

转载程序员,请你不要在坑程序员了🤣
>jsoncat:https://github.com/Snailclimb/jsoncat (仿 Spring Boot 但不同于 Spring Boot 的一个轻量级的 HTTP 框架)
大家好,hellohello-tom又来分享实战经验了。🤣
在一个风和日丽的下午,tom哥正在工位上打着瞌睡,突然QQ群运维同学@全部开发人员说线上绿线环境大面积开始瘫痪,zuul网关大量接口返回service unavailable,并且范围已经开始波及到红、蓝线,运维同学说发生事故的机器他们已经重启了,但是在一段短时间后还是会继续阻塞,运维主管紧急把此次事故定义为I级,全员备战,要求开发人员迅速解决问题。
项目经理拉上java组同学紧急开会,tom哥也不敢怠慢,拉上运维我们就一起开始进行事故分析,打开zabbix监控管理界面,查看各项服务器监控
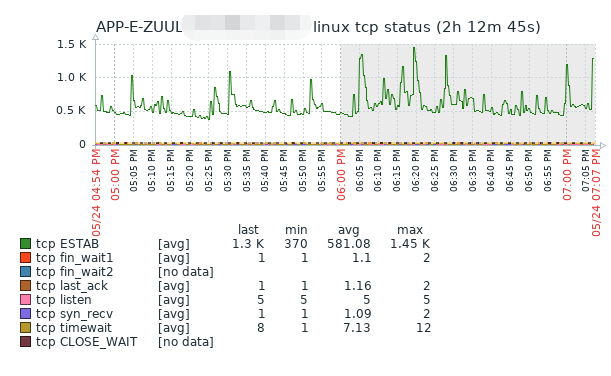
随便查看一台网关,我的天这服务器连接数跟过山车一样忽上忽下的,这铁定是出问题了,赶快进行链路追踪,发现部分接口请求时间在20s,现在全线业务响应都极其的缓慢,运维同学报告说,通过这几次重启发现一个共性,就是每当redis网络带宽达到850m时会逐渐造成生产环境延时卡慢,最终造成服务不可用状态,初步定位可能是redis的问题,但redis的网络正常,CPU正常,slowlog也都在合理范围内现在只能期望我们java组同学看能否看出一丝端倪,tom哥一个踉跄,赶快挺直腰板,心想I级属于一级事故类型了,搞不好会被扣工资的,tom哥赶快打开跳板机,随便登录一台下游绿线服务器,查看java应用程序
jps -l

按照tom哥的习惯,打印出java程序的pid后首先会去观察各项内存指标、新生代老年代GC情况等
jstat -gcutil 11984 1000 10
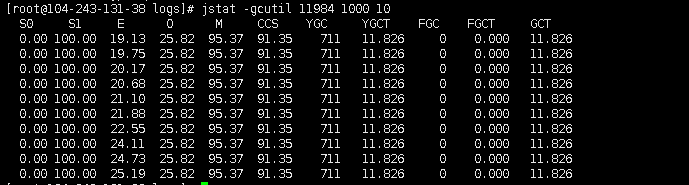
非常健康,没有发生full gc,ygc也少的可怜,既然如此那就分析下是否有CPU高负载的情况
top -Hp 11984

线程信息也非常正常,没有某个线程CPU负载特别高的,接下来继续分析打印java应用程序线程堆栈,首先看看是不是有产生死锁的地方
jstack -m 11984
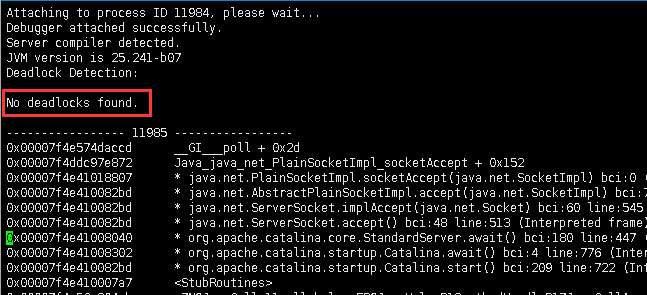
这个说明程序也没有产生死锁相关的问题,那接下来只能继续打印java线程堆栈具体干的事了。
jstack 11984

这时候发现一丝问题,线程堆栈中有大量的ClusterCommandExcutor与对应的TIMED_WAITING状态
