

CPU 硬盘性能到底相差多少
本文以一个现代的、实际的个人电脑为对象,分析其中CPU(Intel Core 2 Duo 3.0GHz)以及各类子系统的运行速度——延迟和数据吞吐量。通过粗略的估算PC各个组件的相对运行速度,希望能给大家留下一个比较直观的印象。本文中的数据来自实际应用,而非理论最大值。时间的单位是纳秒(ns,十亿分之一秒),毫秒(ms,千分之一秒),和秒(s)。吞吐量的单位是兆字节(MB)和千兆字节(GB)。让我们先从CPU和内存开始,下图是北桥部分:

第一个令人惊叹的事实是:CPU快得离谱。在Core 2 3.0GHz上,大部分简单指令的执行只需要一个时钟周期,也就是1/3纳秒。即使是真空中传播的光,在这段时间内也只能走10厘米(约4英寸)。把上述事实记在心中是有好处的。当你要对程序做优化的时候就会想到,执行指令的开销对于当今的CPU而言是多么的微不足道。
当CPU运转起来以后,它便会通过L1 cache和L2 cache对系统中的主存进行读写访问。cache使用的是静态存储器(SRAM)。相对于系统主存中使用的动态存储器(DRAM),cache读写速度快得多、造价也高昂得多。cache一般被放置在CPU芯片的内部,加之使用昂贵高速的存储器,使其给CPU带来的延迟非常低。在指令层次上的优化(instruction-level optimization),其效果是与优化后代码的大小息息相关。由于使用了高速缓存技术(caching),那些能够整体放入L1/L2 cache中的代码,和那些在运行时需要不断调入/调出(marshall into/out of)cache的代码,在性能上会产生非常明显的差异。
正常情况下,当CPU操作一块内存区域时,其中的信息要么已经保存在L1/L2 cache,要么就需要将之从系统主存中调入cache,然后再处理。如果是后一种情况,我们就碰到了第一个瓶颈,一个大约250个时钟周期的延迟。在此期间如果CPU没有其他事情要做,则往往是处在停机状态的(stall)。为了给大家一个直观的印象,我们把CPU的一个时钟周期看作一秒。那么,从L1 cache读取信息就好像是拿起桌上的一张草稿纸(3秒);从L2 cache读取信息则是从身边的书架上取出一本书(14秒);而从主存中读取信息则相当于走到办公楼下去买个零食(4分钟)。
主存操作的准确延迟是不固定的,与具体的应用以及其他许多因素有关。比如,它依赖于列选通延迟(CAS)以及内存条的型号,它还依赖于CPU指令预取的成功率。指令预取可以根据当前执行的代码来猜测主存中哪些部分即将被使用,从而提前将这些信息载入cache。
看看L1/L2 cache的性能,再对比主存,就会发现:配置更大的cache或者编写能更好的利用cache的应用程序,会使系统的性能得到多么显著的提高。如果想进一步了解有关内存的诸多信息,读者可以参阅Ulrich Drepper所写的一篇经典文章《What Every Programmer Should Know About Memory》。
人们通常把CPU与内存之间的瓶颈叫做冯·诺依曼瓶颈(von Neumann bottleneck)。当今系统的前端总线带宽约为10GB/s,看起来很令人满意。在这个速度下,你可以在1秒内从内存中读取8GB的信息,或者10纳秒内读取100字节。遗憾的是,这个吞吐量只是理论最大值(图中其他数据为实际值),而且是根本不可能达到的,因为主存控制电路会引入延迟。在做内存访问时,会遇到很多零散的等待周期。比如电平协议要求,在选通一行、选通一列、取到可靠的数据之前,需要有一定的信号稳定时间。由于主存中使用电容来存储信息,为了防止因自然放电而导致的信息丢失,就需要周期性的刷新它所存储的内容,这也带来额外的等待时间。某些连续的内存访问方式可能会比较高效,但仍然具有延时。而那些随机的内存访问则消耗更多时间。所以延迟是不可避免的。
图中下方的南桥连接了很多其他总线(如:PCI-E, USB)和外围设备:

