2021-OO-第三单元总结
一、作业概况分析
面向对象构造与设计第三单元要求我们根据指导书中给出的JML规格实现相应的功能,保证程序设计的正确性。我们根据JML的要求,来对给定限制范围输入变量进行处理,并且保证输出符合相应的规则,同时对异常进行处理,模拟了工程标准下的代码编写任务。由于大部分代码由官方包给定,本次作业相较于前几单元更加简单,只要细心就可以拿到较高分数,可以更有时间去研究性能上的提升。
二、设计策略
完成本单元的作业的时候,我的设计策略主要可以分为三个阶段。
-
单纯翻译:既然规格已经给定,那么就严格按照规格办事
-
容器使用数组
-
全部功能使用循环遍历
-
优点:正确性无可置疑
-
缺点:性能表现极差
-
-
优化
-
对JML进行等价转换(翻译)
-
第一次作业
-
两个id对应的人之间是否可以通过isLinked连通 = isCircle
-
图中是否连通块的数量 = queryBlockSum
-
-
-
对算法和数据结构进行优化
-
第一次作业
-
容器的实现
-
使用ArrayList等顺序结构存储对象(一定超时)
-
使用HashMap等索引结构存储对象
-
-
isCircle
-
深度优先搜索 (可能超时)
-
动态构建并查集
-
-
queryBlcokSum
-
根据循环查找(可能超时)
-
直接返回并查集父节点个数
-
-
-
-
-
由于篇幅所限,仅以第一次作业为代表举例,第二次第三次作业也是同样的设计策略,目标就是在完美符合规格的同时尽可能缩小时间复杂度,寻找等价条件,翻译明白了然后找合适算法和容器。
三、基于JML规格测试方法及策略
测试在本单元的作业中尤为重要,课堂上,老师甚至提到在工业界中,编写测试样例是要优先于编写代码本身的。
在本单元作业中,我的测试策略大概也可以分为三个阶段。
-
基本功能测试
-
基本思想:根据每条指令的基本功能,进行最基本的功能测试。
-
主要以样例以及简单的自造样例为主,长度不太长,主要测试异常是否能正常响应、容器操作是否成功等基本问题。
-
-
极限性能测试
-
基本思想:针对每单元的高复杂度部分,进行有针对性的测试。
-
如作业二中的:限定10000条指令,添加条指令和等量指令,条ag指令,剩下的全为qgvs指令,根据相应时间复杂度列二次方程求解大概的极值,生成样例进行测试。
-
-
乱序随机测试
-
基本思想:通过评测机不同指令顺序的组合,发现静态分析所难以察觉的功能问题。
-
花费时间长,发现bug多,但需要评测机基础、靠谱的.jar包以及合理的指令生成策略,缺一不可。
-
-
正确性备注:与同学互换.jar包进行黑盒对拍测试。
四、浅谈容器选择和使用
Java8为我们提供了种类繁多的容器,我们可以在
List 进行随机存取和顺序存取很快,但在插入或删除时开销较大。(LinkedList)除外。常用的为ArrayList,LinkedList
Set 主要特征是根据元素的hashcode判断元素是否是同一个,一个Set中只能容纳一个元素,而且其中元素具有无序性。分别对应数学中集合的互异性和无序性。用来解决“存在与否”的问题效率较高。常用的为快速增删索引的HashSet以及自动排序的TreeSet。
