万字复盘 | 从SFT到PPO:如何用强化学习拯救大模型幻觉?(附避坑指南)
本文约 12000 字,⏱️ 阅读时间:约 25 分钟
🏷️ 关键词:RLHF、PPO、大模型幻觉、Text-to-SQL、工程实战。
👋 给新读者的话:
如果你对"强化学习""PPO"这些词有点陌生——别担心,这篇文章专门为你准备了「前置知识」章节,用5分钟讲懂核心概念,保证你能看懂80%的内容。
如果你是开发者,可以直接跳到「一分钟速览」或「Golden Config」看实战干货。
读者导航:
- 只关心结果/配置:直接看「一分钟速览 → Golden Config → 故障排查表」
- 想复现 RL 训练直觉:看「LunarLander 热身(可跑 demo)」
- 想把 RLHF 真正落到业务:看「Router 方案 → 数据/环境 → 端到端评估」
本文:不讲虚的,只讲我怎么踩坑、怎么定位、怎么改进。

先讲一个真事:大模型很自信,但它“路痴”
好不容易搭了个项目系统助手 Agent,随口问一句:
"查一下海外某项目的合同变更记录"
我们接入的通用大模型(当时用的是 Qwen-72B 一类)非常自信地生成查询:直接查 contract_change_log,再用项目名过滤。
结果:空(查无数据)。
为啥?因为在我们的业务数据库里,"项目"和"变更记录"并没有直接关联。这货直接跳过了 project → contract → change_log 的关联路径。
就好比你问路,它告诉你"往前走就到",但压根没提中间得先过一座桥。
大模型很聪明,但它不懂你家业务数据库的"交通规则"。 它会"幻觉"出看似合理但实际无法执行的查询路径。
这种问题,Prompt 调了几十版也没彻底解决。
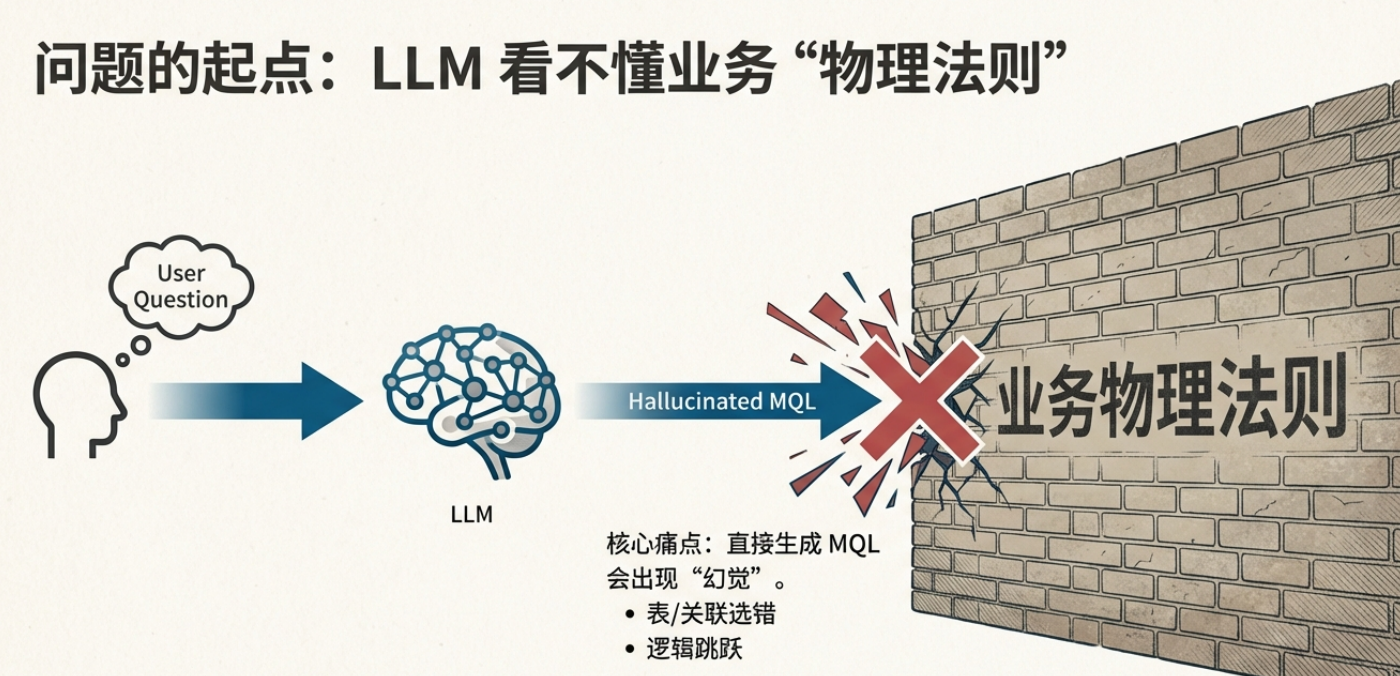
后来我们换了个思路:不让它直接生成查询,先让它学会"认路"。
前置知识:5分钟看懂这篇文在讲什么(小白必读)
📖 写给小白读者:如果你对"强化学习""PPO"这些词有点陌生,先看这一节。如果你是开发者,可以跳过直接看「一分钟速览」。
用一个故事讲懂什么是"强化学习"
想象你在训练一只小狗:
| 训练小狗 | 强化学习训练AI |
|---|---|
| 给它看动作:坐下、握手 | 让AI尝试输出:查询路径A |
| 做对了→给零食(奖励) | 路径正确→得分+10(奖励) |
| 做错了→不给零食(惩罚) | 路径错误→得分-5(惩罚) |
| 小狗学会:做动作有零食吃 | AI学会:输出正确路径能得分 |
强化学习 = 让AI在环境中试错,通过奖励和惩罚自己学会最优策略。
核心术语速查表(遇到不懂的词就回来看)
📖 点击展开:10个核心术语一图看懂
| 术语 | 一句话解释 | 生活类比 |
|---|---|---|
| PPO | 一种强化学习算法,全名"近端策略优化" | 开车时小幅修正方向盘,别猛打 |
| RLHF | 用人类反馈做强化学习训练 | 像教练一样指导AI,而不是让它自己瞎练 |
| SFT | 监督式微调,给AI看标准答案让它模仿 | 像学生背课本,记住"这道题答案是什么" |
| KL散度 | 衡量两个策略差异的数字 | 新老策略的"距离",差太远就刹车 |
| Actor | 负责做决策的模型 | 司机,负责开车 |
| Critic | 负责打分的模型 | 教练,负责说"你刚才开得怎么样" |
| Value Loss | 预测分数和实际分数的差距 | 你以为能考90分,实际考了60分,这差距就是Loss |
| Reward Hacking | 模型学会钻奖励函数的空子 | 老师说"写满字就给分",学生疯狂抄作业凑字数 |
| 策略崩塌 | 模型训练到一半突然变笨了 | 学着学着把之前学的都忘了 |
| vf_coef | 控制Critic影响力的参数 | 教练说话的分量,太大就把司机带偏了 |
这篇文章在解决什么问题?