令人沮丧的是,南桥管理了一些反应相当迟钝的设备,比如硬盘。就算是缓慢的系统主存,和硬盘相比也可谓速度如飞了。继续拿办公室做比喻,等待硬盘寻道的时间相当于离开办公大楼并开始长达一年零三个月的环球旅行。这就解释了为何电脑的大部分工作都受制于磁盘I/O,以及为何数据库的性能在内存缓冲区被耗尽后会陡然下降。同时也解释了为何充足的RAM(用于缓冲)和高速的磁盘驱动器对系统的整体性能如此重要。
虽然磁盘的“连续”存取速度确实可以在实际使用中达到,但这并非故事的全部。真正令人头疼的瓶颈在于寻道操作,也就是在磁盘表面移动读写磁头到正确的磁道上,然后再等待磁盘旋转到正确的位置上,以便读取指定扇区内的信息。RPM(每分钟绕转次数)用来指示磁盘的旋转速度:RPM越大,耽误在寻道上的时间就越少,所以越高的RPM意味着越快的磁盘。这里有一篇由两个Stanford的研究生写的很酷的文章,其中讲述了寻道时间对系统性能的影响:《Anatomy of a Large-Scale Hypertextual Web Search Engine》
当磁盘驱动器读取一个大的、连续存储的文件时会达到更高的持续读取速度,因为省去了寻道的时间。文件系统的碎片整理器就是用来把文件信息重组在连续的数据块中,通过尽可能减少寻道来提高数据吞吐量。然而,说到计算机实际使用时的感受,磁盘的连续存取速度就不那么重要了,反而应该关注驱动器在单位时间内可以完成的寻道和随机I/O操作的次数。对此,固态硬盘(SSD)可以成为一个很棒的选择。
硬盘的cache也有助于改进性能。虽然16MB的cache只能覆盖整个磁盘容量的0.002%,可别看cache只有这么一点大,其效果十分明显。它可以把一组零散的写入操作合成一个,也就是使磁盘能够控制写入操作的顺序,从而减少寻道的次数。同样的,为了提高效率,一系列读取操作也可以被重组,而且操作系统和驱动器固件(firmware)都会参与到这类优化中来。
最后,图中还列出了网络和其他总线的实际数据吞吐量。火线(fireware)仅供参考,Intel X48芯片组并不直接支持火线。我们可以把Internet看作是计算机之间的总线。去访问那些速度很快的网站(比如google.com),延迟大约45毫秒,与硬盘驱动器带来的延迟相当。事实上,尽管硬盘比内存慢了5个数量级,它的速度与Internet是在同一数量级上的。目前,一般家用网络的带宽还是要落后于硬盘连续读取速度的,但“网络就是计算机”这句话可谓名符其实。如果将来Internet比硬盘还快了,那会是个什么景象呢?
我希望这些图片能对您有所帮助。当这些数字一起呈现在我面前时,真的很迷人,也让我看到了计算机技术发展到了哪一步。前文分开的两个图片只是为了叙述方便,我把包含南北桥的整张图片也贴出来,供您参考。

