
一、作业GitHub链接
https://github.com/LeoLeung314/LeoLeung314/tree/main/3123004746
| 这个作业属于那个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 实现一个3000字以上论文查重程序 |
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 15 |
| Estimate | 估计这个任务需要多少时间 | 650 | 555 |
| Development | 开发 | 60 | 70 |
| Analysis | 需求开发(包括学习新技术) | 120 | 120 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 45 | 40 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 120 | 120 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 40 | 30 |
| Reporting | 报告 | 40 | 40 |
| Test Report | 测试报告 | 40 | 40 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结,并提交过程改进计划 | 30 | 30 |
| 合计 | 650 | 555 |
三、计算模块接口的设计与实现过程
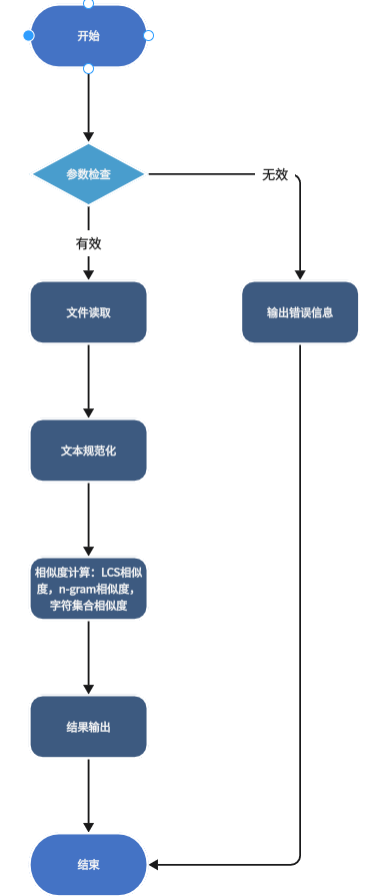
关键流程
1.文本预处理(规范化、小写转换)
2.计算文本相似度(使用多种相似度指标综合计算)
相似度计算采用多个参数因子按权重计算:
LCS相似度:最长公共子序列相似度,适合处理字符插入/删除的情况
n-gram相似度:基于字符序列的局部相似度,适合处理顺序打乱的情况
字符集合相似度:基于字符集合的相似度,适合处理字符替换的情况
四、计算模块接口部分的性能改进
优化思路:针对文本的不同情况调整,LCS相似度、n-gram相似度、字符集合相似度各自的权重,避免出现差异较大的结果
性能消耗展示如图:
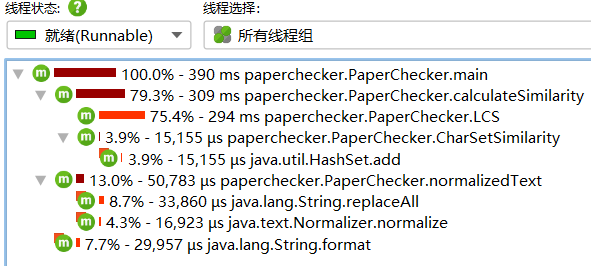
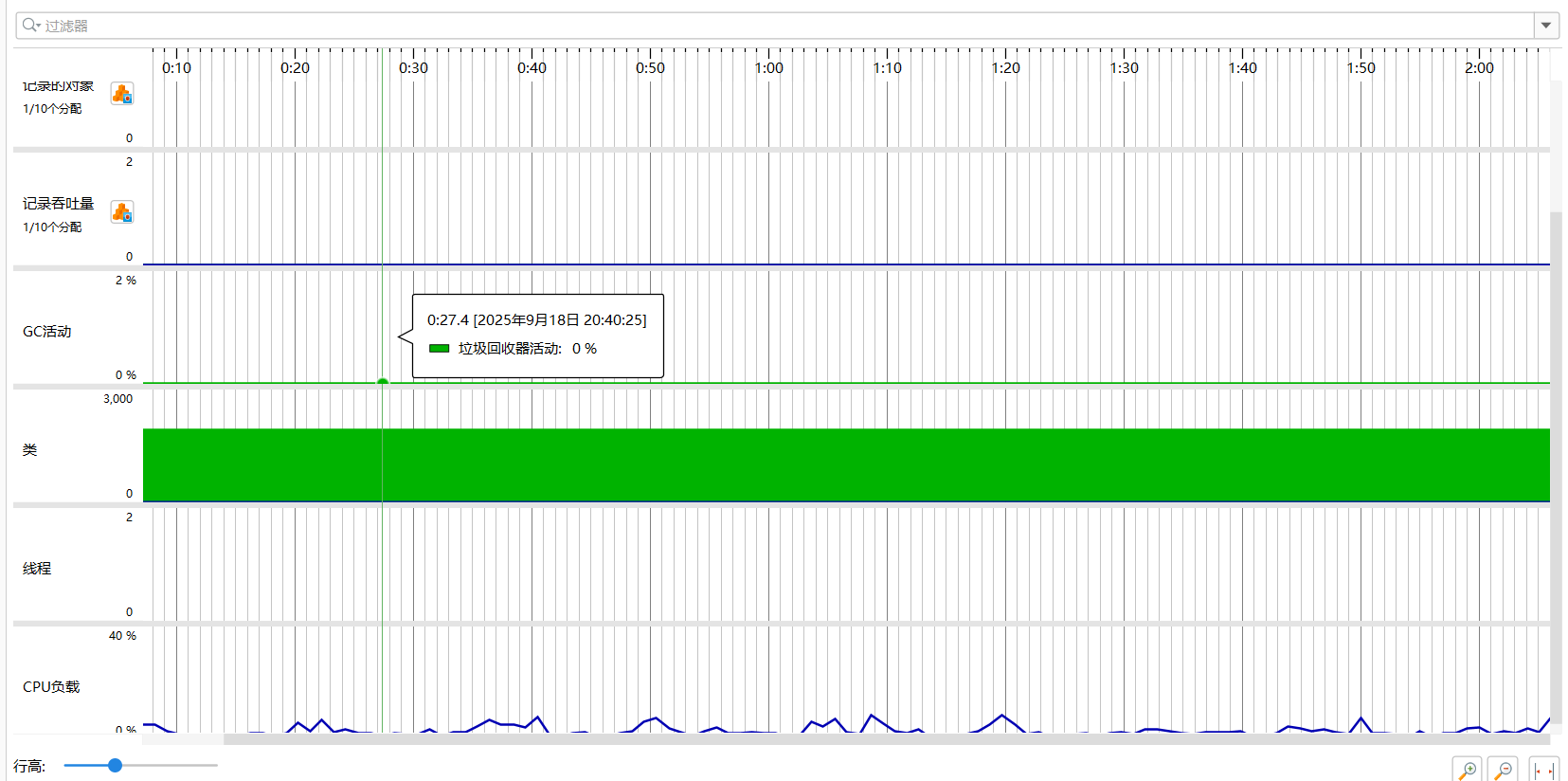
五、计算模块部分单元测试展示
自设计的简单单元测试运行结果如下图
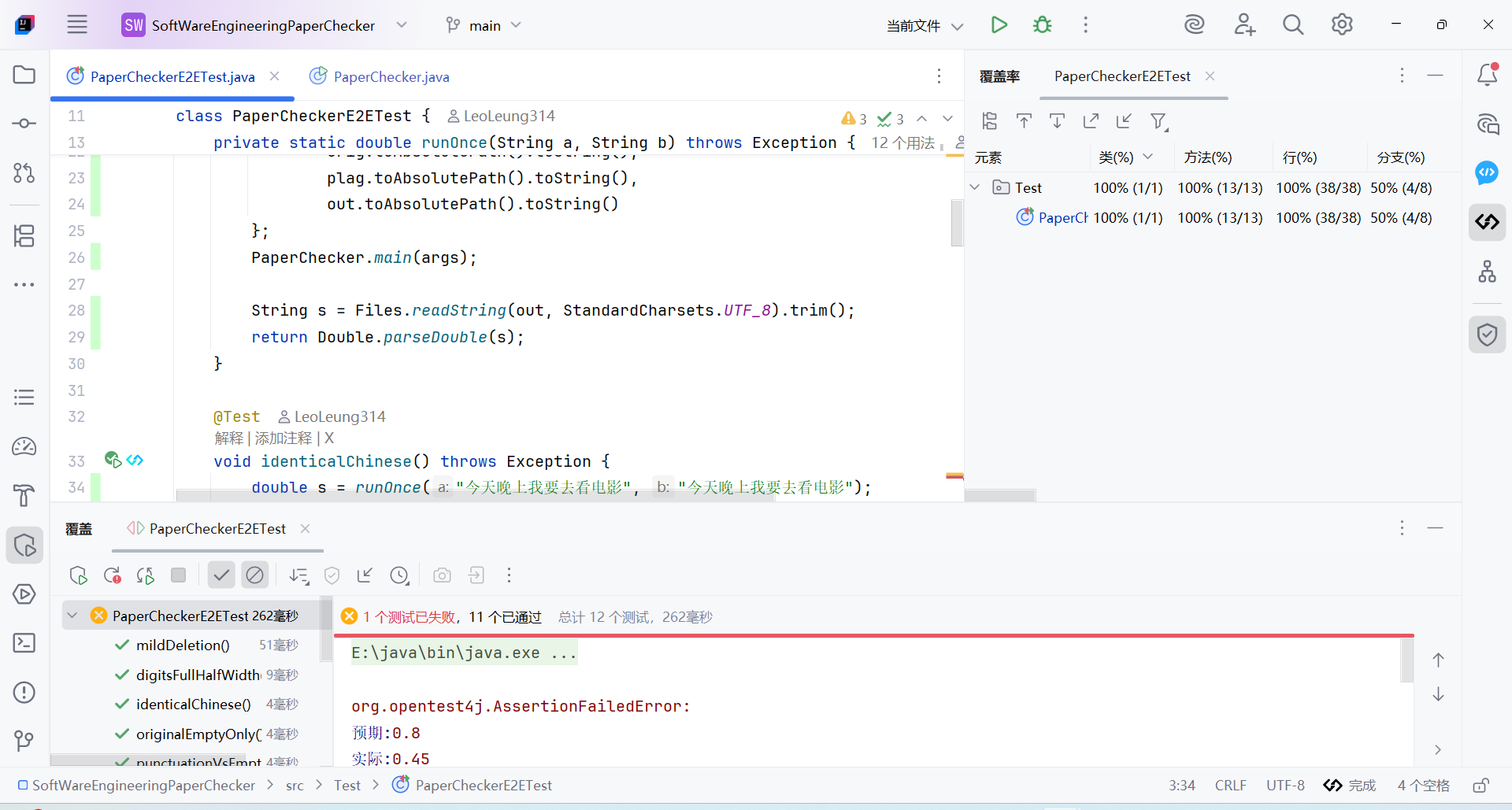
程序运行老师提供的测试用例时覆盖率基本如下图所示
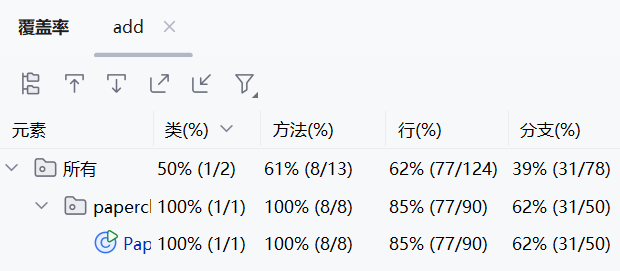
结果:
add
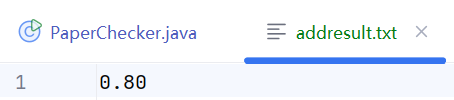
del
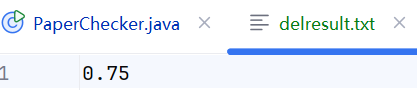
dis1

dis10
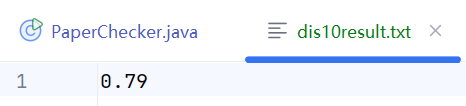
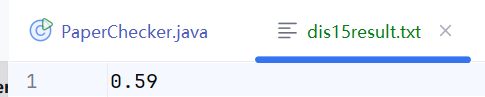
dis15
简单单元测试代码展示
package Test;
import org.junit.jupiter.api.Test;
import paperchecker.PaperChecker;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import static org.junit.jupiter.api.Assertions.*;