jstack 11984 | grep ClusterCommandExecutor | wc -l
追踪堆栈源
终于发现大量的线程等待发起源头是在redisUtil的mget方法上,马上开始审查调用这块代码的源头,发现业务代码中主要业务有一个mapByUserIds,会传入一个用户集合,然后根据用户集合一次性会从redis获取用户的缓存信息,到这里感觉基本已经能确认问题了,由于最近公司用户量增加,在某些业务场景,发现会一次mget出10000个的用户信息,在这样大批量的数据操作肯定会造成redis挤压了,由于我们操作redis使用了jedisPool,如果一个连接请求大量的key时,可能就会造成连接池得不到释放,如果连接池内都被这样要获取大数据量的连接占满时,就可能会引起整个项目从redis获取数据时全面阻塞,等到连接之后才能继续操作redis,引起雪崩。
知道这个场景,那代码就好修改了,大概解决思路是这样的,在mget之前会进行一个拆分操作,把大key拆小,分多次从服务器请求回需要获取的用户信息
//100是测试后最理想的值
int count = Double.valueOf(Math.ceil(keys.size() / (double) 100)).intValue();
for (int i = 0; i < count; i++) {
dataList.addAll(valueOperations.multiGet(keys.stream().skip(i * 100).limit(100).collect(Collectors.toList())));
}
就这么随意的解决了,但是感觉还是不太完美,如果1万个用户信息的key,那我是单线程执行可能就要执行100次,这样子也太慢了,加个并发处理吧
private ExecutorService executorService = new ThreadPoolExecutor(4, 4,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(), new NamedThreadFactory("mget-redis-pool"));
int count = Double.valueOf(Math.ceil(keys.size() / (double) 100)).intValue();
List<future<list<string>>> future = new ArrayList<>();
for (int i = 0; i < count; i++) {
List<string> limitKeys = keys.stream().skip(i * 100).limit(100).collect(Collectors.toList());
