

保险索赔分析
一、基本情况
保险业有着大量的数据,对其中蕴含的信息,需要通过数据分析和挖掘的手段进行提取,并应用于客户分析、产品分析、理赔分析、风险控制等诸多方面。
本文利用一份包含约2万条索赔信息的保险数据集进行分析和挖掘。其中每一条信息涵盖索赔额、赔付额、渠道、地域以及客户的性别、年龄等。主要考查支付额、索赔额以及两者的比值(在本文中称其为支索比)这几项指标的基本特征以及影响因素。然后利用机器学习建立用户画像。
二、数据初探
1.先看索赔额、支付额以及支索比三项指标的大致情况。
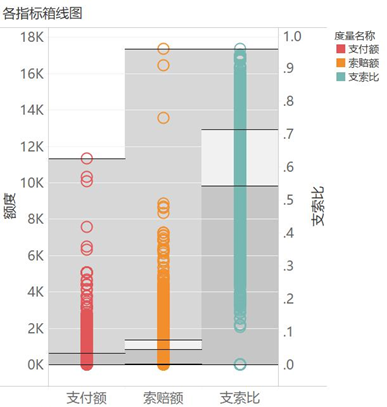
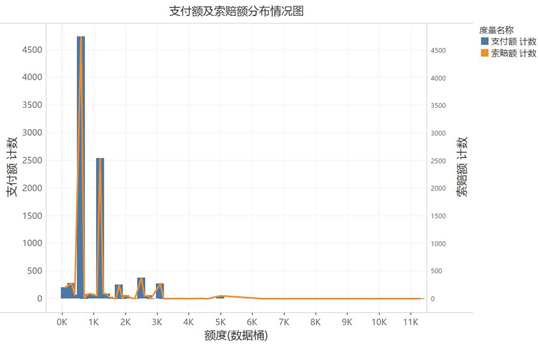
支付额约90%集中在1200元以内,低于650元的占比约75%,值得注意的是,为0元的占比接近40%。
索赔额则约90%集中在1900元以内,低于1300元的占比约75%,中位数是825元。
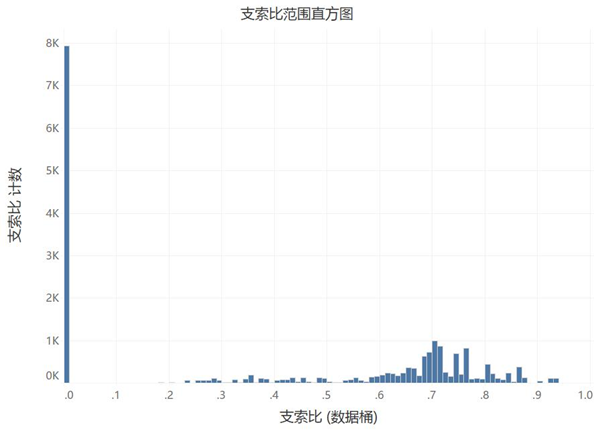
支索比约50%集中在0.58-0.78之间, 为0的有40%(同支付额),其它部分占比约10%。
2.然后来看不同区域的情况
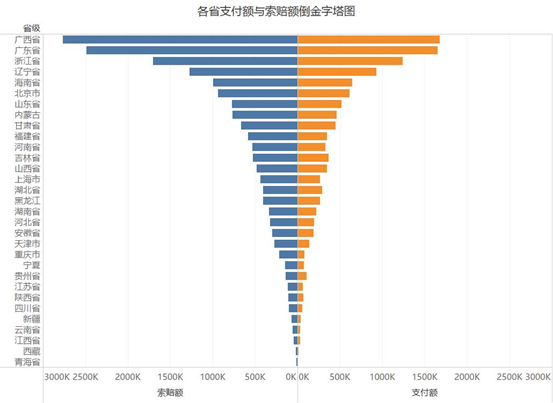
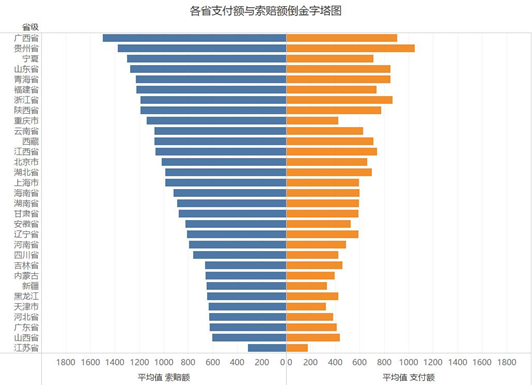
上图第一张是支付及索赔的总额,第二张是平均值。可以通过对比看出各省的情况。比如广东的总额高,但平均值低,则可以初步判断,广东省有较多的优质客户。
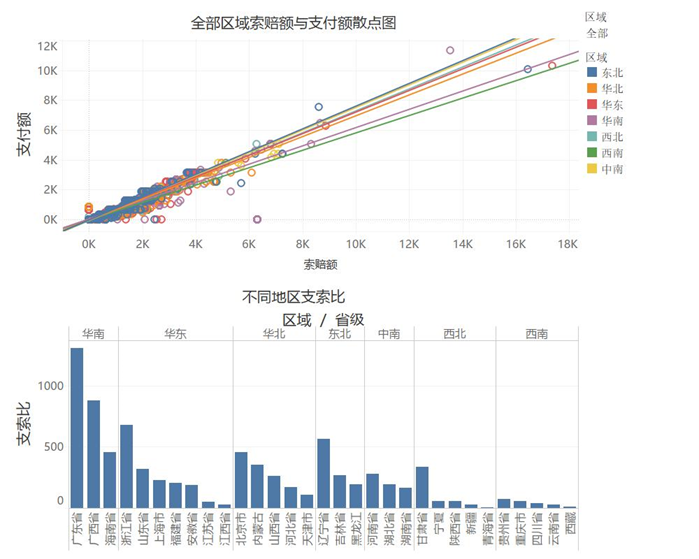
从区域上看,支索比由高到低依次是华南>华东>华北>东北>中南>西北>西南。
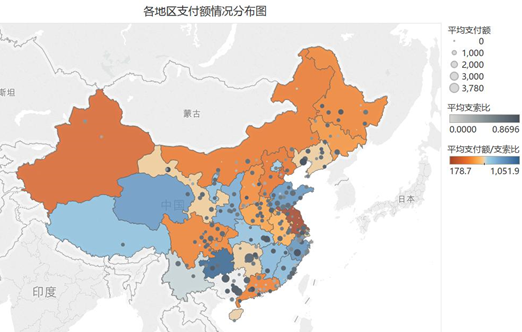
有一项特征为“服务中心”,其分析与对不同地区的分析过程基本相同,后面不赘述。
3.再考查各指标随时间的变化情况。在tableau仪表板中,我们通过设计,显示指定地域和指标随时间变化情况。此处仅以华南&西南的平均支付额随时间变化为例进行说明,见下图:
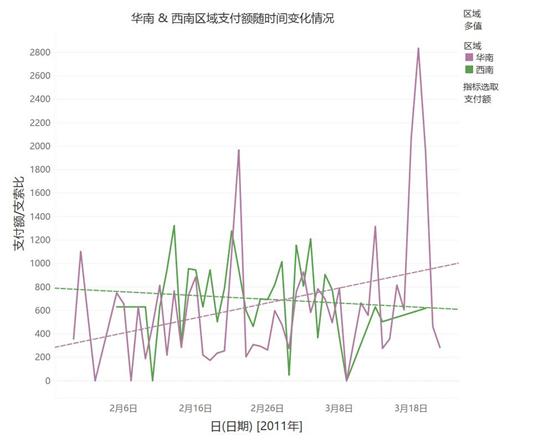
在2011年1月30-3月21日期间,华南地区人均支付额以12.8元/日的增幅上升,西南地区人均支付额则以3.2元/日的幅度下降。