class PaperCheckerE2ETest {
private static double runOnce(String a, String b) throws Exception {
Path orig = Files.createTempFile("orig", ".txt");
Path plag = Files.createTempFile("plag", ".txt");
Path out = Files.createTempFile("ans", ".txt");
Files.writeString(orig, a, StandardCharsets.UTF_8);
Files.writeString(plag, b, StandardCharsets.UTF_8);
String[] args = new String[] {
orig.toAbsolutePath().toString(),
plag.toAbsolutePath().toString(),
out.toAbsolutePath().toString()
};
PaperChecker.main(args);
String s = Files.readString(out, StandardCharsets.UTF_8).trim();
return Double.parseDouble(s);
}
@Test
void identicalChinese() throws Exception {
double s = runOnce("今天晚上我要去看电影", "今天晚上我要去看电影");
assertEquals(1.00, s, 1e-9);
}
@Test
void completelyDifferent() throws Exception {
double s = runOnce("abcdef", "uvwxyz");
assertEquals(0.00, s, 1e-9);
}
@Test
void mildDeletion() throws Exception {
double s = runOnce("今天晚上我要去看电影", "我晚上要去看电影");
assertTrue(s > 0.50 && s < 1.00);
}
@Test
void punctuationWhitespaceOnly() throws Exception {
double s = runOnce("今 天,晚上!我要 去看 电影。", "今天晚上我要去看电影");
assertEquals(1.00, s, 1e-9);
}
@Test
void caseOnly() throws Exception {
double s = runOnce("ABC中文", "abc中文");
assertEquals(1.00, s, 1e-9);
}
@Test
void fullHalfWidth() throws Exception {
double s = runOnce("ABC中文", "ABC中文");
assertEquals(1.00, s, 1e-9);
}
@Test
void digitsFullHalfWidth() throws Exception {
double s = runOnce("12345中文", "12345中文");
assertEquals(1.00, s, 1e-9);
}
@Test
void bothEmpty() throws Exception {
double s = runOnce("", "");
assertEquals(1.00, s, 1e-9);