用一张图概括:
┌──────────────────────────────────────────────────────┐
│ 问题:大模型写查询时"走错路" │
│ ───────────────────────────────────────────────── │
│ 用户问:"查项目合同变更记录" │
│ 模型想:直接查 contract_change_log 表 ❌ │
│ 实际:要 project → contract → change_log 三跳 ✅ │
└──────────────────────────────────────────────────────┘
↓
┌──────────────────────────────────────────────────────┐
│ 方案:加一个"认路层"(Router) │
│ ───────────────────────────────────────────────── │
│ 第一步:Router 先输出"从哪张表,经过哪些表,到哪张表" │
│ 第二步:Generator 按这个路径生成具体查询 │
└──────────────────────────────────────────────────────┘
↓
┌──────────────────────────────────────────────────────┐
│ 训练:用强化学习让 Router 学会认路 │
│ ───────────────────────────────────────────────── │
│ SFT(背课本):先教会它"这道题答案是什么" │
│ PPO(练实战):让它在环境中试错,学会"为什么走这条路" │
└──────────────────────────────────────────────────────┘
💡 读完这一节,你已经掌握了看懂这篇文章的80%密码。接下来可以按需阅读:
- 赶时间?看「一分钟速览」
- 想玩代码?看「LunarLander 热身」
- 想学原理?跟着章节顺序读
一分钟速览(赶时间看这一段就够了)
| 关键点 | 一句话 |
|---|---|
| 问题本质 | Text-to-MQL 里最难的不是写语法,是选对"多跳路径" |
| 方案 | 加一个 Router:先输出 (Anchor, Target, Via),再交给生成器按路写查询 |
| 冷启动 | 先 SFT 再 PPO,否则前 ~20k steps 基本在瞎蒙,正奖励几乎拿不到 |
| 稳定性 | PPO 必须保守:低 lr + 低 vf_coef + 严 KL 熔断 +(必要时)冻结 backbone |
| 奖励设计 | 不做反作弊,模型会钻空子:动态加权 + 条件发放 |
最终效果:
- 路由准确率:35% → 89%(提升 53%)
- 端到端执行成功率:80% → 90%
如果你也在做 RL 微调,或者被 PPO 训练崩溃折磨过,往下看。
一、问题拆解:为什么大模型会"走错路"?
我们做的是 Text-to-MQL(自然语言转mongodb数据库查询)。
大模型直接生成查询时,常见翻车可以粗暴分三类(这里是我们线上的高频占比观测):
| 失败类型 | 例子 | 占比 |
|---|---|---|
| 表选错 | 该查项目表,它去查合同表 | ~40% |
| 路径断裂 | 跳过中间关联表,直接查目标表 | ~35% |
| 语法对但结果空 | 运行没毛病,但业务上查不到东西 | ~25% |
这类问题不是"模型不会写查询",而是它不懂你业务 Schema 的物理法则。
SFT(监督微调)能教会它"这道题的答案是什么",但教不会它"为什么必须走这条路"。
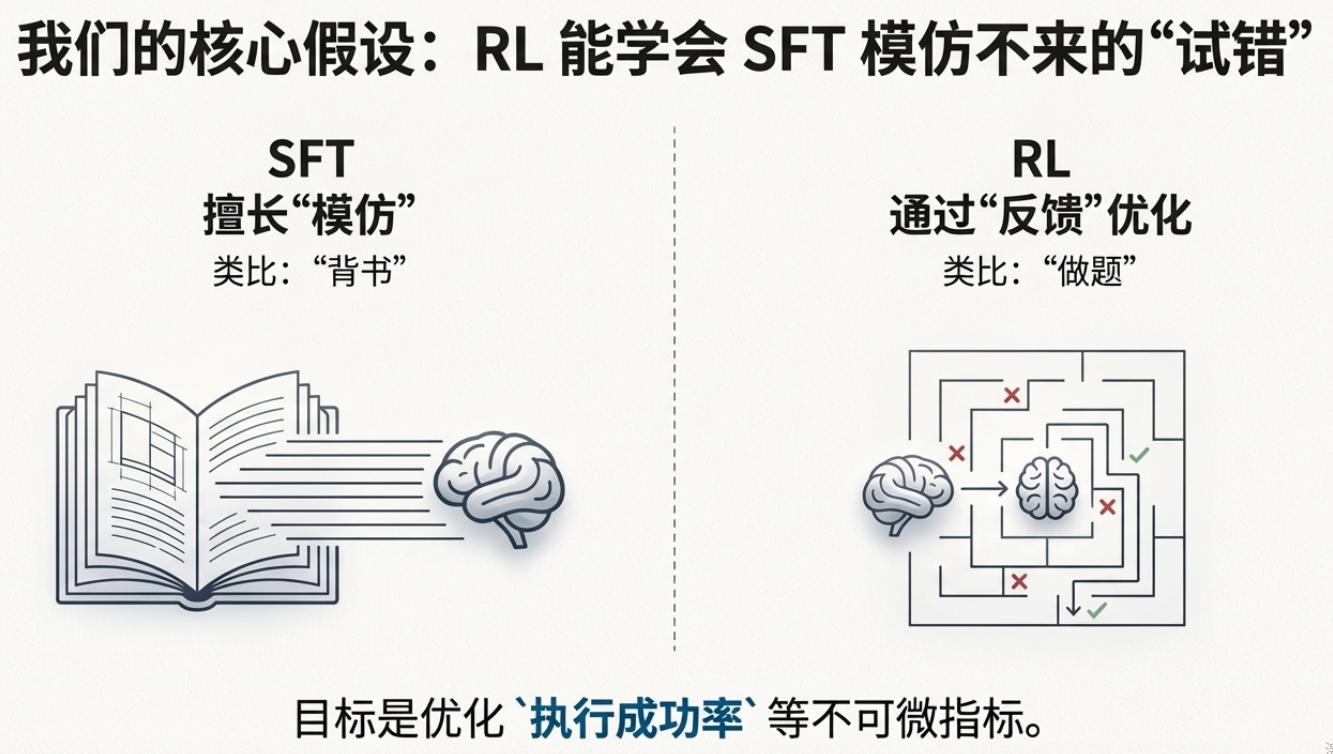
我们的技术假设:
SFT 擅长"模仿分布",但在强约束逻辑任务存在上限。引入环境反馈(RL Reward)后,模型可通过试错优化不可微目标:合法路径、执行成功率、低空结果率。
📖 小白看这里:什么是"不可微目标"?
可微目标 = 可以用数学公式求导的目标(比如预测准确率,模型可以直接计算梯度来优化)
不可微目标 = 不能直接求导的目标(比如"查询能不能成功执行",只有试了才知道,没法直接算梯度)
强化学习的作用:让AI通过试错来优化那些没法直接算梯度的问题。
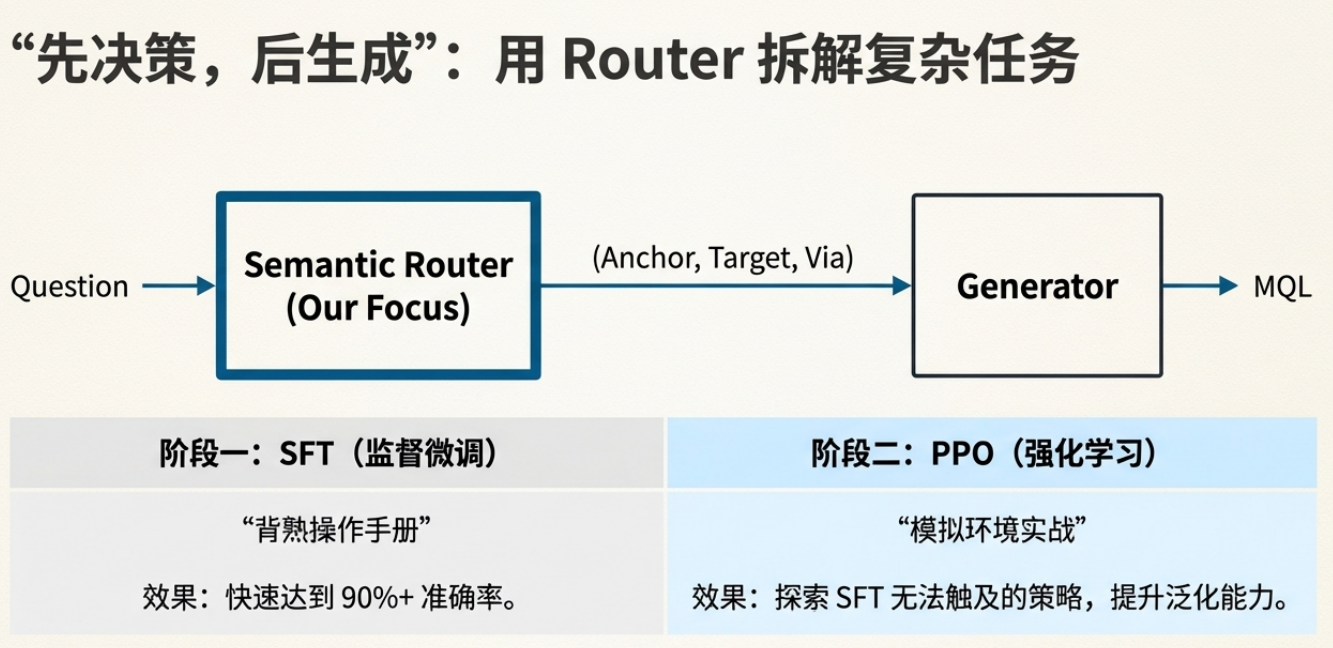
二、我们的方案:先"认路",再"开车"
与其让大模型一步到位生成查询,不如拆成两步:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────┐
│ 用户问题 │ ──▶ │ Router 模型 │ ──▶ │ Generator │ ──▶ 查询结果
│ + Schema 信息 │ │ 输出路径三元组 │ │ 生成 MQL │
└─────────────────┘ └─────────────────┘ └─────────────┘
Router 只做一件事:告诉后面的生成器"走哪条路"。
输出就三个字段:
- Anchor:从哪张表出发
- Target:最终查哪张表
- Via:中间要经过哪些表(可以为空)
早期验证:路由层真的有用吗?