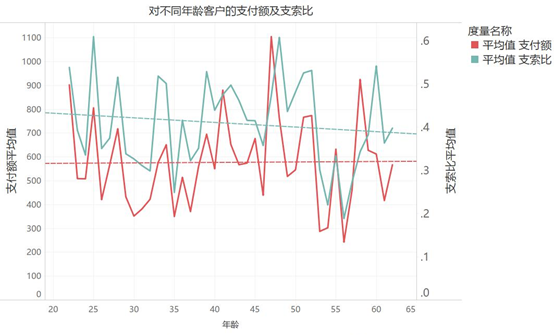
4.查看不同年龄客户的差别,发现平均支付额和支索比随年龄变化的增减趋势并不明显,暂时判定年龄不是主要影响因素。
5.性别因素的影响。
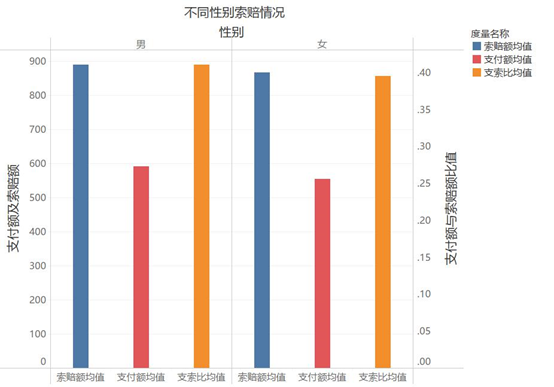
可以看出,男性的索赔额、支付额、支索比均略高于女性,但差别不大。
6.客户提交索赔的渠道有通过医生、手机、网络三种。不同渠道的客户索赔情况。从总额来看,使用渠道比例由高到低依次是网络、手机、医生。通过医生的比例较少,而支索比偏高。原因可能是,通过该渠道的客户具备较好的经济条件,能够得到相对充分的建议。通过手机端的客户支索比则明显较低,分析其原因,由于手机操作的便利,该类客户在发起索赔时可能具有更大的随意性。
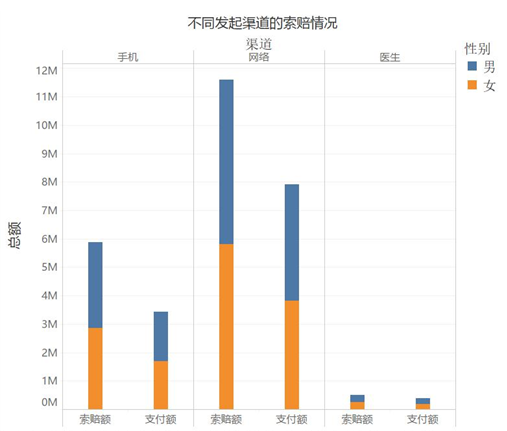
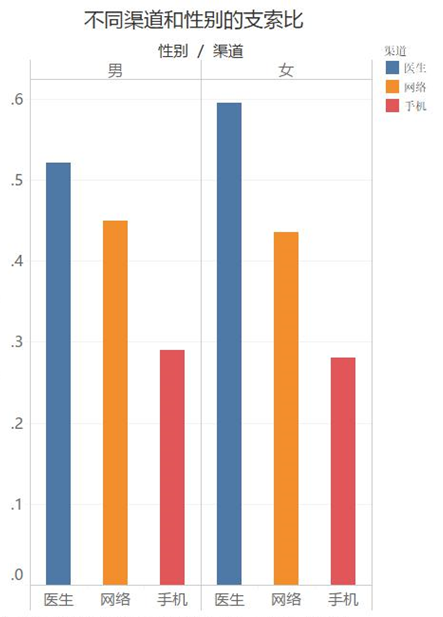
三、机器学习对客户进行分类(用户画像)
根据前面的分析,按照支索比为0,0-0.58,0.58-0.78,0.78-1将客户分为4类。选取省份、索赔渠道、性别,服务中心为基本特征组合,用k-邻近分类算法预测各种条件的客户会属于哪一类。
各项特征及客户类别转为整数值表示,同时将支索比缺失项定义为一个整数值。用交叉验证来观察模型的效果。设置两层循环,一层选取k折交叉验证中的最优k值,一层从基本特征组合中选取最佳组合。
最后得到的结果,在14折交叉验证下取得0.56的平均准确率,基本特征组合即为最优特征组合。考虑到原始数据中可用于建模的特征数量及与支索比的相关程度,这样的结果基本达到预期效果。
python代码如下:
import numpy as np import pandas as pd from sklearn.preprocessing import LabelEncoder from sklearn.neighbors import KNeighborsClassifier # plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 # plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 