future.add(executorService.submit(() -> dataList.addAll(valueOperations.multiGet(limitKeys))));
}
try {
for (Future<list<string>> f : future) {
//这里要考虑dataList线程并发安全哦
dataList.addAll(f.get());
}
} catch (Exception exception) {
logger.error("mget汇总结果集错误,ex=", exception);
}
线程池的数量可以按照连接池中的连接数控制,保持在一个合理范围设置一半就行,避免jedisPool内被打满,感觉这样子就已经完美解决问题,tom哥信心满满,提交测试,成功没问题,发包上线,运维同学开始紧急补丁发布。
就在tom哥以为这次问题就这样完美的解决时,运维同学又在群里发消息了,不行啊刚发的包,不到10分钟,又开始全面阻塞了,纳尼,什么情况,问题应该解决了呀,tom哥心中一惊,心想这不可能啊,急忙继续登录问题服务器排查问题
jstack 11984
这次mget的方法调用少了,但是redisUtils中各式各样的方法报错都出来了,有什么不能从连接池内获取连接的错误,有什么当前节点不能获取对应的redis key,要求让MOVED等等,错误五花八门,这是怎么回事呢,打印应用服务器与redis服务器连接情况
netstat -ano | grep 192.168.200.1
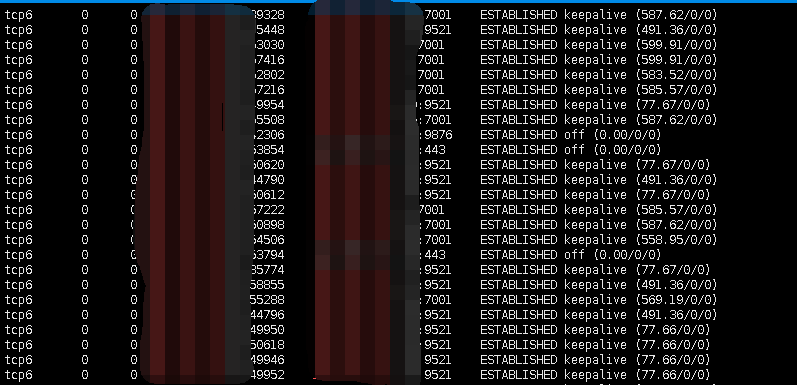
连接都处于建立成功状态,联系运维同学发现此时redis各项指标也都正常,看来问题还是出在java应用上了,没办法只能打印堆栈了
jmap -dump:format=b,file=b.dump 11984
经过漫长的等待,下载好dump文件使用Memory Analyzer进行内存对象分析,导入开始进行分析
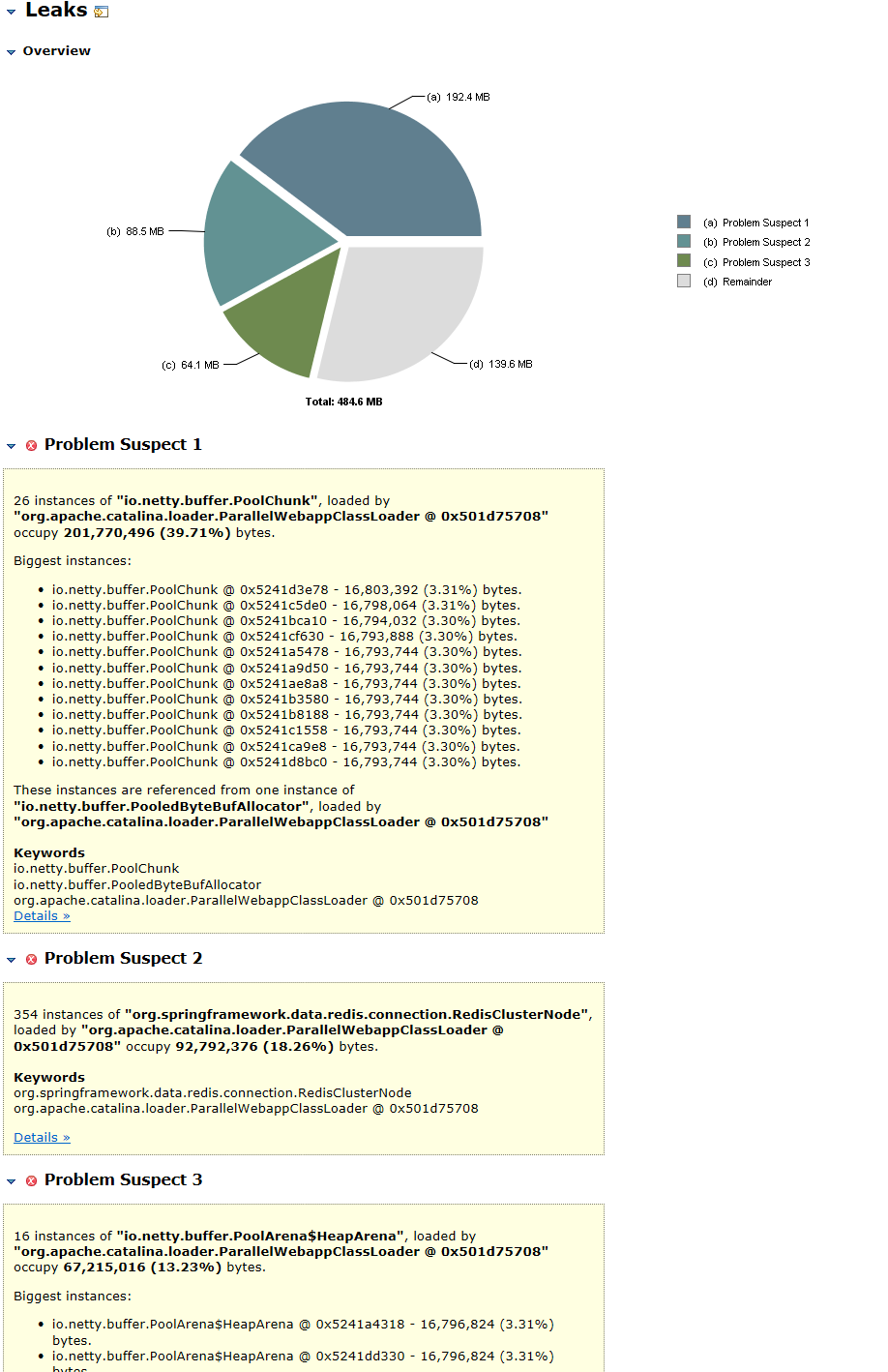
Netty类相关的可以忽略,但是
354 instances of "org.springframework.data.redis.connection.RedisClusterNode", loaded by "org.apache.catalina.loader.ParallelWebappClassLoader @ 0x501d75708" occupy 92,792,376 (18.26%) bytes.