原文标题:What Your Computer Does While You Wait
再说一下表分区
网上表分区的文章成千上万,但是分区之后表数据的分布和流向都没有说
首先要说明的是表分区的分区不是指页面存储概念的分区,我用下面的图来表示
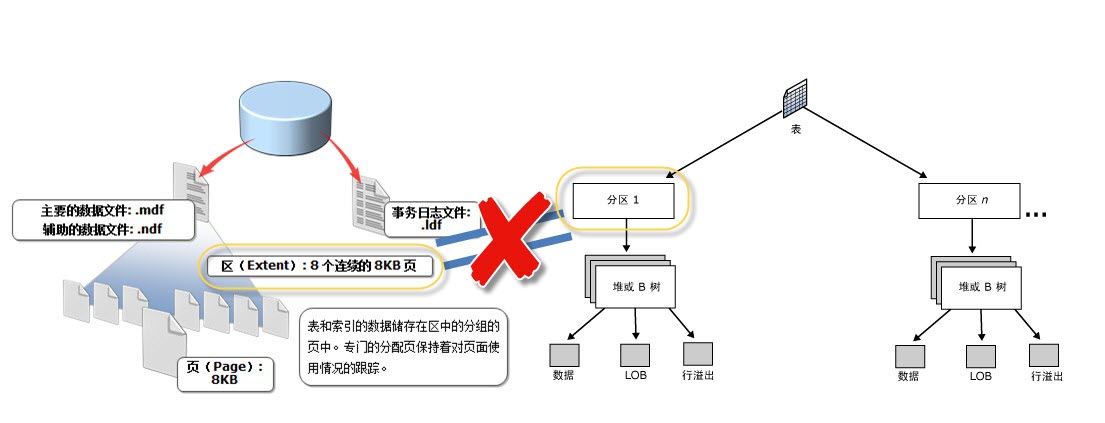
他们是没有关系的
正式开始
SQL脚本如下:

1 USE master 2 GO 3 4 --创建数据库 5 CREATE DATABASE [Test] 6 GO 7 8 USE [Test] 9 GO 10 11 12 --1.创建文件组 13 ALTER DATABASE [Test] 14 ADD FILEGROUP [FG_TestUnique_Id_01] 15 16 ALTER DATABASE [Test] 17 ADD FILEGROUP [FG_TestUnique_Id_02] 18 19 ALTER DATABASE [Test] 20 ADD FILEGROUP [FG_TestUnique_Id_03] 21 22 --2.创建文件 23 ALTER DATABASE [Test] 24 ADD FILE 25 (NAME = N'FG_TestUnique_Id_01_data',FILENAME = N'E:\FG_TestUnique_Id_01_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) 26 TO FILEGROUP [FG_TestUnique_Id_01]; 27 28 ALTER DATABASE [Test] 29 ADD FILE 30 (NAME = N'FG_TestUnique_Id_02_data',FILENAME = N'E:\FG_TestUnique_Id_02_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) 31 TO FILEGROUP [FG_TestUnique_Id_02]; 32 33 ALTER DATABASE [Test] 34 ADD FILE 35 (NAME = N'FG_TestUnique_Id_03_data',FILENAME = N'E:\FG_TestUnique_Id_03_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) 36 TO FILEGROUP [FG_TestUnique_Id_03];
创建分区函数和分区方案
我们创建了一个用于数据类型为int的分区函数,按照数值来划分
文件组 分区 取值范围
[FG_TestUnique_Id_01] 1 (小于2, 2] --包括2
[FG_TestUnique_Id_02] 2 [3, 4]
[FG_TestUnique_Id_03] 3 (4,大于4) --不包括4
1 --3.创建分区函数 2 --我们创建了一个用于数据类型为int的分区函数,按照数值来划分 3 --文件组 分区 取值范围 4 --[FG_TestUnique_Id_01] 1 (小于2, 2]--包括2 5 --[FG_TestUnique_Id_02] 2 [3, 4] 6 --[FG_TestUnique_Id_03] 3 (4,大于4) --不包括4 7 8 CREATE PARTITION FUNCTION 9 Fun_TestUnique_Id(INT) AS 10 RANGE LEFT 11 FOR VALUES(2,4) 12 13 14 15 16 --4.创建分区方案 17 CREATE PARTITION SCHEME 18 Sch_TestUnique_Id AS 19 PARTITION Fun_TestUnique_Id 20 TO([FG_TestUnique_Id_01],[FG_TestUnique_Id_02],[FG_TestUnique_Id_03])
建立分区表
1 --5.创建分区表 2 CREATE TABLE testPartionTable 3 ( 4 id INT NOT NULL, 5 itemno CHAR(20), 6 itemname CHAR(40) 7 )ON Sch_TestUnique_Id([id]) 8 9 10 INSERT INTO [dbo].[testPartionTable] ( [id], [itemno], [itemname] ) 11 SELECT 1,'1','中国' UNION ALL 12 SELECT 2,'2','法国' UNION ALL 13 SELECT 3,'3','美国' UNION ALL 14 SELECT 4,'4','英国' UNION ALL 15 SELECT 5,'5','德国'
查看边界值点
1 --查看边界值点 2 select * from sys.partition_range_values 3 GO