在正式开干之前,我们先做了个小规模 A/B 测试:
| 方案 | $lookup 场景准确率 | 空查询数 |
|---|---|---|
| Baseline(直接生成) | 80/100 (80%) | 20 |
| 注入路由约束 | 95/100 (95%) | 5 |
结论很清楚:路由决策层对执行质量有直接贡献。
这给了我们信心:方向对了,值得继续投入。
三、RL 热身:用 LunarLander 建立直觉(附可跑代码)
在正式上强化学习训练落地讲解之前,我强烈建议先用游戏环境练练手。不是为了炫技,是为了建立直觉——理解 RL 的反馈循环到底是怎么回事。
3.1 为什么推荐 LunarLander?
这是 HuggingFace Deep RL Course 的入门环境,优点是:
- 状态空间小、训练快(几分钟就能看到效果)
- 奖励信号直观(落地成功 +100,坠毁 -100)
- 方便你亲手调 Reward,体会"奖励设计"的威力
3.2 动手实践指南
Step 1:跑通官方 Demo
👉 HuggingFace 官方教程:你可以直接用的 HuggingFace 官方 hands-on
这个 Notebook 可以直接在 Colab 跑,10 分钟内你就能看到一个小飞船学会降落。
Step 2:尝试自己改 Reward
官方 Demo 用的是环境默认奖励。但真正的 RL 工程,核心就是设计你自己的奖励函数。
我写了一个可配置的 Reward Wrapper,你可以用它来做对比实验:
📦 点击展开:可配置奖励的 LunarLander 代码
# 可配置奖励包装器
from dataclasses import dataclass
import numpy as np
import gymnasium as gym
@dataclass
class RewardConfig:
# 势能型稠密项(基于状态)
w_distance: float = 0.0 # 距离着陆区的负权(越近越好)
w_velocity: float = 0.0 # 速度幅值的负权(越慢越好)
w_angle: float = 0.0 # 姿态角度的负权(越正越好)
w_legs: float = 0.0 # 腿接触正项(每条腿 +1)
# 推进器代价(离散动作:0无操作,1左侧推,2主推,3右侧推)
penalty_main: float = 0.0
penalty_side: float = 0.0
# 是否替换原始 reward
replace_reward: bool = False
scale: float = 1.0
class RewardShapingWrapper(gym.Wrapper):
"""
记录奖励分量到 info['reward_components']
可选地以自定义加权合成为新的 reward
"""
def __init__(self, env: gym.Env, config: RewardConfig):
super().__init__(env)
self.cfg = config
def _decompose(self, obs: np.ndarray, action) -> dict:
x, y, vx, vy, angle, v_angle, l_leg, r_leg = obs[:8]
return {
"distance": -float(np.sqrt(x*x + y*y)),
"velocity": -float(np.sqrt(vx*vx + vy*vy)),
"angle": -float(abs(angle)),
"legs": float((l_leg > 0.5) + (r_leg > 0.5)),
"pen_main": float(action == 2),
"pen_side": float(action in [1, 3]),
}
def step(self, action):
obs, reward, terminated, truncated, info = self.env.step(action)
comps = self._decompose(obs, action)
shaped = (
self.cfg.w_distance * comps["distance"]
+ self.cfg.w_velocity * comps["velocity"]
+ self.cfg.w_angle * comps["angle"]
+ self.cfg.w_legs * comps["legs"]
- self.cfg.penalty_main * comps["pen_main"]
