数据库笔记整理
Mysql相关概念
基本概念
DB( database ) : 存储数据的仓库 , 其中的数据是有组织有关联的
DBMS( database management system ) : 数据库管理系统 , 管理DB
SQL( structure query language ) : 结构化查询语言 , 专门与DB通信的语言 , 多有DBMS( MySQL , Oracle , SQLserver等 )都支持
数据库分类
存储位置的不同进行分类 :
1. 基于磁盘的存储 , MySQL , Oracle , SQLsever
2. 基于内存的存储 , redis非常适合作缓存
从数据之间是否存在关系进行分类 :
1. 关系型数据库 : MySQL , Oracle , SQLsever
2. 非关系型数据库 : redis , mongodb , nosql( not only sq )
数据表
数据库中有数据表 , 数据表由行和列组成 , 表中的每一列称为字段 , 每一列类似Java中的属性 , 每一行类似Java中的对象
字段的数据类型
1. 整形
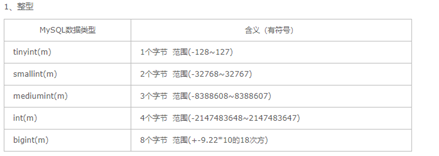
- tinyint(2) 等同于byte 取值范围 -128 - 127
- tinyint(1) 等同于boolean 取值范围 0 , 1
- int(n) n : 查询的时候单元格宽度 , int(11)显示宽度和数据类型的取值范围时无关的 , 如果插入了大于显示宽度的值 , 只要该值不超过该类型整数的取值范围 , 数值依然可以插入 , 而且能够显示出来
- bigint(n) : 等同于long 常用于记录id , 时间的毫秒数
2. 小数

- float(M,D) M称为精度 , 表示总共的位数 , D表示标度 , 表示小数的位数 ,
- double(m,d)
- decimal(m,n) BigDecimale DECIMALE的存储空间并不是固定的 , 而且精度值M决定 , 占用M+2个字节
3. 字符型
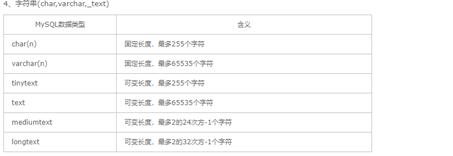
- char(n) 固定长度 , char(4)不管是存入几个字符 , 都将占用4个字符
- VARCHAR和TEXT类型是变长类型 , 其存储需求取决于列值的实际长度 , 一个VARCHAR(10)列能保存一个最大长度为10个字符的字符串
- MySQL不区分字符和字符串 , 单引号和双引号类似
4. 日期型
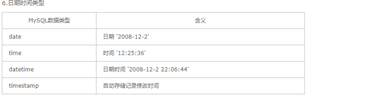
- date : 年月日
- datetime : 年月日 时分秒
- timestamp : 年月日 时分秒 时间戳
SQL语句
结构化查询语言 , sql语句不区分大小写
DDL(Data Definition Language) : 数据定义语言 , 用来定义数据库对象 : 库, 表, 列等; create drop alter
DML(Data Manipulation Language) : 数据操作语言 , 用来定义数据库记录(数据) insert delete update
DQL(Data Query Language) : 数据查询语言 , 用来查询记录select
DCL(Data Controler Language) : 数据控制语言 , 用来定义访问权限和安全级别; commit rollback
DDL
基本操作(库)
1. 创建数据库 :
create database[if not exists]数据库名; (数据库名称不可改变)
2. 删除数据库:
drop database 数据库名;(连着表/数据都一起删除, 数据无法回滚)
3. 查看创建数据库基本信息
show create database 数据库名;
基本操作(表)
1. 创建表
create table 表名(
字段1 数据类型 [约束],
字段2 数据类型 [约束],
...