查看表数据
1 SELECT * FROM [dbo].[testNonPartionTable] 2 GO

我们看一下当前数据库的情况
1 EXEC [sys].[sp_helpdb] @dbname = test -- sysname 2 GO

FG_TestUnique_Id_0X这三个文件组建立在三个ndf文件上,三个ndf文件都位于E盘
而fileid分别是3、4、5
我们看一下表的页面分配情况
 View Code
View Code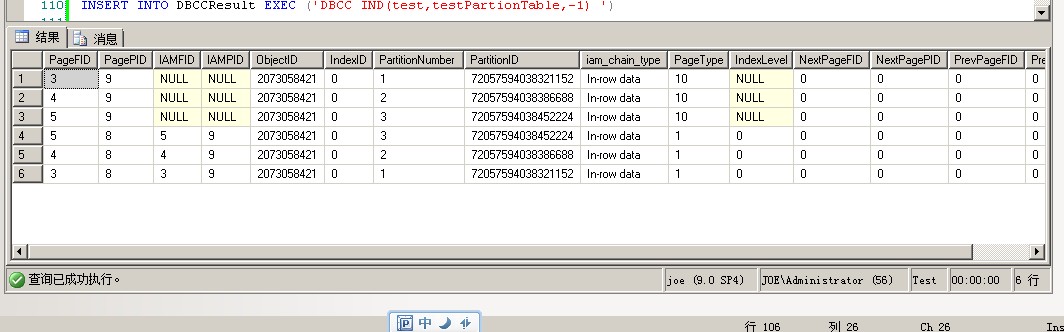
1 SELECT * 2 FROM sys.dm_db_index_physical_stats(DB_ID('test'), 3 OBJECT_ID('testPartionTable'), NULL, 4 NULL, 'detailed')

从上面两个图我们可以得知

-----------------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------------

分区号1~3对应的文件组名和ndf文件名分别是:
分区号1 (PartitionNumber1)-》文件组FG_TestUnique_Id_01-》E:\FG_TestUnique_Id_01_data.ndf
分区号2 (PartitionNumber2)-》文件组FG_TestUnique_Id_02-》E:\FG_TestUnique_Id_02_data.ndf
分区号3 (PartitionNumber3)-》文件组FG_TestUnique_Id_03-》E:\FG_TestUnique_Id_03_data.ndf
表中只有一个数据页面8 和一个IAM页面9
但是每个ndf文件里面却都存储了一份数据页面8 和一份IAM页面9
而且每个ndf文件里面 数据页面存储的内容都不一样,虽然页面编号一样,都是8
数据页面存储的内容
我们来看一下每个ndf文件里面的数据页面都存储了些什么内容?
我们先来看一下testPartionTable表的objectID
1 SELECT OBJECT_ID('testPartionTable') AS 'OBJECTID'