- self.cfg.penalty_side * comps["pen_side"]
) * self.cfg.scale
info["reward_components"] = {**comps, "env_reward": reward, "shaped": shaped}
if self.cfg.replace_reward:
reward = shaped
return obs, reward, terminated, truncated, info
# 配置1:仅记录,不改变原始奖励
log_only = RewardConfig()
# 配置2:自定义奖励(鼓励稳、慢、省油)
custom_cfg = RewardConfig(
w_distance=100.0,
w_velocity=150.0,
w_angle=50.0,
w_legs=10.0,
penalty_main=0.3,
penalty_side=0.03,
replace_reward=True,
)
# 分别训练,对比 GIF 效果
import imageio.v2 as imageio
from stable_baselines3 import PPO
ENV_ID = "LunarLander-v2"
TOTAL_STEPS = 200_000
SEED = 42
def make_env(cfg, render_mode=None):
env = gym.make(ENV_ID, render_mode=render_mode)
return RewardShapingWrapper(env, cfg)
def train_and_save(cfg, model_path):
env = make_env(cfg)
model = PPO("MlpPolicy", env, verbose=0, seed=SEED)
model.learn(total_timesteps=TOTAL_STEPS)
model.save(model_path)
env.close()
def record_gif(cfg, model_path, gif_path, max_steps=1000, fps=30):
env = make_env(cfg, render_mode="rgb_array")
model = PPO.load(model_path, env=env)
obs, _ = env.reset(seed=SEED)
frames = [env.render()]
for _ in range(max_steps):
action, _ = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
frames.append(env.render())
if terminated or truncated:
break
env.close()
imageio.mimsave(gif_path, frames, fps=fps)
# 方案A:默认奖励(仅记录)
train_and_save(log_only, "ppo_default")
record_gif(log_only, "ppo_default", "ppo_default.gif")
# 方案B:自定义奖励
train_and_save(custom_cfg, "ppo_custom")
record_gif(custom_cfg, "ppo_custom", "ppo_custom.gif")
用上面的代码,你就可以对比"默认奖励" vs "自定义奖励"两种奖励策略下小飞船的强化学习训练效果了。
3.3 这一步的核心收获
通过这个热身,你会建立几个关键直觉:
| 直觉 | 说明 |
|---|---|
| Reward 决定行为 | 你设计什么样的奖励,模型就往什么方向优化 |
| 稠密 vs 稀疏 | 只给终点奖励(稀疏)学得慢,过程奖励(稠密)学得快但容易被 hack |
| 反馈循环 | Env.step() → Reward → Update → Env.step()... 这个循环是 RL 的核心 |
📌 Key Takeaway:RL 的难点不是写模型,是写环境与奖励。
3.4 不同RL算法下lunarlander的效果对比
用上面的代码,我们还对比了四种不同的RL算法训练策略在相同训练steps下lunarlander的训练效果。:
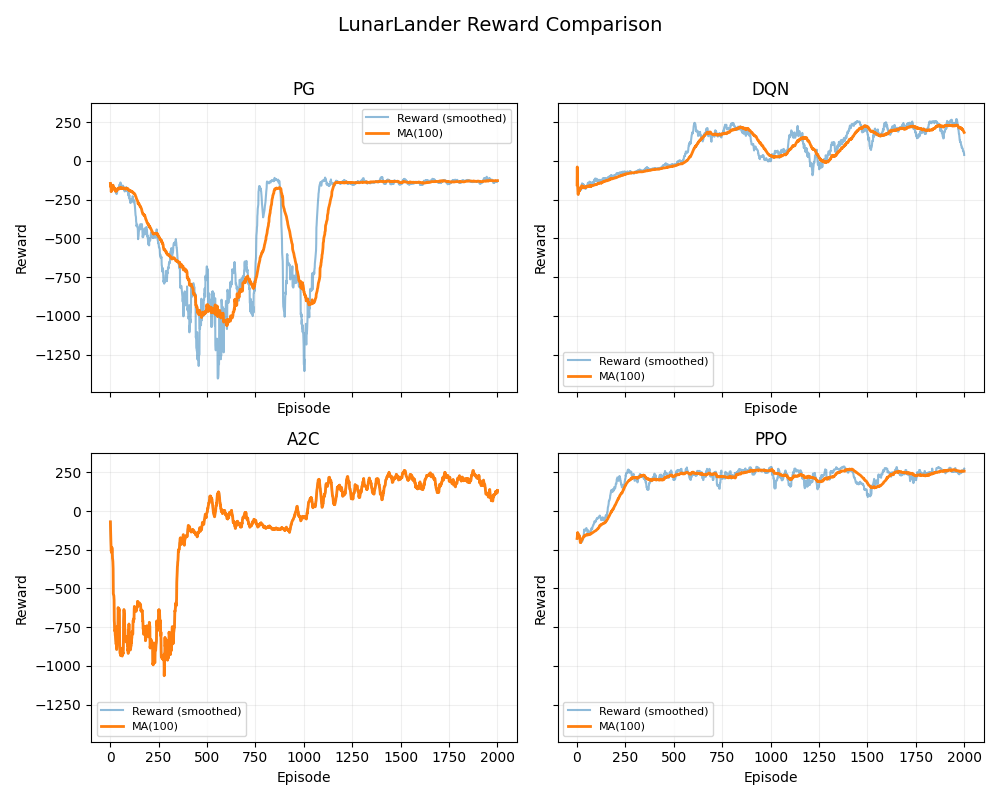
直观感受:不同的强化学习训练算法,训练出来的模型风格也是完全不同。
四、数据与环境:我们构建的"物理世界"