字段n 数据类型 [约束]
);
2. 表结构 alter
新增新的字段
alter table 表名 add 字段名 数据类型 约束;
删除字段
alter table 表明 drop 字段名;
修改字段名称
alter table 表名 change 旧字段名 新字段名 数据类型 约束;
修改字段的数据类型
alter table 表名 change 字段名 字段名 数据类型 约束;
alter table 表名 modify 表名 数据类型 约束;
修改表名
alter table 旧表名 rename to 新表名;
3. 删除 drop
删除数据库的命令
DROP DATABASE db_test;
删除数据表
DROP TABLE tb_test;
DML
对表数据进行操作
insert
对所有的字段新增数据
insert into 表名 values (数据1,数据2...数据n),(数据1,数据2...数据n);
对指定的字段新增数据
insert into 表名 (字段1,字段2...字段n) values (数据1,数据2...数据n);
编码处理
不能添加中文数据:需要更改mysql服务的编码格式。
mysql的server: 默认的编码格式 latin 改成utf8
mysql的核心配置文件: my.ini
default-character-set=utf8
character-set-server=utf8
delete删除
delete from 表名 [where 条件 ]; 清空表数据 多条记录受影响
update更新
update 表名 set 字段名1 = 值1,字段名2 = 值2 [where 条件];多条记录受影响
DQL语句select
基本语法
select 字段名 /*要查询的字段,多个字段用逗号隔开*/ from 表名 /*要查询的表名称*/ [where 筛选条件/*筛选记录的条件*/ group by 分组条件/*对结果进行分组*/ having 筛选条件 /*对分组后的记录进行条件筛选*/ order by 排序列 /*对结果进行排序*/ limit /*对记录总数进行限定*/]
select后面可以是表中的字段, 常量值, 表达式, 函数 ; 查询的结果是一个虚拟的表格
1, 基础查询 , 查询所有列
SELECT * FROM 表名; -- 指定字段进行查询 SELECT 需要查询的列名查询多条以','隔开 FROM 表名;
2, 条件查询
按条件表达式筛选 >, <, =, !=, <> (不等于), >=, <=
逻辑表达式 && || ! and, or, not
模糊查询 like, between 条件1 and 条件2 (not between and), in(列表中的值不支持通配符), is null(is not null)
判断null使用is


CREATE TABLE t_stu( id INT, sname VARCHAR(10), sgender CHAR(1), age INT, score FLOAT(4,2), birthday TIMESTAMP, courseid INT, createtime date, updatetime date )
-- 指定某一个条件进行查询 SELECT * FROM t_stu WHERE courseid=2 -- AND 是两个条件都要满足 SELECT * FROM t_stu WHERE courseid=2 AND score>60; -- OR是条件只要满足一个就行 SELECT * FROM t_stu WHERE courseid=2 OR score>60; -- 查询sid为 1,6,8的记录,属于某个集合 SELECT * FROM t_stu WHERE sid IN(1,6,8); -- 查询sid不属于 1,6,8的记录 SELECT * FROM t_stu WHERE sid NOT IN(1,6,8); -- 查询记录某个字段为null SELECT * FROM t_stu WHERE sgender is null; SELECT * FROM tb_stu WHERE updatetime IS NOT null; -- 查询成绩在70到90区间范围内的记录 SELECT * FROM t_stu WHERE score BETWEEN 70 AND 90; -- 性别非男的记录 <>和!= 都是 不等于 select * FROM t_stu WHERE sgender <> 'm'; select * FROM t_stu WHERE sgender != 'm';
3. 模糊查询, 处理字符类型
% : 表示0个或多个字符
_ : 任意一个字符
-- 名字由3个字母组成 SELECT * FROM t_stu WHERE sname LIKE '___'; -- 名字由j 开头 SELECT * FROM t_stu WHERE sname LIKE 'j%'; -- 第二个字母为a 的学生记录 SELECT * FROM t_stu WHERE sname LIKE '_a%'; -- 查询姓名中包含字母a的记录 SELECT * FROM t_stu WHERE sname LIKE '%a%';
4. 去重查询&其别名
表或字段可以起别名 , 起别名便是利于理解 , 如果查询的字段有重名的情况使用别名可以区分 , AS可省略 使用空格