先看FILEID为3的文件里面的数据页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,3,8,3) 4 GO
View Code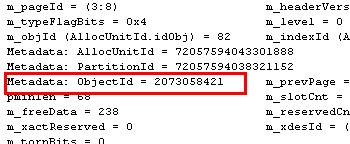
这个页面是属于testPartionTable表
1 Slot 0 Column 0 Offset 0x4 Length 4 2 3 id = 1 4 5 Slot 0 Column 1 Offset 0x8 Length 20 6 7 itemno = 1 8 9 Slot 0 Column 2 Offset 0x1c Length 40 10 11 itemname = 中国 12 13 Slot 1 Offset 0xa7 Length 71 14 15 16 17 Slot 1 Column 0 Offset 0x4 Length 4 18 19 id = 2 20 21 Slot 1 Column 1 Offset 0x8 Length 20 22 23 itemno = 2 24 25 Slot 1 Column 2 Offset 0x1c Length 40 26 27 itemname = 法国
FILEID为3的文件里面的数据页面里存放了id为1和id为2的这两条记录
看FILEID为4的文件里面的数据页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,4,8,3) 4 GO
View Code
这个页面是属于testPartionTable表
1 Slot 0 Offset 0x60 Length 71 2 3 4 Slot 0 Column 0 Offset 0x4 Length 4 5 6 id = 3 7 8 Slot 0 Column 1 Offset 0x8 Length 20 9 10 itemno = 3 11 12 Slot 0 Column 2 Offset 0x1c Length 40 13 14 itemname = 美国 15 16 Slot 1 Offset 0xa7 Length 71 17 18 19 Slot 1 Column 0 Offset 0x4 Length 4 20 21 id = 4 22 23 Slot 1 Column 1 Offset 0x8 Length 20 24 25 itemno = 4 26 27 Slot 1 Column 2 Offset 0x1c Length 40 28 29 itemname = 英国
FILEID为4的文件里面的数据页面里存放了id为3和id为4的这两条记录
看FILEID为5的文件里面的数据页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,5,8,3) 4 GO

这个页面是属于testPartionTable表
View Code1 Slot 0 Offset 0x60 Length 71 2 3 4 Slot 0 Column 0 Offset 0x4 Length 4 5 6 id = 5 7 8 Slot 0 Column 1 Offset 0x8 Length 20 9 10 itemno = 5 11 12 Slot 0 Column 2 Offset 0x1c Length 40 13 14 itemname = 德国
FILEID为5的文件里面的数据页面里存放了id为5这条记录
再看我们刚才建立的分区函数,和各个ndf里的数据页面存储的记录条数
1 创建分区函数 2 我们创建了一个用于数据类型为int的分区函数,按照数值来划分 3 文件组 分区 取值范围 4 [FG_TestUnique_Id_01] 1 (小于2, 2]--包括2 5 [FG_TestUnique_Id_02] 2 [3, 4] 6 [FG_TestUnique_Id_03] 3 (4,大于4) --不包括4 7 8 CREATE PARTITION FUNCTION 9 Fun_TestUnique_Id(INT) AS 10 RANGE LEFT 11 FOR VALUES(2,4)
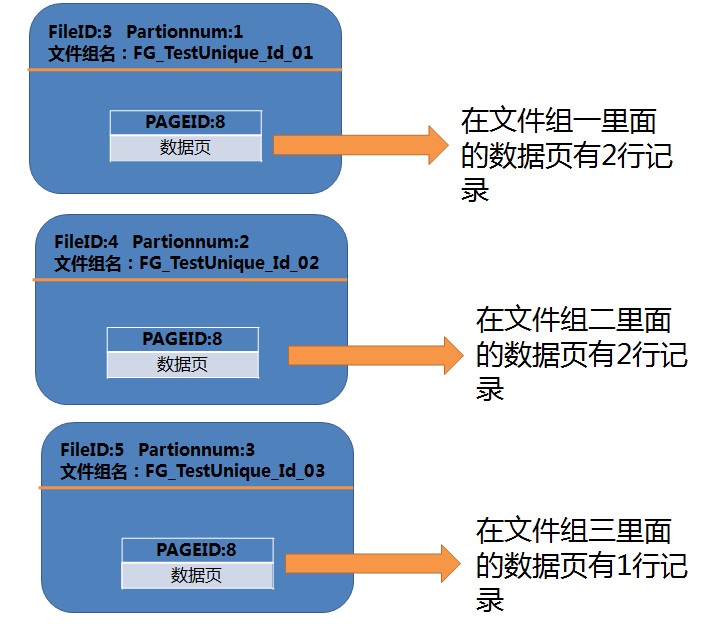
当执行select * from testPartionTable的时候,就需要跨这三个ndf文件来读取记录
IO一定会有所影响,所以一般应用都是按照月份、性别等来进行分区,确保查询数据的时候不要跨多个文件组
如果表没有分区是怎样的?
SQL脚本如下,建立testNonPartionTable表:
View Code
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,1,47,3) 4 GO
View Code1 itemname = 中国 2 3 Slot 1 Offset 0xa7 Length 71 4 5 6 Slot 1 Column 0 Offset 0x4 Length 4 7 8 id = 2 9 10 Slot 1 Column 1 Offset 0x8 Length 20 11 12 itemno = 2 13 14 Slot 1 Column 2 Offset 0x1c Length 40 15 16 itemname = 法国 17 18 Slot 2 Offset 0xee Length 71 19 20 21 Slot 2 Column 0 Offset 0x4 Length 4 22 23 id = 3 24 25 Slot 2 Column 1 Offset 0x8 Length 20 26 27 itemno = 3 28 29 Slot 2 Column 2 Offset 0x1c Length 40 30 31 itemname = 美国 32 33 Slot 3 Offset 0x135 Length 71 34 35 36 Slot 3 Column 0 Offset 0x4 Length 4 37 38 id = 4 39 40 Slot 3 Column 1 Offset 0x8 Length 20 41 42 itemno = 4 43 44 Slot 3 Column 2 Offset 0x1c Length 40 45 46 itemname = 英国 47 48 Slot 4 Offset 0x17c Length 71 49 50 51 52 Slot 4 Column 0 Offset 0x4 Length 4 53 54 id = 5 55 56 Slot 4 Column 1 Offset 0x8 Length 20 57 58 itemno = 5 59 60 Slot 4 Column 2 Offset 0x1c Length 40 61 62 itemname = 德国
五条记录都在同一个数据页面
参考文章:
http://www.cnblogs.com/zhijianliutang/archive/2012/10/28/2743722.html
如有不对的地方,欢迎大家拍砖o(∩_∩)o
----------------------------------------------------------------
2013-10-19 晚上补充
我们用Internal Viewer来查看TEST数据库
在Internal Viewer查看到TEST数据库是分区的,十分形象
也能够看到那3个pageid为8的数据页面