RL 训练离不开一个靠谱的环境。我们花了不少精力在这一块。
4.1 业务物理法则(动作空间边界)
| 维度 | 数值 | 说明 |
|---|---|---|
| 核心 Schema | 12 张表 | Project/Contract/Delivery/Construction… |
| 合法路径 | 42 条 | 脚本穷举,Router 动作空间上界 |
为什么要穷举?减少无效探索,把 Schema 约束变成可学习信号。
4.2 数据流水线
种子生成(Gemini) → 语义增强(Qwen-72B) → 实体填充(Qwen-72B) → 566条样本
↓ ↓ ↓
42路径×3种子问题 按难度分级采样 60%真实/40%模糊
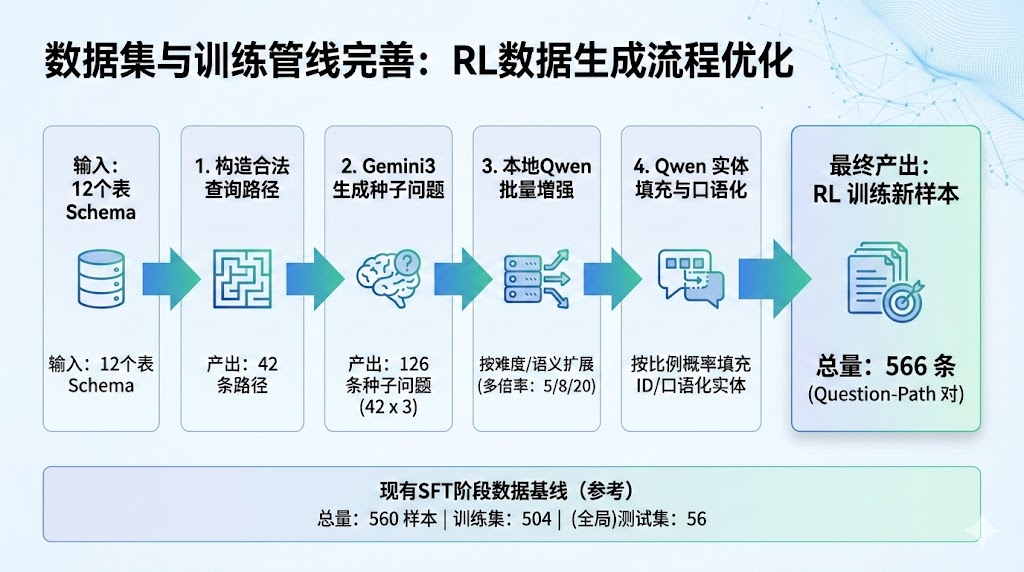
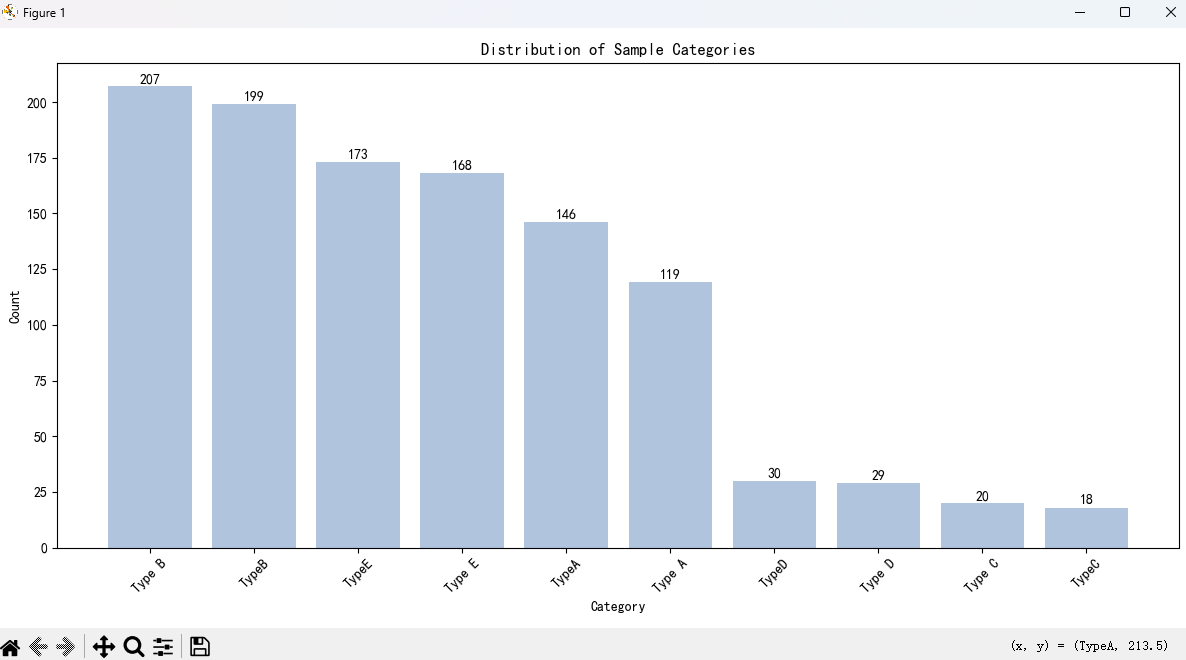
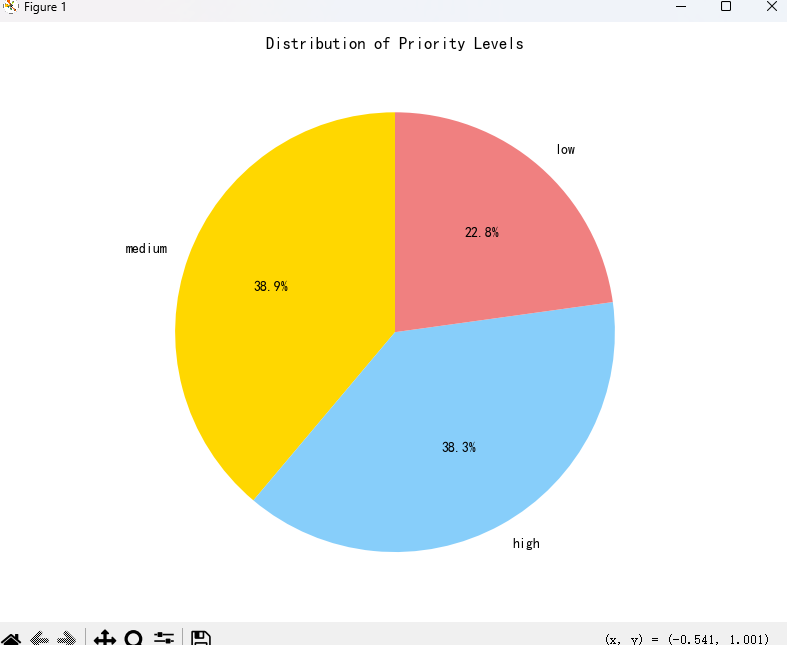
4.3 数据分布(直接影响 Reward 策略)
| 类别分布 | 优先级分布 |
|---|---|
 |
 |
4.4 环境建模
💡环境基于真实业务逻辑构建,包含以下三个核心组件:
| 组件 | 描述 |
|---|---|
| Schema 信息 | 12 张表的结构定义与外键关系 |
| 路径规则 | 42 条合法路径的校验逻辑 |
| 执行反馈 | 路径匹配度、语法正确性、结果有效性 |
五、两阶段训练:SFT 冷启动 + PPO 强化
5.1 为什么需要 SFT 冷启动?
这是我踩的第一个大坑。
一开始我想:既然最终要用 RL,能不能直接 RL 起手?
结果是:前 2 万步,模型基本在"瞎蒙",几乎拿不到有效的正奖励。
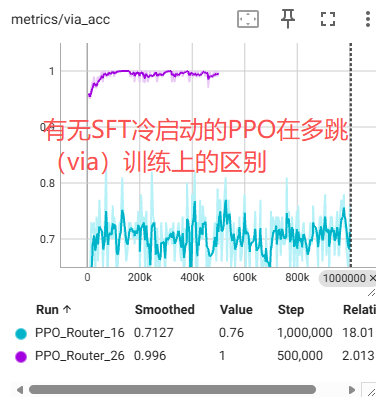
原因很简单:动作空间虽然不大(42 条合法路径),但随机探索命中正确答案的概率太低了,尤其是多跳场景。
正确姿势:
- Phase 1(SFT):先把准确率拉到一个可用起点(比如接近 80%)
- Phase 2(PPO):在 SFT 基础上做策略优化
用一个比喻来说:
先让实习生背熟操作手册,再让他在模拟环境中实战。
换个角度理解:
| 学习阶段 | SFT(背课本) | PPO(练实战) |
|---|---|---|
| 像什么 | 像学生背公式 | 像做实验题 |
| 学什么 | 记住标准答案 | 理解为什么这么做 |
| 能应对 | 做过的题型 | 没见过的新题型 |
| 局限 | 题目变了就懵 | 需要大量试错 |
💡 Trick:如果 Base-RL 效果想更进一步,可以先用 base-RL 拒绝采样一批样本,对 Base 模型做简单冷启动微调,再继续 RL。
5.2 SFT vs RL:工程视角对比

SFT 和 RL 的本质区别:
| 场景 | SFT 局限 | RL 优势 |
|---|---|---|
| 对齐人类偏好 | 难以标注"什么是好回答" | 只需打分即可训练 |
| 优化不可微指标 | BLEU/ROUGE 无法反向传播 | 任意指标可作为 Reward |
| 探索能力 | 只能模仿训练数据 | 能发现训练集没有的好策略 |
5.3 模型架构:三头分类 + 一个 Value Head

关键设计决策:
| 决策 | 理由 |
|---|---|
| 部分冻结 Backbone | 防止 RL 初期梯度破坏预训练特征 |
| 三头独立 | 与 SFT 结构一致,可直接加载权重 |
| 共享 Backbone | 减少参数,但 Critic 梯度会回传(⚠️ 坑点) |
💡 Trick:初始化 PPO 时,Critic 模型的权重应该从 SFT 模型加载,而不是随机初始化。随机初始化的 Critic 是策略崩塌的主要元凶之一。
5.4 基座模型选择
| 阶段 | 基座模型 | 效果 | 备注 |
|---|---|---|---|
| 初期 | chinese-roberta-wwm-ext |
✅ 可行 | 中文语义理解能力强 |
| 后期 | Qwen-0.5B-Instruct | ✅ 更优 | 指令遵循能力更强 |
微调建议:推荐使用 LoRA 方式进行微调,仅更新少量参数(~1%)即可注入领域知识。
六、策略崩塌:PPO 训练的噩梦
6.1 现象描述
训练到中后期,你会看到这些信号同时出现:
准确率:97% → 15% → 8%
KL 散度:0.02 → 0.15 → 0.35 (飙升)
Value Loss:剧烈震荡
模型"学傻了"。
📖 小白看这里:KL散度和Value Loss是什么意思?