pd.set_option('display.width', 500, 'display.max_rows', 100, 'display.max_columns', None) # 设置数据显示 data=pd.read_excel("../data/data.xls") # 导入数据 # 省级数据整数化 tmp1=data["省级"].drop_duplicates(keep='first').values # 取出省级列数据,去重,返回数组 size_mapping1={} for i in range(0,len(tmp1)): size_mapping1[tmp1[i]]=i # 字典,省级映射为整数 # print(size_mapping) data["省级"] = data["省级"].map(size_mapping1) # 将省级列根据映射转为整数 # 服务中心数据整数化 tmp2=data["服务中心"].drop_duplicates(keep='first').values # 取出服务中心列数据,去重,返回数组 size_mapping2={} for i in range(0,len(tmp2)): size_mapping2[tmp2[i]]=i # 字典,服务中心映射为整数 data["服务中心"] = data["服务中心"].map(size_mapping2) # 将服务中心列根据映射转为整数 # 性别数据整数化 data["性别"][data["性别"]=="女"]=0 data["性别"][data["性别"]=="男"]=1 # 渠道数据整数化 data["源代码"][data["源代码"]=="网络"]=0 data["源代码"][data["源代码"]=="手机"]=1 data["源代码"][data["源代码"]=="医生"]=2 # 支索比分组 data["支索比"]=data["总支付额"]/data["总索赔额"] data["支索比"][data["支索比"]>=0.78]=3 data["支索比"][(data["支索比"]>0.58) & (data["支索比"]<=0.78)]=2 data["支索比"][(data["支索比"]>0) & (data["支索比"]<0.58)]=1 