-- 查询学生表中的所有性别 SELECT DISTINCT sgender FROM t_stu ; -- 给查询出的字段起别名 AS是可以省略的 使用空格 SELECT age AS 年龄,sname AS 姓名 FROM tb_stu; SELECT sid a,sname b,sgender gender,score c FROM t_stu;
5. 排序order by子句可以跟单个字段, 多个字段, 表达式, 函数, 别名
-- 查询所有学生记录,按成绩进行降序排序 -- 缺省是ASC升序 SELECT * FROM t_stu ORDER BY score DESC; -- 查询所有学生记录,首先先按成绩进行降序排序,如果成绩相同,按名字进行升序排序 SELECT * FROM t_stu ORDER BY score DESC, sname ASC;
6. 组函数/聚合函数/分组函数
用于统计使用, 又称为聚合函数或统计函数或组函数
聚合函数是用来纵向运算的函数
COUNT(字段) : 统计指定列不为NULL的记录行数; 一般使用COUNT(*)统计行数
MAX(字段) : 计算指定列的最大值 , 如果指定列是字符串类型 , 那么使用字符串排序运算
MIN(字段) : 计算指定列的最小值 , 如果指定列是字符串类型 , 那么使用字符串排序运算
SUM(字段) : 计算指定列的数值和 , 如果指定列类型不是数值类型 , 那么计算结果为0
AVG(字段) : 计算指定列的平均值 , 如果指定列类型不是数值类型 , 那么计算结果为0
sum,avg一般处理数值类型
max,min,count可以处理任意数据类型
分组函数忽略了null值 , 可以和distinct搭配使用
注意 : 组函数可以出现多个 , 但是不能嵌套使用 , 如果没有group by字句 , 结果集中所有行数作为一组
CREATE TABLE DEPT (DEPTNO int(2) not null , DNAME VARCHAR(14) , LOC VARCHAR(13), primary key (DEPTNO) ); CREATE TABLE EMP (EMPNO int(4) not null , ENAME VARCHAR(10), JOB VARCHAR(9), MGR INT(4), HIREDATE DATE DEFAULT NULL, SAL DOUBLE(7,2), COMM DOUBLE(7,2), primary key (EMPNO), DEPTNO INT(2) ) ; CREATE TABLE SALGRADE ( GRADE INT, LOSAL INT, HISAL INT );
-- 查询emp表中有佣金的人数,统计指定列不为NULL的记录行数 SELECT count(comm) a FROM emp; SELECT count(empno) 总人数 FROM emp; SELECT count(*) 总人数 FROM emp; SELECT count(1) 总人数 FROM emp; -- 查询emp表中有佣金的人数 SELECT count(comm) from emp; -- 查询emp表中月薪大于2500的人数: SELECT * FROM emp WHERE sal>2500; -- 统计月薪与佣金之和大于2500元的人数: ifnull(表达式1,表达式2) 如果表达式1为null那么取表达式2的值,否则取表达式1的值 SELECT * FROM emp WHERE sal+ifnull(comm,0) >2500; 查询有佣金的人数,以及有领导的人数: SELECT count(comm) FROM emp WHERE mgr is not null; -- 查询所有雇员月薪和: SELECT sum(sal) 总薪资 FROM emp; -- 查询所有雇员月薪和,以及所有雇员佣金和: SELECT sum(sal) 总薪资,SUM(comm) 总佣金 FROM emp; -- 查询所有雇员月薪+佣金和 SELECT sum(sal+ifnull(comm,0)) 总佣金 FROM emp; SELECT sum(sal)+sum(ifnull(comm,0)) 总佣金 FROM emp; -- 统计所有员工平均工资 SELECT avg(sal) 平均薪资 FROM emp; -- 查询最高工资和最低工资 SELECT max(sal),min(sal) FROM emp;
7.group by分组查询
查询出来的字段要求是group by后的字段 , 查询字段中可以出现组函数
group by后面可以跟聚合函数 , 可以其别名
-- 查询每个部门的部门编号和每个部门的工资和 SELECT deptno,SUM(sal) FROM emp GROUP BY deptno; -- 查询每个部门的部门编号以及每个部门的人数 SELECT deptno,SUM(sal),COUNT(1) FROM emp GROUP BY deptno; -- 查询每个部门的部门编号以及每个部门员工工资大于1500的人数: SELECT deptno,COUNT(1) FROM emp WHERE sal>1500 GROUP BY deptno;
按多个字段分组, 后面字段一致的为一组