KL散度 = 新策略和旧策略之间的"距离"
- 如果KL散度很小(0.02):说明策略变化不大,还在可控范围
- 如果KL散度飙升(0.35):说明策略变化太剧烈,模型可能"学歪了"
- 类比:就像开车时,小幅修正方向盘没问题,但猛打方向盘就会失控
Value Loss = Critic(打分教练)预测的分数和实际分数的差距
- Loss低:教练预测准,说明训练稳定
- Loss剧烈震荡:教练自己都搞不清楚状况,训练肯定出问题
- 类比:就像考试前你估分90分,实际考了30分,说明你对题目理解有偏差

6.2 根因分析
PPO 训练时有四个关键组件:
┌─────────────────────────────────────────────────────────┐
│ PPO 四模型架构 │
├─────────────────┬─────────────────┬─────────────────────┤
│ Actor (新策略) │ Actor (旧策略) │ 用于计算 ratio │
├─────────────────┼─────────────────┼─────────────────────┤
│ Critic (价值) │ Reward (奖励) │ 用于计算 Advantage │
└─────────────────┴─────────────────┴─────────────────────┘
问题出在 Actor 和 Critic 共享 Backbone:
Actor = SFT 预训练"高手"
Critic = 随机初始化"新手"
↓
共享 Backbone 下,Critic 为拟合 value 产生大梯度
↓
污染语言特征 → 触发灾难性遗忘
简单说:新手 Critic 把老司机 Actor 带沟里了。
用生活场景理解:
想象一个老司机(Actor)带一个新手教练(Critic)练车:
┌─────────────────────────────────────────────┐
│ 正常情况(Critic 权重低): │
│ ──────────────────────────────────────── │
│ 老司机开车 → 新手教练打分 → 老司机参考调整 │
│ 结果:老司机主导,新手教练慢慢学会打分 │
└─────────────────────────────────────────────┘
┌─────────────────────────────────────────────┐
│ 崩溃情况(Critic 权重过高): │
│ ──────────────────────────────────────── │
│ 老司机开车 → 新手教练瞎指挥 → 老司机被带偏 │
│ 结果:老司机的经验被污染,两个人一起迷路 │
└─────────────────────────────────────────────┘
6.3 Golden Config:稳定训练的配方
经过无数次实验,我总结出一套"保守优先"的配置:
| 参数 | 激进配置(会崩) | 保守配置(稳定) | 为啥这么改 |
|---|---|---|---|
| learning_rate | 3e-4 | 1e-6 ~ 5e-6 | PPO 的 lr 要比 SFT 小一个数量级 |
| vf_coef | 0.5 | 0.01 ~ 0.1 | 压住 Critic,别让它带偏 Actor |
| clip_range | 0.2 | 0.1 ~ 0.15 | 限制每次更新的幅度 |
| target_kl | 0.1 | 0.02 ~ 0.05 | 策略差异太大就熔断 |
| n_epochs | 10 | 2 ~ 4 | 同一批数据别反复学 |
| 冻结层数 | 0 | 前 10 层 | 物理隔离,保护语言能力 |
| batch_size | 小 | 宁大勿小 | 大 batch 梯度更稳定 |
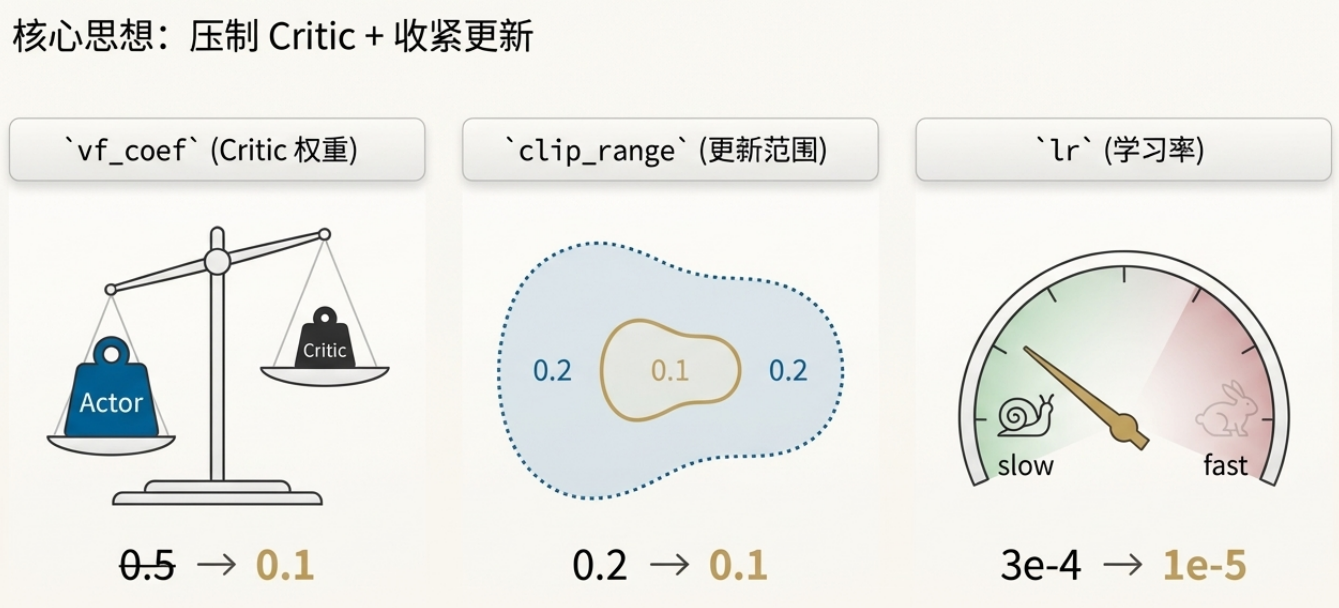
📖 小白看这里:这些参数都是什么意思?
| 参数 | 人话解释 | 生活类比 |
|---|---|---|
| learning_rate | 每次训练模型参数调整的幅度 | 学开车时方向盘转多大:太大容易失控,太小学得太慢 |
| vf_coef | Critic(教练)说话的分量 | 教练影响力太大:司机听教练的多了,自己就不敢开了 |
| clip_range | 限制策略更新的幅度 | 跑步时每次步伐别太大,不然容易摔倒 |
| target_kl | 策略变化的警戒线 | 就像车速限制,超过这个速度就自动刹车 |
| n_epochs | 同一批数据重复学几次 | 同一道题做太多遍容易背答案,而不是真正理解 |
| 冻结层数 | 固定住的神经网络层数 | 把房子的地基固定住,只装修上面的楼层 |
| batch_size | 一次训练用多少样本 | 做饭时一次炒多少菜:太少费火,太多容易炒不熟 |
核心思想:
PPO 在预训练模型上,不是用来"猛涨分"的,是用来"稳稳变好"的。
PPO + 预训练模型 = 必须保守
💡 Trick:
- 学习率建议用余弦衰减,避免固定学习率导致后期震荡
- Critic 的学习率可以比 Actor 高(如 Actor 1e-6,Critic 5e-6),因为 Critic 需要更快拟合奖励值
- 显存不够时,优先用 Gradient Accumulation 等效扩大 batch size
调优后,训练曲线明显更平稳,具备自我恢复能力:
| 新旧参数对比 | Via 多跳优化结果 |
|---|---|
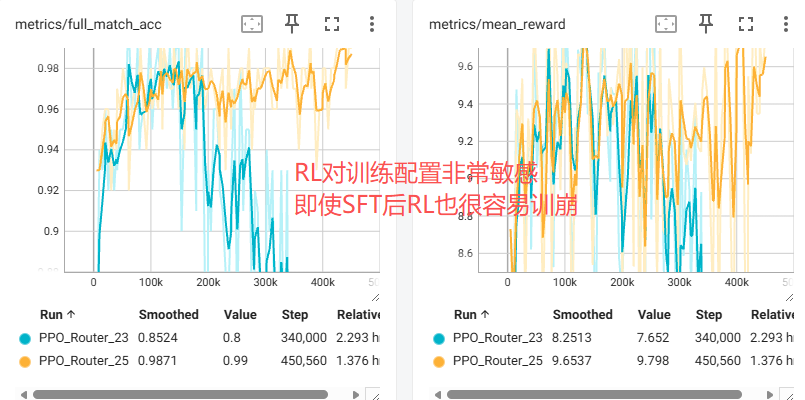 |
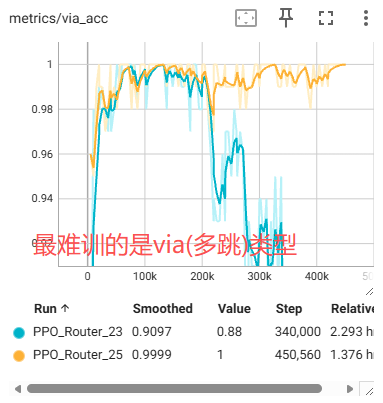 |
七、Reward Engineering:把业务约束写进奖励
7.1 三条通用原则
在讲具体做法之前,先说三条通用原则,这是解决一切 RL 问题的基石:
| 原则 | 说明 |
|---|---|
| 奖励模型是天花板 | RM 质量直接决定 RLHF 上限。如果 reward 信号本身有噪声,后续再怎么调也白搭 |
| KL 散度是缰绳 | 既要学新偏好,又不能偏离原模型太远。KL 就是控制这个距离的"缰绳" |
| 深度学习经验通用 | RLHF 本质是深度学习,调参经验大多通用 |
7.2 奖励机制本质
⚠️ 重要澄清:在当前任务中奖励是可验证的规则函数,而非训练出来的 RM。
| 方式 | 描述 | 适用场景 |
|---|---|---|
| 规则函数(当前) | 根据路径匹配度、语法正确性综合评分 | 逻辑明确、可控 |
| 奖励模型(RM) | 训练一个模型来打分 | 任务复杂度高、规则难以穷举 |
| 混合方案 | 规则为主 + LLM 判别器辅助 | 复杂生成任务 |
7.3 分层奖励设计
| 层级 | 类型 | 奖励值 | 目的 |
|---|---|---|---|
| L1 | 组件级(Dense) | 对 +1.0 / 错 -0.5 | 密集信号,避免早期迷失 |
| L2 | 合法性约束 | 合法 +0.2 / 非法 -2.0 | 注入 Schema 规则 |
| L3 | 完全匹配(Sparse) | 全对 +10.0 | 引导追求完美 |
📖 小白看这里:什么是Dense和Sparse奖励?
