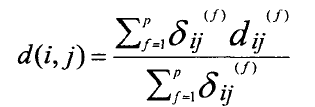 不太懂!
不太懂!
6、向量对象变量
使用余弦来进行度量向量对象变量的相似度有一个变种 不太懂!
不太懂!
准则函数(有两种方式)
聚类分析还需要一定的准则函数才能将同一类的数据聚成一类,从而把不同类的样本分离幵来。
1.基于试探的方式:此方式基于主观或经验或实际的问题来定义一种相似性测量的阈值,然后基于最近邻规则来指定一些对象属于某一聚类。
2.聚类目标函数法:定义一个对象集合和聚类类别的函数,称之为聚类目标函数J。于是,聚类分析问题就转化为如何来寻找目标函数极值的最优化。有三种公式:
(1)误差平方和准则:

(2)加权平均平方距离和准则:
![]()
![]()

(3)类间距离和准则:
它是用来描述不同的类之间的分离程度,一般有下面的两种定义:

聚类步骤:数据准备、特征选取、特征提取、聚类、聚类结果评价。具体分析步骤如下:
(1)提取特征:取特征的结果就是输出一个矩阵,矩阵中的行与列分表代表着“行代表一个样本,列代表特征指标变量”。
(2)标准化数据处理:统一量纲、降维(特征变量太多)、主成分分析并消除变量间的相关性。
(3)选择合适的聚类算法。
(4)选择合适的相似度度量和准则函数。
(5)执行聚类算法:???
(6)得到聚类结果:对聚类结果知识的新认识和利用。
评价标准:
1.算法要能适用在大的数据量集中。
2.算法要能处理不同的数据类型。
3.算法要可以发现不同类型的类。
4.算法要降低对专业知识的要求。
5.算法可以处理任何脏数据。
6.算法要降低对数据的顺序和类型的敏感度。
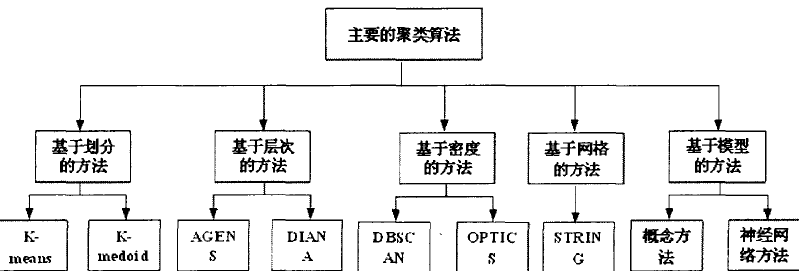
基于划分的聚类方法概述:


典型的划分聚类方法:
基于质心技术的划分聚类方法 和 基于代表对象技术的划分聚类方法 K-means和K-Medoid算法。
1。 2。
2。
3。 K-means算法采用的准则函数是平方误差和。
K-means算法采用的准则函数是平方误差和。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号