我们进入第4个文件的数据页面,即是:E:\FG_TestUnique_Id_02_data.ndf里的数据页面
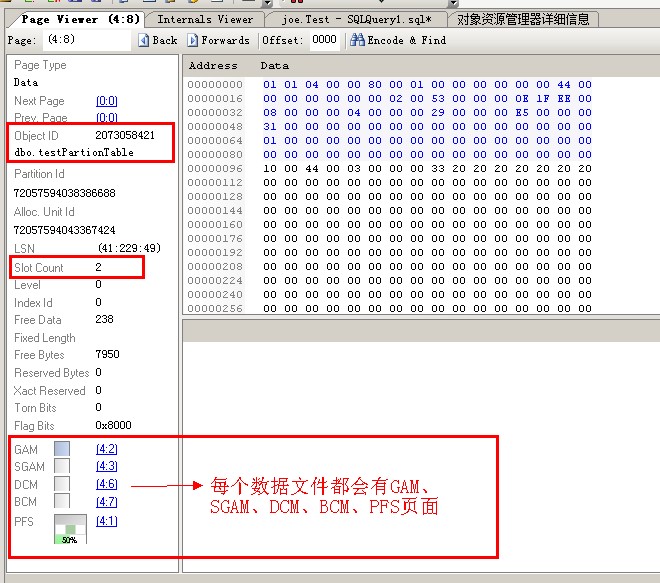
可以看到每个数据文件都会有GAM、SGAM、DCM、BCM、PFS页面
另外的两个数据页面我就不打开来看了
关于GAM、SGAM、DCM、BCM、PFS这些页面的作用可以参考下面文章:
SQL Server 2008 连载之存储结构之DCM、BCM


 浙公网安备 33010602011771号
浙公网安备 33010602011771号