Dense(稠密)奖励 = 每一步都有反馈
- 类比:学开车时,教练每个动作都点评("方向盘打得不错""刹车有点急")
- 优点:学得快,知道自己哪里做对了
- 缺点:容易被"hack",模型学会钻空子
Sparse(稀疏)奖励 = 只有最后才有结果
- 类比:考试只有最后出分数,中间不知道对错
- 优点:目标明确,不会钻空子
- 缺点:学得慢,前期像"瞎蒙"
最佳实践:Dense + Sparse 混合,既有过程引导,又有最终目标。
💡 Trick:
- 复杂任务的奖励函数不要太单一,否则很容易 Reward Hacking
- Reward Clipping:建议把奖励输出限制在 [-2, 2] 范围内,防止异常高的奖励主导梯度
- 对 reward 或 advantage 做归一化(减均值、除标准差),能显著提升稳定性
7.4 发现的 Reward Hacking
训练过程中,我发现模型学会了"作弊":
坑 1:Via 字段 80% 是 null,模型无脑预测 null 也能得高分。
解决:动态加权,非 null 的 Via 给予 10 倍权重。
坑 2:即使 Anchor 错了,Via 碰巧对了也能得分。
解决:条件发放,Anchor 错则 Via 不得分。
📖 小白看这里:什么是Reward Hacking?
Reward Hacking = 模型学会钻奖励函数的空子,而不是真正学会任务
经典案例:
| 场景 | 奖励函数 | 模型学会的"作弊"方式 |
|---|---|---|
| 考试评分 | "写满字就给分" | 疯狂抄作业凑字数 |
| 赛艇训练 | "只要往前游就有分" | 转圈游(无限得分) |
| 本文案例 | "Via对就给分" | 无脑预测null(80%概率对) |
解决思路:
- 动态加权:难的对的给高分
- 条件发放:前置条件错了,后面对了也不算
- 加惩罚项:发现作弊就扣分
# 条件发放示例
if anchor_correct:
reward += via_reward * dynamic_weight
else:
reward += 0 # Anchor 错了,Via 分不给
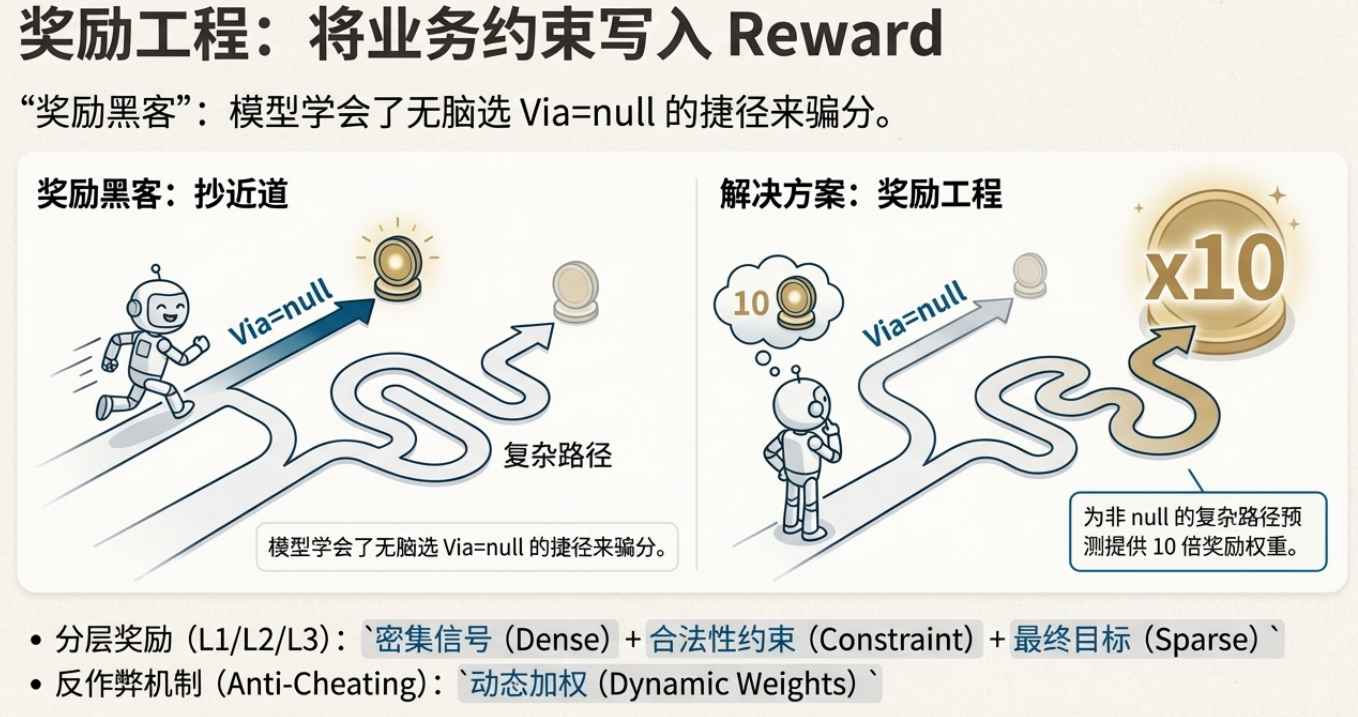
💡 Trick:遇到 Reward Hacking,解决方案通常是:
- 在奖励函数中加入惩罚项
- 调低某个 reward 的权重系数
- 把作弊样本作为负例,重新训练奖励模型
八、评估:别只看训练曲线,要证明"确实学到了"
我们做了统一评估模块,让三种方法同台:
| 方法 | 描述 | 模型架构 |
|---|---|---|
| Baseline | 通用大模型的原生能力 | LLM + 正则提取 |
| SFT | 模仿学习的上限 | BERT + 3 分类头 |
| RL (PPO) | 自我探索与优化的成果 | PPO + SFT 预训练 |
核心指标
| 方法 | 完全匹配 | Via 准确率 |
|---|---|---|
| Baseline(通用 LLM) | 35.71% | - |
| SFT | 89.29% | 87.50% |
| RL(PPO) | 89.29% | 89.29% |
端到端 AB(执行视角):
| 指标 | Baseline | Router(RL) | 变化 |
|---|---|---|---|
| 执行成功率 | 80% | 90% | 🔼 +10% |
| 查空/报错率 | 20% | 10% | 🔽 -50% |
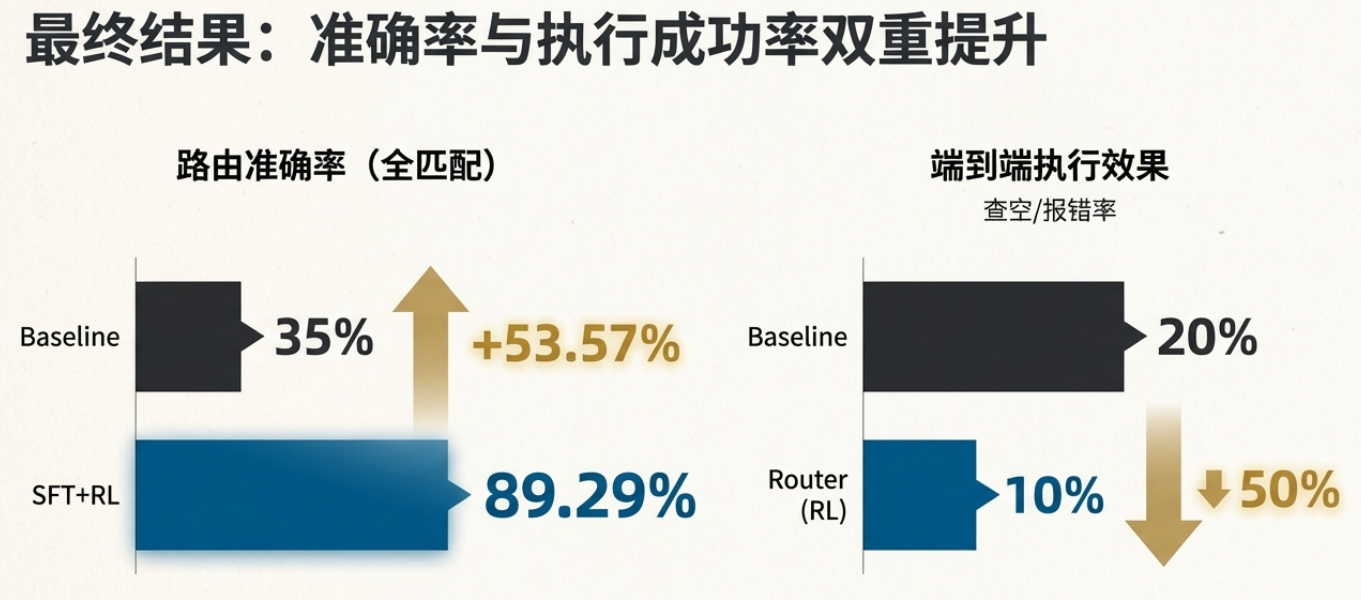
我们观察到一个有意思的点:
- SFT 和 PPO 的 Full Match 在某些测试集上差不多
- 但 PPO 更容易在多跳、长尾问法上稳住,而且执行端指标更好
这也是我最后觉得"PPO 值得做"的原因:它不是为了把一个数字从 80 提到 90,而是为了让模型在真实环境里更不容易翻车。
九、故障排查手册(15 种典型问题)
分享一个我总结的排障手册。核心原则:先止血,再找病因。
9.1 快速止损表
| 现象 | 大概率原因 | 怎么救 | |
|---|---|---|---|
approx_kl > 0.1 |
更新步幅太大 | 降 lr / 降 clip_range / 严 target_kl | |
| Reward 长期不涨 | SFT 权重没加载 | 检查初始化,确认从高起点开始 | |
| Via 全选 null | Reward Hacking | 开启动态加权 | |
| Value Loss 剧烈震荡 | Critic 在捣乱 | 降 vf_coef / 冻结更多层 | |