这是什么鬼,spring redis 中的RedisClusterNode这个对象内存难道存在内存泄漏的可能么?spring官方说,我可不背这个锅,分析下RedisClusterNode的堆栈引用吧,看到底什么东西在使用它
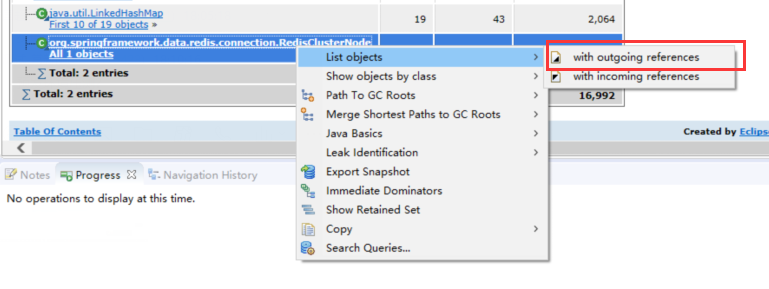

通过引用来看还是线程池中持有大量的对象,结合线程堆栈信息来看确实阻塞是发生在redis连接过程中,而spring redis 只是个壳,难道问题出现在客户端上么,继续追踪发现spring redis默认使用的是jedis客户端连接,jedis客户端版本2.9.0,google一把 jedis内存泄漏,滑一下子各式各样的错误信息提示出来了,官方也报了这个BUG,原来在高并发场景式,在释放连接时由于上一个连接没有来得及标记空,会导致连接池没有即时归还,从而导致连接泄漏。
KAO,这样太坑了,官方说在2.10.2以上版本中修复了此问题,jedis这个玩意儿你同步IO低效率还有这样BUG,坑死程序员啊。不说了赶快换组件,升级一波jedis后测试没有问题上线,tom哥心想这下问题可算能解决了吧,可以休息一会了,这时候已经深夜了。在等待短暂发包之后,tom哥还是听到不幸的消息,运维同学说还是有问题,tom哥头疼的厉害,项目经理让大家先回去休息了,先靠着线上运维同学手动不停的切换先度过去。
第二天一大早tom哥就来到公司,当再次登录到java应用程序服务器时还是有和redis相关的大量TIMED_WAITING线程,tom哥已经开始怀疑阻塞是不是到底没有产生在redis呢,联系运维同学开始抓包吧,不行就从http、tcp都抓出来看看,具体分析下这期间到底卡在哪一步了,
//因为会跳网卡,所以我们需要捕获所有网卡的连接
tcpdump -i any -w allDump.cap
抓个2、3分钟就可以了,主要看慢查询相关的内容,下载到本地后导入wireShark,分析一个慢查询接口


进栈出栈将近7秒,这个查询肯定不正常了,然后开始具体分析这期间到底都干了什么。
