使用Java实现爬虫获取图片
通过Java来下载图片,废话不多说步骤如下:
1、导入jsoup依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.2</version>
</dependency>
2、进行编写代码
2.1、我们先定义一个要爬取的一个地址。这里就随便选择一个网址。
//网址可以随便按照自己需求来搞。CSDN审核好严格,这里网址不再写。netbian前面自己加上3个w后面加上.com
String url = "";
2.2、因为选择了这个网页那么接下来我们就要进行解析,所以说调用jsoup中的parse这个方法进行解析网页
//这里就是得到整个文档对象,和JS里面内容差不多
Document document = Jsoup.parse(new URL(url), 10000);
2.3、接下来就是获取我们想要获取的内容了。
我们通过检查网页元素发现:

上述图片div标签里面id=main这个下包含了多个<li>标签,而<li>标签下面就是包含很多种图片,所以说<li>标签就是我们想要的。那么我们就一步一步来,先通过id来获取div标签下的所有内容
Element content = document.getElementById("main");
然后通过getElementsByTag()方法获得所有的<li>标签。
Elements liElements = content.getElementsByTag("li");
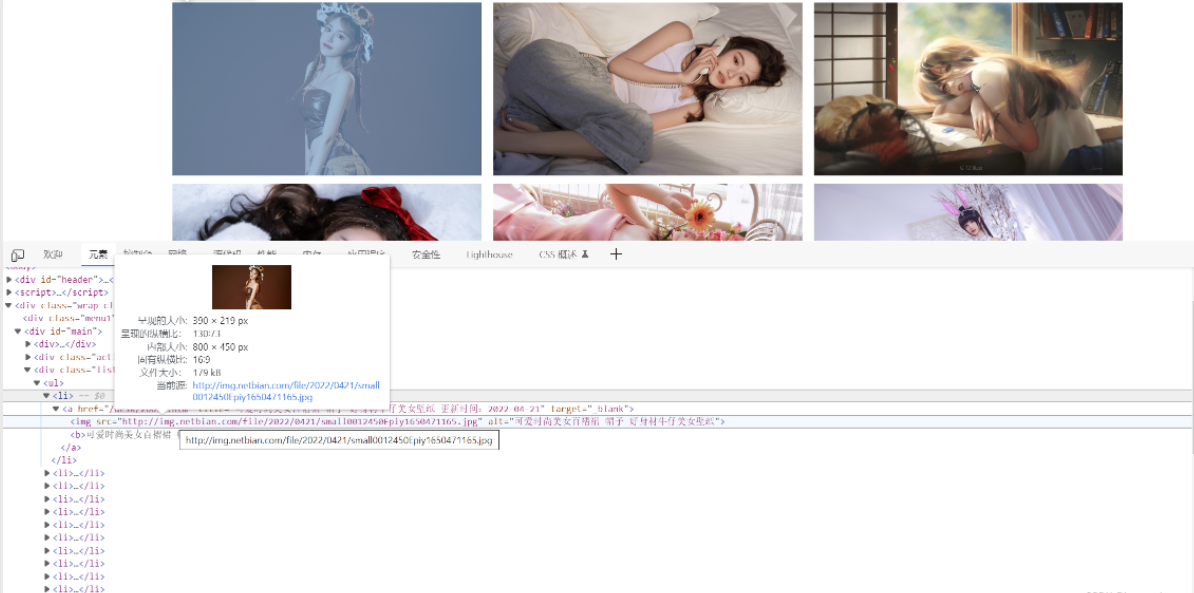
通过观察上图我们可以发现,打开<a>标签我们能看到<a>标签下面有img标签,而这个img标签里面src属性正是我们想要的图片地址。我们只需要遍历整个liElements,然后再逐一获取即可。那么接下来操作如下:
for (Element liElement : liElements) {
//通过img标签获得img标签里面的内容
Elements img = liElement.getElementsByTag("img");
//获得img标签里面的src这个属性。也就是获取到了这个图片的地址
String src = img.attr("src");
//没有什么太大意思。就是获取alt这个属性,当个名字而已
String pictureName = img.attr("alt");
//因为我们要保存到本地,所以这里是获取输入流
URL target = new URL(src);
InputStream is = target.openConnection().getInputStream();
//获取输出流,定义我们保存图片的路径