-- 按job进行分类 SELECT COUNT(*),job FROM emp GROUP BY job; -- 按job和mgr进行分类 SELECT COUNT(*),job,mgr FROM emp GROUP BY job,mgr;
8, having子句
where是对分组进行过滤; having是对分组后进行过滤
where中不能出现分组/聚合函数, having中可以出现
where是比分组先执行的 , having是在分组后执行的
having后面可以跟别名
-- 查询工资总和大于9000的部门编号以及工资和: SELECT deptno,sum(sal) FROM emp GROUP BY deptno HAVING sum(sal)>9000; -- having中使用别名 SELECT deptno,sum(sal) 总薪资 FROM emp GROUP BY deptno HAVING 总薪资>9000;
-- 查询部门员工个数大于3的,having中使用了别名 SELECT COUNT(1) cc,deptno FROM emp GROUP BY deptno HAVING cc>3;
9, limit
-- 第一位表示起始索引位置,第二位表示总的长度;在分页中会使用 SELECT * FROM emp LIMIT 1,5; SELECT * FROM emp LIMIT 5; 等价与 SELECT * FROM emp LIMIT 0, 5;
10, 多表查询, 关联查询
内连接
- 多表等值连接的结果是多表的交集部分, N表连接, 至少需要N-1个连接条件, 没有顺序需求, 一般起别名
- 非等值连接, 只要不是等号连接的都是非等值连接
外连接 , 有主表有从表 , 主表肯定会显示完整的内容
- 左外连接 , 以左表为主
- 右外连接 , 以右表为主
-- 查询员工信息,要求显示员工号,姓名,月薪,部门名称 -- 笛卡尔积 (a, b) (1,2,3) --(a,1) (a,2) (a,3) (b,1) (b,2) (b,3)--》会生成一个中间表 -- 多表查询,关联条件使用的是等号 -- 查询员工信息,要求显示员工号,姓名,月薪,部门名称 等值连接 SELECT empno,ename,sal,emp.deptno,dname FROM emp,dept WHERE emp.deptno=dept.deptno; -- 给表起别名 SELECT empno,ename,sal,a.deptno,dname FROM emp a,dept b WHERE a.deptno=b.deptno; -- 非等值连接 -- 查询员工信息,要求显示:员工号,姓名,月薪,薪水的级别 SELECT empno,ename,sal,GRADE FROM emp e,salgrade sa WHERE e.sal BETWEEN sa.LowSAL AND sa.HISAL; -- 外连接 -- 查询员工信息,要求显示员工号,姓名,月薪,部门名称 使用内连接和等值连接等同 SELECT empno,ename,sal,emp.deptno,dname FROM emp INNER JOIN dept on emp.deptno=dept.deptno; -- 左外连接 左边的表内容全部显示,右边的表没有的以null进行填充 SELECT empno,ename,sal,emp.deptno,dname FROM emp LEFT JOIN dept on emp.deptno=dept.deptno; -- 右外连接,右表内容全部显示,左表没有的以null进行填充 SELECT empno,ename,sal,emp.deptno,dname FROM emp RIGHT JOIN dept on emp.deptno=dept.deptno;
ON后面的条件(ON条件)和WHERE条件的区别
ON条件 : 是过滤两个链接表笛卡尔积形成中间表的约束条件
WHERE条件 : 在没有ON的单表查询中 , 是限制物理表或者中间查询结果返回记录的约束 , 在两表或多表连接中是限制连接形成最终中间表的返回结果的约束
建议 : ON只进行连接操作 , WHERE只过滤中间表的记录
11, 自连接 , 通过别名 , 将同一张表示为多张表 ; 同一张表中某个字段要去关联另一个字段
-- 查询员工姓名和员工的老板的名称 SELECT e1.empno,e1.ename,e2.empno,e2.ename FROM emp e1, emp e2 WHERE e1.mgr=e2.empno;
12, 子查询
以一个查询的结果为另一个查询的条件
-- 查询工资为20号部门平均工资的员工信息 SELECT * FROM emp WHERE sal>(SELECT AVG(sal) FROM emp GROUP BY deptno HAVING deptno=20);
约束
约束是为了表的数据的正确性 , 如果数据不正确 , 那么一开始就不能添加到表中
非空约束(not null)
指定非空约束的列不能没有值 , 也就是说在插入记录时 , 对添加了非空约束的列一定要给值 ; 在修改记录时 , 不能把非空列的值设置为NULL
CREATE TABLE a( id INT NOT NULL, sname VARCHAR(20) ) -- 提示错误:Field 'id' doesn't have a default value
唯一性约束(nuique)
当为字段指定唯一性约束后 , 那么字段的值必须唯一(null值除外)