}
@Test
void originalEmptyOnly() throws Exception {
double s = runOnce("", "abc");
assertEquals(0.00, s, 1e-9);
}
@Test
void largeTextNearOne() throws Exception {
String a = "a".repeat(10000);
String b = "a".repeat(9990);
double s = runOnce(a, b);
assertTrue(s >= 0.998 && s <= 1.0);
}
@Test
void punctuationVsEmpty() throws Exception {
double s = runOnce(",。、!", "");
assertEquals(1.00, s, 1e-9);
}
@Test
void smallReorder() throws Exception {
double s = runOnce("ABCDE", "ACBED"); // LCS = 4 => 4/5 = 0.8
assertEquals(0.80, s, 1e-6);
}
}
测试的核心算法模块
public static double NGramSimilarity(String orig, String plag) {
int n = 3;
// 用哈希集存储原文中的所有n-gram组合
Set
for (int i = 0; i <= orig.length() - n; i++) {
origNgrams.add(orig.substring(i, i + n));
}
// 用哈希集抄袭文本中的所有n-gram组合
Set<String> plagNgrams = new HashSet<>();
for (int i = 0; i <= plag.length() - n; i++) {
plagNgrams.add(plag.substring(i, i + n));
}
// 计算交集大小
Set<String> intersection = new HashSet<>(origNgrams);
intersection.retainAll(plagNgrams);
int intersectionSize = intersection.size();
// 计算原文n-gram总数
int originalNgramCount = origNgrams.size();
// 计算抄袭文本n-gram总数
int plagNgramCount = plagNgrams.size();
//使用Dice系数计算相似度,Dice系数 = (2.0 * 交集大小) / (集合1大小 + 集合2大小)
return (originalNgramCount == 0 || plagNgramCount == 0) ? 0.0 : (2.0 * intersectionSize) / (originalNgramCount + plagNgramCount);
}
// 计算字符集合相似度
public static double CharSetSimilarity(String orig, String plag) {
Set<Character> origChars = new HashSet<>();
Set<Character> plagChars = new HashSet<>();
for (char c : orig.toCharArray()) {
origChars.add(c);
}