| 训练越久越差 | 灾难性遗忘 | Early Stop / 减少 n_epochs |
9.2 详细现象排查
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| Reward 上升 + KL 爆炸 | kl_penalty 系数过低或没加 | 增加 KL 惩罚项,从 0.001 开始调 |
| KL 很低 + Reward 不涨 | kl_penalty 太强,模型被束缚 | 调低系数,同时检查学习率 |
| 初期输出重复/无意义 | 学习率过高,参数更新过猛 | 降到 1e-6 ~ 1e-5,加 warmup |
| 响应长度异常(过长/过短) | RM 有 length bias | 在 RL 阶段加入长度惩罚/奖励 |
| 训练不稳定,loss 剧烈波动 | batch_size 太小 / reward 没归一化 | 扩大 batch / 对 reward 做 norm 和 clip |
| 后期质量下降 | 过拟合 RM / KL 约束失效 | Early Stop,检查 KL 是否在合理范围 |
| Critic Value Loss 波动 | reward 方差过大 | 对 reward 或 advantage 做归一化 |
| 策略熵快速下降,输出同质化 | entropy_coef 过低,探索不足 | 增大熵系数 |
| 梯度范数爆炸 | 学习率过高 / 没有梯度裁剪 | 降 lr,启用 gradient clipping |
| Reward 上涨但人工评估差 | RM 过拟合或偏好数据有偏 | 拆分多维度 reward,分别标注加权 |
| 测试集好但部署效果差 | 训练数据与真实场景分布差异 | 扩充领域/风格数据,提升泛化 |
| DPO 的 chosen/rejected 概率差增长慢 | beta 值过高,更新太保守 | 调低 beta |
| DPO loss 下降快但效果不如 SFT | beta 过低或 lr 过高 | 调高 beta,降低学习率 |
.png)
最重要的一条:
📌 如果你只想盯一个指标,盯
approx_kl。超过 0.1 立刻停下来检查。
十、三条核心教训

| 经验 | 记忆口诀 |
|---|---|
| 必须 SFT 冷启动 | "先背书,再做题" |
| PPO 必须保守更新 | "低 lr + 低 vf + 严 KL" |
| 奖励设计防作弊 | "动态加权 + 条件发放" |
写在最后
做完这个项目,我最大的感受是:
RL 的难点不是写模型,是写环境和奖励。
代码可能只占 20% 的工作量,剩下 80% 都在:
- 设计环境和奖励
- 调参、debug
- 理解模型为什么"学歪了"
换个角度想,RLHF 本质上就是一个自动化的"集成测试"循环:模型输出 → 环境打分 → 模型调整 → 再输出。
只不过这个"测试用例"是你设计的 Reward 函数。
希望这篇文章能帮你少踩几个坑。如果你也在做类似的事情,欢迎留言交流。
Q&A(把评论区高频问题先回答掉)
Q1:为什么 SFT 和 RL 在简单测试集上结果一样?
A:简单单跳样本 SFT 已经接近满分。RL 的优势主要在长尾复杂样本、多跳与执行端稳定性,数据越复杂差异越明显。
Q2:训练初期 reward 不涨怎么办?
A:优先检查 SFT 权重是否正确加载。RL 应该从一个高起点开始(比如 Acc ~80%/90%),而不是从零瞎蒙。如果确认加载了还是不涨,用训练前的模型针对一些 case rollout 多个回复,看这些回复的奖励是不是都特别低——如果是,说明基模能力上限就这样,换模型或优化 SFT。
Q3:Baseline 评估为什么这么慢?
A:因为要调用大模型 API,单条请求耗时很常见在秒级(我们当时约 10 秒/条量级)。
Q4:奖励函数是训练出来的吗?
A:当前不是。我们用可验证规则函数做 reward,因为逻辑明确、可控。若任务复杂到规则难穷举,可以引入 LLM Judge 做软评分,规则做硬约束。
Q5:表结构变更需要重新训练吗?
A:不一定。Router 更依赖"表之间怎么连",不强依赖字段细节;但新增表/新增关系通常需要补数据再训一版适配。
Q6:模型保存有什么建议?
A:RLHF 最好每隔一定 step 保存优化器参数,这样可以随时恢复训练。尤其是多机多卡场景,容易出现通信问题导致训练中断。
📚 参考资料
👤 关于作者
专注AI与算法工程落地的一线开发者。踩过的坑比写过的代码还多(因为vibe code多)。
如果你也在做大模型相关的工程化工作,欢迎关注交流。
⚠️ 原创声明:本文为原创内容,转载请联系作者获取授权。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号