CREATE TABLE b( id INT NOT NULL UNIQUE )
默认约束(default)
当字段指定默认约束后 , 给字段一个默认值
CREATE TABLE c( id INT NOT NULL DEFAULT 6, sname VARCHAR(3) )
主键约束(primary key)
当某一咧添加了主键约束后 , 那么这一列的数据就不能重复出现 , 这样每行记录中其主键列的值就是这一行的唯一表示 , 主键列的值不能为NULL , 也不能重复
任意类型的字段都可以充当主键 , 一个表有且只有一个主键
如果主键列是整数类型 , 一般不会手动赋值 , 都是结合mysql的sever自动维护主键列的数据 (自增特性 , 主键自增长 , auto_increment)
create table d( id int primary key auto_increment, name varchar(20) not null UNIQUE, age tinyint(2) ); insert into d (name,age) values ('张三',20); 修改自增的初始值: alter table 表名 auto_increment = 初始值;
如果主键约束是字符串类型 , 一般不会手动给值 , 都是结合mysql的sever自动维护主键列的数据
create table a( id varchar(64) primary key , name varchar(20) not null UNIQUE, age tinyint(2) ); insert into a (id,name,age) values (uuid(),'张三',20);
外键约束
- 主外键是构成表与表关联的唯一途径
- 外键代表着另一张表的主键 , 外键的值必须从另一张表的主键中选择
- 外键是另一张表的主键 , 例如员工表与部门表之间存在关联关系 , 其中员工表中的部门编号字段就是外键 , 是相对部门表的外键
create table tb_type( id int primary key auto_increment, typename varchar(20) not null unique, desc varchar(100), createtime datetime, updatetime datetime );
create table tb_good( id int primary key auto_increment, gname varchar(20) not null unique, price float(10,2) not null, createtime datetime, updatetime datetime, );
需要将商品表与类型表进行一对一的关联关系
商品表(从表/子表)typeid的数据要严格参照类型表(主表)主键id的数据
Alter table tb_good add typeid int(2); alter table tb_good add CONSTRAINT fk_typeid FOREIGN key (typeid ) REFERENCES tb_type (id); RESTRICT: 删除,修改都是受限。 CASCADE: 级联操作。 (不能使用) SET NULL: 前提:外键列可以为null。(可以使用)
外键不推荐使用,弱化外键。(所有的关联都在逻辑层面进行处理)
常用函数
注意 : MySQL中的'+'就只有运算符的功能 ; 会试图将字符型数值转换成数值型在继续操作 , 转换失败则转为0 ; 若其中有Null则结果为null ; 字符串可以使用concat函数进行拼接
字符串函数:
length(str) 得到的是自己而个数utf8的中文是3个字节
char_length(str) 返回字符串str的长度
insert(str1,pos,len.newstr) 字符串str从第pos位置开始的len个字符替换成新自负newstr
ipad(str,len,padstr) 返回字符串str , 其左边由字符串padstr填补到len字符串长度
rpad(str,len,padstr) 返回字符串str , 其右边由字符串padstr填补到len字符串长度
concat(str1,str2) 拼接字符串
upper/lower(str) 转为大/小写
substring(str,pos,len) 从字符串str的pos位置起len个字符长度子串
instr(str,substr) 返回字符串第一次出现的索引 , 找不到则为0
trim(str) 去除字符串头尾空格
repeat(str,cont) 返回str重复count次的结果
replace(str,from_str,to_str) 用字符串to_str替换字符串str中所有的字符串from_str
-- 字符串连接 SELECT concat('java','sun','aa'); -- length() SELECT length(sname),sname FROM tb_stu; -- 指定位置插入 SELECT INSERT('javasun',5,3,'oracle'); -- 字符长度 SELECT CHAR_LENGTH('java'); -- 左填充 SELECT lpad('java',9,'bb'); -- 右填充 SELECT rpad('java',10,'c'); -- 去除前后空格 SELECT trim(' ja va '); -- 重复指定次数 SELECT repeat('ja',4); -- 字符串替换 SELECT REPLACE('javaoror','or','sun'); -- 截取字串 SELECT substring('javasun',5,3);