for (char c : plag.toCharArray()) {
plagChars.add(c);
}
// 计算交集大小
Set<Character> intersection = new HashSet<>(origChars);
intersection.retainAll(plagChars);
int intersectionSize = intersection.size();
// 计算原文字符总数
int origCharCount = origChars.size();
// 计算抄袭文本字符总数
int plagCharCount = plagChars.size();
// 使用Dice系数
return (origCharCount == 0 || plagCharCount == 0) ? 0.0 : (2.0 * intersectionSize) / (origCharCount + plagCharCount);
}
// LCS:二维动态规划实现
public static int LCS(String orig, String plag) {
char[] origCharArray = orig.toCharArray();
char[] plagCharArray = plag.toCharArray();
int origLength = origCharArray.length, plagLength = plagCharArray.length;
if (origLength == 0 || plagLength == 0) {
return 0;
}
int[][] dp = new int[origLength + 1][plagLength + 1];
// 填充动态规划表
for (int i = 1; i <= origLength; i++) {
for (int j = 1; j <= plagLength; j++) {
if (origCharArray[i - 1] == plagCharArray[j - 1]) {
// 字符匹配,LCS长度加1
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
// 字符不匹配,取表中左边或上边的较大值
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
int result = dp[origLength][plagLength];
// 如果两个文本长度差异较大,则适当调整结果
double lengthRatio = (double) Math.max(origLength, plagLength) / Math.min(origLength, plagLength);
if (lengthRatio > 1.5) {
// 长度差异较大时,略微降低LCS值
result = (int)(result * 0.95);
}
// 确保结果不为负数
return Math.max(0, result);
}
六、计算模块部分异常处理说明
空值检查:normalizedText方法中对null输入的处理
空文本处理:calculateSimilarity方法中对空字符串的特殊情况处理
除零保护:在相似度计算中避免除零错误
边界检查:LCS算法中对空字符串的处理
缺陷:三个参数因子的权重需要适时调整以匹配不同类型的抄袭文本,可能会出现不适配的情况,当检验较大文本时,二维DP数组可能会导致内存溢出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号