在wireshark中输入过滤tcp,查看版本号35512-46536中相关的内容,在一个一个排查tcp状态的同时,终于发现有不正常的tcp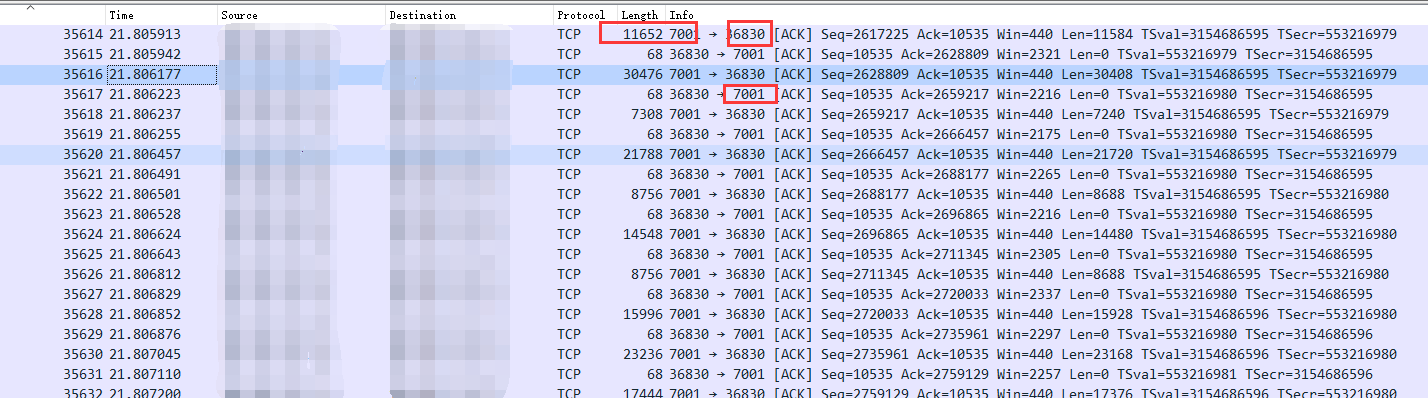
发现36830(应用服务端口)与7001(redis服务器端口) 产生大量的tcp包的传输,并且是redis服务器对应用服务器发起的PSH ACK行为,,按照length进行排序,问题暴漏出来,在短短的3分钟抓包内存在大量的报文传输,赶快去找源头
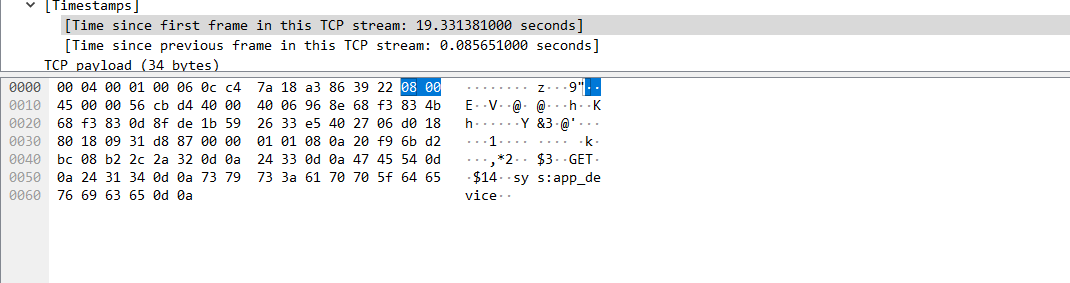
在上面的tcp请求的抓包中终于看到应用服务器去向redis获取了一个key,后续的返回包都是根据这个Get key命令进行的响应,赶快去redis查一下这到底是个什么玩意儿,执行get sys:app_device
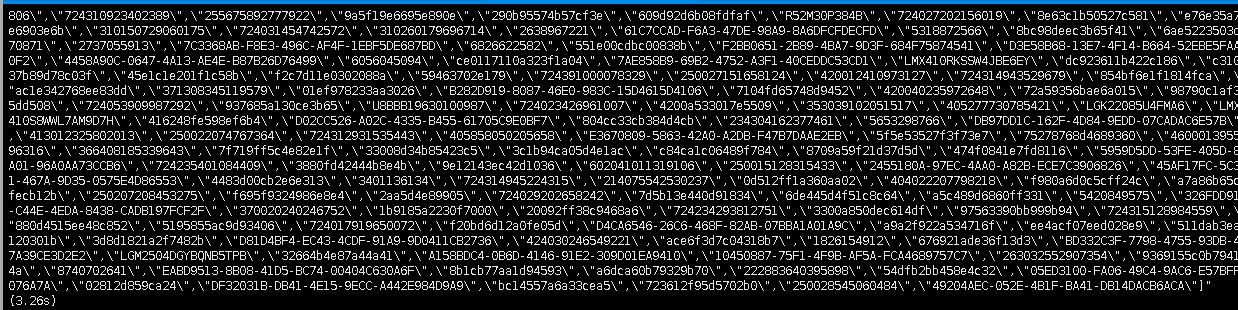
我的天足足3.26s,把这个文本保存到本地2.3m,看来问题找到了,就是这个redis大key的问题,联系项目经理,原来这个大key 存放的是封禁的app设备号列表,现在数据已经达到10几万,并且java应用程序用的也有问题,把整个数据序列化成字符串,塞到一个string value结构里面,每次app在登录、注册时都会调用此接口,造成redis阻塞,调用频率非常频繁,并且string到本地后在序列化成对象循环判断当前app传的设备列表是否为冻结设备,这简直就是挖坑啊无语,难道你用hash不香么,查询复杂度也就O(1)而已。
紧急对这块逻辑代码进行优化,设置缓存优先数据库滞后的处理方式,修改了业务代码,重新上线,至此在排查这个问题终于解决了
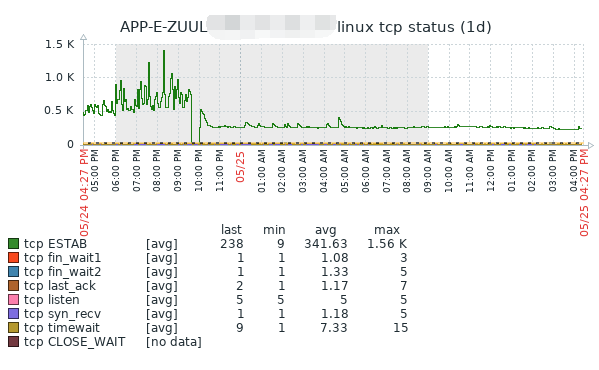
连接数终于不像老婆的心情,一天一个样了,可算平稳了。这次问题真是前人挖坑导致的呀。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号