数值函数:
ABS(X) 返回x的绝对值
CEIL(X) 返回不小于x的最大整数
FLOOR(X) 返回不大于x的最大整数
MON(X,Y) 返回x/y的模
RAND() 返回一个0-1之间的随机浮点数
ROUND(X,Y) 返回数字x的四舍五入的有Y位小数的值
TREUNCATE(X,Y) 返回数字x截断位y位小数的结果
MOD(X,Y) 取x除以y的余数
-- 取绝对值 SELECT abs(-32); -- 向上取最小整数 SELECT ceil(3.2); -- 向下取最大整数 SELECT floor(3.2); SELECT floor(score),score FROM tb_stu; -- 取余数 SELECT mod(21,3); -- 得到 0-1直接的随机值 SELECT rand(); -- 有2位小数的四舍五入值 SELECT round(5.678,2); -- 截断,小数位保持2位 SELECT TRUNCATE(5.67888,2);
日期函数:
CURDATE() 返回当前日期 , 不包含时间
CURTIME() 返回当前时间 , 不包含日期
NOW() 返回当前的时间和日期
WEEK(date) 返回指定日期为一年中的第几周
YEAR(date) 获取指定的年份
HOUR(time) 返回time的小时制
MINUTE(time) 返回time的分钟值
MONTHNAME(date) 返回date的月份
DATEDIFF(expr,expr2) 返回起始时间expr和结束时间expr2之间的天数
DATE_FORMATE(date,fmt) 返回按字符串fmt格式化日期date值
from_unixtime(unix_timestamp,"%Y-%m-%d %H:%i:%S") 常用来将毫秒值转换为时间格式
| %M 月名(January---December) | %b 缩写的月份名(Jan---Dec) | %s 秒(00-59) |
| %W 星期名(Sunday---Saturday) | %j 一年中的天数(001---366) | %S 秒(00-59) |
| %D 有英语前缀的月份的日期(1st,2nd,3rd...) | %H 小时(00---23) | %p AM或PM |
| %Y 年 , 数字 , 4位 | %k 小时(0---23) | %w 一个星期中的天数(0=Sunday---6=Saturday) |
| %y 年 , 数字 , 2位 | %h 小时(01---12) | %U 星期(0---52)这里星期天是星期的第一天 |
| %a 缩写的星期名(Sun---Sat) | %I 小时(1---12) | %u 星期(0---52) 这里星期一是星期的第一天 |
| %d 月份中的天数 , 数字(00---31) | %i 分钟 , 数字(00---59) | %% 一个文字"%" |
| %e 月份中的天数 , 数字(0---31) | %r 时间 , 12小时(hh:mm:ss[AP]M) | |
| %m 月 , 数字(01-12) | %T 时间 , 24小时(hh:mm:ss) | |
| %c 月 , 数字(1---12) | %S 秒(00---59) |
-- 当前日期,当前时间,日期和时间 SELECT CURDATE(),CURTIME(),now(); -- 指定日期是一年中的第几周 SELECT WEEK(now()); -- 返回指定日期的年份 SELECT YEAR(now()); -- 返回指定时间的小时 SELECT hour(now()),hour(CURTIME()); -- 返回date的月份名 SELECT MONTHNAME(now()); -- 计算时间相隔的天数 SELECT DATEDIFF('2021-1-15','2021-1-12'); SELECT DATEDIFF(now(),'2021-1-10'); -- 把日期按指定的格式进行转换 SELECT DATE_FORMAT(now(),'%Y-%m-%d %H:%i:%s'); -- 把字符串转日期 SELECT STR_TO_DATE('2021-1-12','%Y-%m-%d'); -- 将毫秒数转换为时间格式 SELECT FROM_UNIXTIME(646545353);
其他函数
verson() 版本号
user() 当前用户
if(exp1,exp2,exp3)如果exp1为ture取exp2的值否则取exp3的值
SELECT VERSION(); SELECT USER(); SELECT DATABASE(); SELECT IF(10>2,'10','2') a;
数据库范式
第一范式(1NF)用来确保每列的原子性 , 要求每列(或者每个属性)都是不可再分的最小数据单位(也成为最小的原子单位)
第二范式(2NF)在第一范围的基础上更近一层 , 要求表中的每列都和主键有关 , 即要求试题的唯一性 , 如果一个表满足第一范式 , 并且除了主键意外的其他列全部都依赖于该主键 , 那么该表满足第二范式