FileOutputStream fos = new FileOutputStream("E:\\imagesWork\\" + System.currentTimeMillis() + ".jpg");
//Java基础部分IO复制的操作
int len = 0;
byte[] bytes = new byte[1024];
while ((len = is.read(bytes)) != -1) {
fos.write(bytes, 0, len);
}
System.out.println(pictureName + "--->下载完成");
fos.close();
is.close();
}
2.4、最后结果如下:
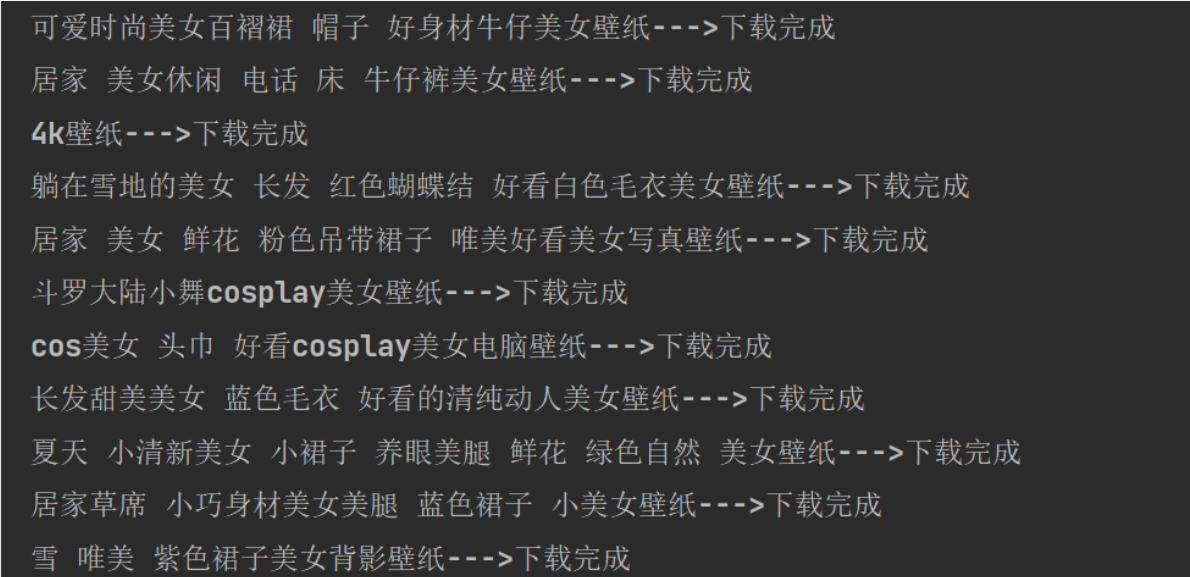
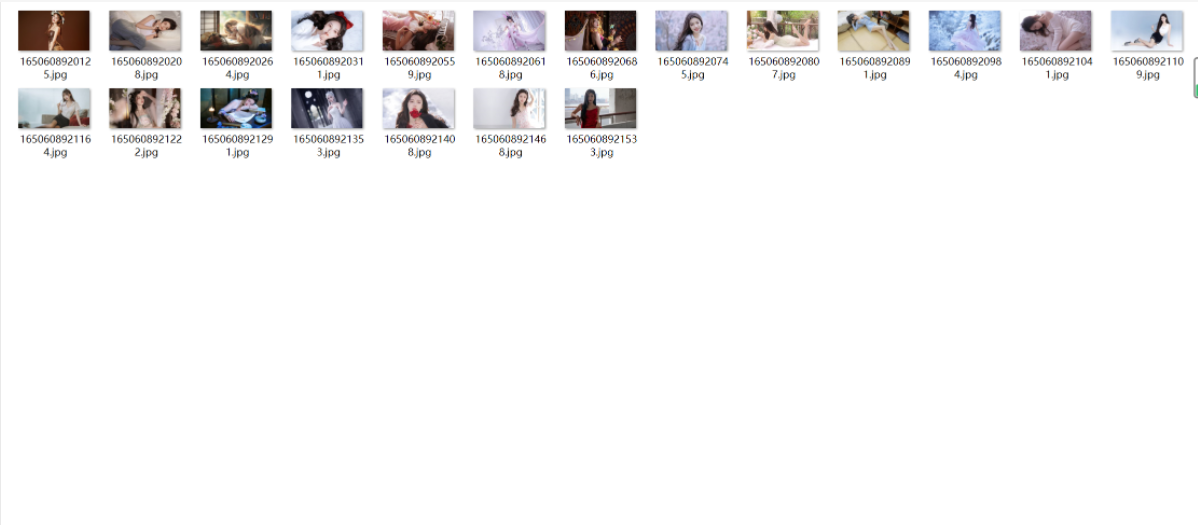
最后附上整个Java代码
@Test
public void downloadWoman() throws Exception {
String url = "http://www.netbian.com/mei/";
Document document = Jsoup.parse(new URL(url), 10000);
Element content = document.getElementById("main");
Elements liElements = content.getElementsByTag("li");
for (Element liElement : liElements) {
Elements img = liElement.getElementsByTag("img");
//System.out.println(img);
String src = img.attr("src");
String pictureName = img.attr("alt");
URL target = new URL(src);
InputStream is = target.openConnection().getInputStream();
FileOutputStream fos = new FileOutputStream("E:\\imagesWork\\" + System.currentTimeMillis() + ".jpg");
int len = 0;
byte[] bytes = new byte[1024];
while ((len = is.read(bytes)) != -1) {
fos.write(bytes, 0, len);
}
System.out.println(pictureName + "--->下载完成");
fos.close();
is.close();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号