Map 是一种可以通过key映射value的一种索引数据结构,常用的有HashMap、TreeMap和多线程中的ConcurrentHashMap等。
在C中我们还经常用一种叫最大堆的数据结构,在Java中,它的官方实现为PriorityQueue,可以用来实现特定的算法。
对于Person类、NetWork类中大多需要实现查找的person[] 和 accquaintance[] ,为了追求较高的索引速度,我会选择HashMap作为具体数据结构(O(1)的查找复杂度远低于遍历查找的O(n),而且遍历复杂度相同,删除也是O(1)复杂度)
对于特殊的Person类中的Message[]而言,考虑到JML规格中要求每次插入头部,且数据结构中原数据仍具有固定的相对顺序,我选择使用LinkedList,降低插入的开销。
对于并查集的父节点,我使用HashSet进行存储,这样,在queryBlockSum时便只用返回HashSet.size()了,极大降低了时间复杂度。
对于第三次作业中djistra算法的优化,我采用了经典的堆优化方式,使用PriorityQueue进行了算法的优化,提高了程序的性能。
总而言之,根据数据结构的特性和自己的需求合适地挑选容器的提,是我们熟悉了解这些容器本身和实现原理,在这之后,才能如鱼得水的使用它们。
五、本单元性能问题分析
-
性能问题概况
作业中比较明显的性能问题就是双循环问题,凡是看到有O(n^2)的复杂度,必然需要我们优化。
-
第一次作业中,正值五一假期,虽然我发现了不用并查集可能会tle,但是人在飞机已经来不及,回来后t了两个点,及时使用了并查集进行修改。
-
第二、三次作业,我经过多方学习与讨论,及时使用优化方法解决了JML中高复杂度的部分。
-
-
性能问题分析
-
所有的作业中,出现性能问题的部分都是简单粗暴的双循环导致的。
-
解决方案
-
前两次作业都可以采用记忆化的方式,避免重复计算,分别采用并查集和在线计算的方式,避免了每次查询都进行O(n^2)复杂度的计算。
-
第三次作业则采用优化版的迪杰斯特拉算法,将程序复杂度由O(n^2)降至O(mlogm)。
-
-
六、架构设计
由于第一二次作业的架构包含在第三次中,而且第三次作业有关图的架构最为完整,此处以第三次作业的架构为例分析架构。
-
图模型构建与维护
-
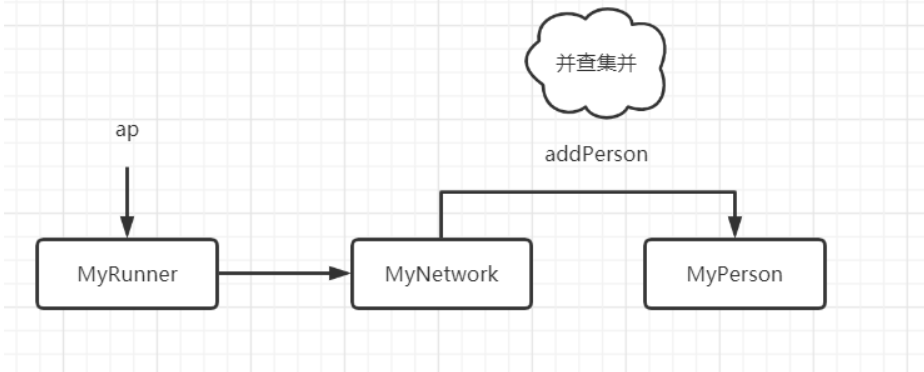
如果把整个关系网络看作一个图,那么每个节点——Person中的accquaintance[]便是该节点的邻接表,我们可以通过addPerson addRelation、deletePerson等方法进行图的维护和构建。
-
-
并查集
-
-
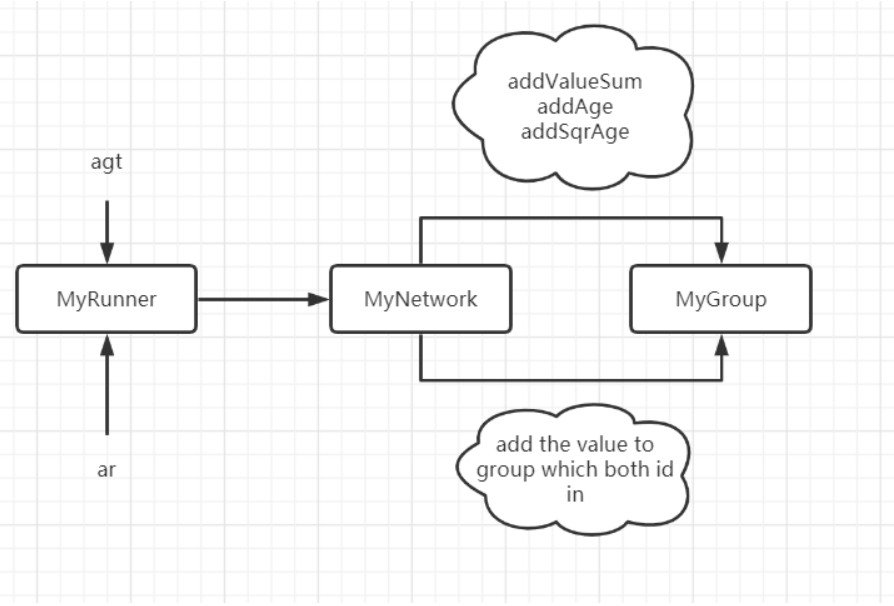
在线计算
-
-
djistra
-
是市面上常见的djistra啦
-
七、心得体会
第三单元的OO作业较前几次作业来说,难度有所下降,但是要求我们掌握更多工程化的方法,使我们编写的代码更加规范化。此外,本单元中还出现了选择合适数据结构和算法的问题,也启示我们算法和数据结构是我们写码之路中不可丢失的法宝。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号