data["支索比"][data["支索比"]==0]=0 data["支索比"].notnull().astype(int) # 转为整数 # k-折交叉验证 def c_validation(k): z=["省级","性别","源代码","服务中心"] score=[] # 记录评分的列表 temp0=[] # 记录当前选取的特征组合的评分 temp1=0 # 记录当前选取组合的平均分数 temp2=0 # 记录当前选取组合的分数标准差 import itertools for j in range(1,5): for i in itertools.combinations(z, j): # 取包含j个属性的特征组合 i=list(i) from sklearn import cross_validation from sklearn.model_selection import cross_val_score knc_kf=KNeighborsClassifier() # 定义一个k-邻近分类器 x =data[i] # ["省级","性别","服务中心","源代码"] y =data["支索比"].fillna(100) # null填充为100 score=cross_val_score(knc_kf, x, y, cv=k) # 交叉验证分数列表 if (score.mean() > temp1 and score.std() < 0.08): # 特征组合选取条件,标准差在指定范围,平均分最大 temp0 = score temp1 = score.mean() temp2 = score.std() dict = {temp1: i} return dict, temp0, temp1, temp2 score_k=0 for k in range(5,17): print(k) c_vl=c_validation(k) if c_vl[-2]>score_k: score_k=c_vl[-2] c_vlm=c_vl k_m=k print(score_k,c_vlm,k_m)
数据来源:tableau社区http://www.tableauhome.com.cn/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号