第三范式(3NF)在第二范式的基础上更近一层 , 第三范式是确保每列都和主键列直接相关 , 而不是间接相关 , 即限制列的冗余性 , 如果一个关系满足第二范式 , 并且除了主键以外的其他列都依赖于主键列 , 列和列间不存在相互依赖关系 , 则满足第三范式
数据库存储引擎 : 在MySQL中的数据使用不同的存储技术存储在文件或内存中
-- 查看MySQL中所用的存储引擎 show engines;
innodb是支持事物的
myisam , memory不支持事务
数据库事务
什么是事务
- Transaction
- 事务,只是一个操作的集合,是一个程序的执行单元
- 事务 : 一个最小的不可再分的工作单位 ; 通常一个事务对应一个完成的业务(例如银行账户转账业务 , 该业务就是一个最小的工作单位)
- 一个完成的业务需要批量的DML(insert , update , delete)语句共同联合完成
- 事务只和DML语句相关 , 或者说DML语句才有事务 , 这个和业务逻辑有关 , 业务逻辑不同 , DML语句的个数不同
事务死他特性ACID
- 原子性(Atonicity) : 事务是不可分割的最小工作单位 , 业务内的操作要么做 , 要么全不做 , 事务具有要么全部成功 , 要么全部失败
- 一致性(Consistency) : 在事务执行前和事务执行完成后 , 数据库的数据依然处于正确状态 , 即数据完整性约束没有被破坏 , 如A给B转账 , 不论转账是否成功A和B的账户总额和转账之前是相同的
- 各理性(Isonlation) : 当多个事务处于并发访问同一个数据库资源时 , 事务之间互相影响 , 不同的隔离级别决定了各个事务对数据资源访问的不同行为
- 持久性(Durability) : 事务一旦执行成功 , 它对数据库的改变是不可逆的
在业务逻辑层 , 一个service层可能需要执行一次或多次增删改操作 , 如果着期间发生了异常 , 数据库事物如果不回滚数据库中的数据就会不完整 , 例如 : 订单信息中包含了订单明细 , 现在在保存订单的业务逻辑方法中 , 现保存订单成功了 , 在保存订单明细 , 如果保存订单明细的过程中失败了 , 可定希望之前的保存订单数据回滚
和事务相关的语句
- 开启事务 : start transaction | begin
- commit : 提交
- rollback : 回滚
事务何时开启何时结束
开始表示 : Mysql默认情况下任何一条DML语句(insert update delete)执行 , 标志事务的开启
结束标志 :
- 提交 : 成功的结束 , 将所有的DML语句操作历史记录和底层数据来一次同步
- 回滚 : 失败的结束 , 将所有的DML语句操作历史记录全部清空
事务和底层数据库的关系
在事务进行的过程中 , 为结束之前 , DML语句是不会更改底层数据 , 只是将历史操作记录一下 , 在内存中完成记录 , 只有在事务结束的时候 , 而且是成功结束的时候 , 才会修改底层硬盘文件中的数据 , 如果执行失败 , 则清空内存中所有的历史操作记录 , 不会对底层文件中(数据表)数据作任何操作
-- 开启事务 START TRANSACTION; INSERT into tb_stu(sid,sname) VALUES(5,'jerry'); -- rollback 的执行不会更新 磁盘文件 -- commit是事务执行成功 提交 COMMIT;
在MySQL中事务的提交和回滚
在MySQL中 , 默认情况下 , 事务是自动提交的 , 也就是说 , 只要执行一条DML预计就开启了事务 , 并且提交了事务 , 自动提交机制是可以关闭的 , 可以有程序控制何时提交
事务的隔离级别
并发情况下事务引发的问题
一般情况下 , 多个单元操作并发执行 , 会出现这么几个问题
- 脏读 : A事务还未提交 , B事务就读到了A事务的结果(破坏了隔离性)
- 不可重复读 : A事务在本次事务中 , 对自己未操作的事务进行了多次读取 , 结果出现了不一致或记录不存在的情况(破坏了一致性 , 特性是update , delete)
- 幻读 : A事务在本次事务中 , 对自己未操作的事务进行了多次读取 , 第一次读取时记录不存在 , 第二次读取时记录出现了(破坏了一致性 , insert)
不同事务之间具有隔离性 , 隔离级别分四个 :
为了权衡 ' 隔离 ' 和 ' 并发 ' 的矛盾 , ISO定义了四个事务的隔离级别 , 每个级别的隔离程度不同 , 允许出现的副作用也不同
- 读未提交 : read uncommitted(读到未提交的数据) 最低一级别 , 只能保证持久性
- 读已提交 : read committde(读到以提交的数据) 语句级别
- 可重复读 : repeatable read 事务级别
- 串行化 : serializable 最高级别 , 事务与事务完全串行化执行 , 毫无并发可言 , 性能较低
show variables like 'transaction_isolation';
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交 : read uncommitted | 会 | 会 | 会 |
| 读已提交 : read committde | - | 会 | 会 |
| 可重复读 : repeatable read | - | - | 会 |
| 串行化 : serializable 最高级别 | - | - | - |
