数据采集第四次作业
任务一:基于Selenium和MySQL的股票数据爬取
本次作业的主要目标是使用Selenium框架结合MySQL数据库,爬取东方财富网中“沪深A股”、“上证A股”、“深证A股”三个板块的股票数据信息,并将其存储到本地数据库中。以下是详细的代码实现和心得体会。
一、代码实现与讲解
1. 导入必要的库
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import mysql.connector
import time
selenium:用于模拟浏览器操作,爬取动态网页数据。mysql.connector:用于连接和操作MySQL数据库。time:用于控制程序的等待时间。
2. 设置MySQL连接
def connect_mysql():
conn = mysql.connector.connect(
host="localhost",
user="root",
password="llmmll",
database="stock_data"
)
return conn
- 该函数用于建立与MySQL数据库的连接,返回一个连接对象。
3. 创建数据库表
def create_table():
conn = connect_mysql()
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS stock_info (
id INT AUTO_INCREMENT PRIMARY KEY,
stock_code VARCHAR(20),
stock_name VARCHAR(50),
latest_price FLOAT,
change_percent FLOAT,
change_amount FLOAT,
volume FLOAT,
turnover_amount FLOAT,
amplitude FLOAT,
highest_price FLOAT,
lowest_price FLOAT,
opening_price FLOAT,
previous_close FLOAT
)
''')
conn.commit()
cursor.close()
conn.close()
- 该函数用于在数据库中创建名为
stock_info的表,用于存储股票数据。 - 使用
AUTO_INCREMENT自动生成主键id。
4. 插入数据到MySQL数据库
def insert_data(stock_data):
conn = connect_mysql()
cursor = conn.cursor()
cursor.execute('''
INSERT INTO stock_info (stock_code, stock_name, latest_price, change_percent, change_amount,
volume, turnover_amount, amplitude, highest_price, lowest_price,
opening_price, previous_close)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
''', stock_data)
conn.commit()
cursor.close()
conn.close()
- 将爬取到的股票数据以元组的形式传入,插入到数据库中对应的表中。
5. 爬取页面数据的函数
def crawl(driver):
# 等待页面加载并获取数据
WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.XPATH, '/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody'))
)
# 获取股票表格行
stock_rows = driver.find_elements(By.XPATH, '/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr')
for i in range(len(stock_rows)):
try:
# 逐一获取每一行的数据
stock_code = stock_rows[i].find_element(By.XPATH, './td[2]/a').text
stock_name = stock_rows[i].find_element(By.XPATH, './td[3]/a').text
latest_price = float(stock_rows[i].find_element(By.XPATH, './td[5]/span').text)
change_percent = float(stock_rows[i].find_element(By.XPATH, './td[6]/span').text.strip('%'))
change_amount = float(stock_rows[i].find_element(By.XPATH, './td[7]/span').text)
volume = float(stock_rows[i].find_element(By.XPATH, './td[8]').text.replace('万', 'e4').replace('亿', 'e8'))
turnover_amount = float(
stock_rows[i].find_element(By.XPATH, './td[9]').text.replace('万', 'e4').replace('亿', 'e8'))
amplitude = float(stock_rows[i].find_element(By.XPATH, './td[10]').text.strip('%'))
highest_price = float(stock_rows[i].find_element(By.XPATH, './td[11]/span').text)
lowest_price = float(stock_rows[i].find_element(By.XPATH, './td[12]/span').text)
opening_price = float(stock_rows[i].find_element(By.XPATH, './td[13]/span').text)
previous_close = float(stock_rows[i].find_element(By.XPATH, './td[14]').text)
# 构造数据元组
stock_data = (stock_code, stock_name, latest_price, change_percent, change_amount, volume,
turnover_amount, amplitude, highest_price, lowest_price, opening_price, previous_close)
# 将数据插入数据库
insert_data(stock_data)
except Exception as e:
print(f"Error processing row: {e}")
continue
- 使用
WebDriverWait等待页面元素加载完成。 - 通过XPath定位股票数据所在的表格行
tr元素。 - 逐一提取每个股票的数据字段,并进行必要的数据转换和处理。
- 将处理后的数据插入到数据库中。
- 使用
try-except块捕获并处理可能出现的异常,保证程序的健壮性。
6. 使用Selenium获取网页数据
def fetch_stock_data():
options = webdriver.ChromeOptions()
# options.add_argument('--headless') # 可选:隐藏浏览器界面
driver = webdriver.Chrome(options=options)
driver.get("http://quote.eastmoney.com/center/gridlist.html#hs_a_board")
# 爬取“沪深A股”数据
crawl(driver)
# 爬取“上证A股”数据
try:
sh_a_board_link = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '/html/body/div[1]/div[2]/div[2]/div[3]/ul/li[2]/a'))
)
sh_a_board_link.click()
print("成功点击“上证A股”板块")
time.sleep(2)
crawl(driver)
except Exception as e:
print(f"点击“上证A股”板块失败: {e}")
driver.quit()
# 爬取“深证A股”数据
try:
sz_a_board_link = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '/html/body/div[1]/div[2]/div[2]/div[3]/ul/li[3]/a'))
)
sz_a_board_link.click()
print("成功点击“深证A股”板块")
time.sleep(2)
crawl(driver)
except Exception as e:
print(f"点击“深证A股”板块失败: {e}")
driver.quit()
driver.quit()
- 初始化Chrome浏览器驱动,打开目标网页。
- 首先爬取默认打开的“沪深A股”板块数据。
- 通过点击页面上的链接,切换到“上证A股”和“深证A股”板块,分别爬取数据。
- 使用显式等待
WebDriverWait确保元素可点击,避免元素未加载完成就进行操作导致的错误。 - 在每次点击后,
time.sleep(2)固定等待2秒,确保页面加载完成。
7. 主程序入口
if __name__ == '__main__':
create_table() # 创建数据库表
fetch_stock_data() # 开始爬取数据
- 在主程序中,首先调用
create_table()函数创建数据库表。 - 然后调用
fetch_stock_data()函数开始整个数据爬取流程。
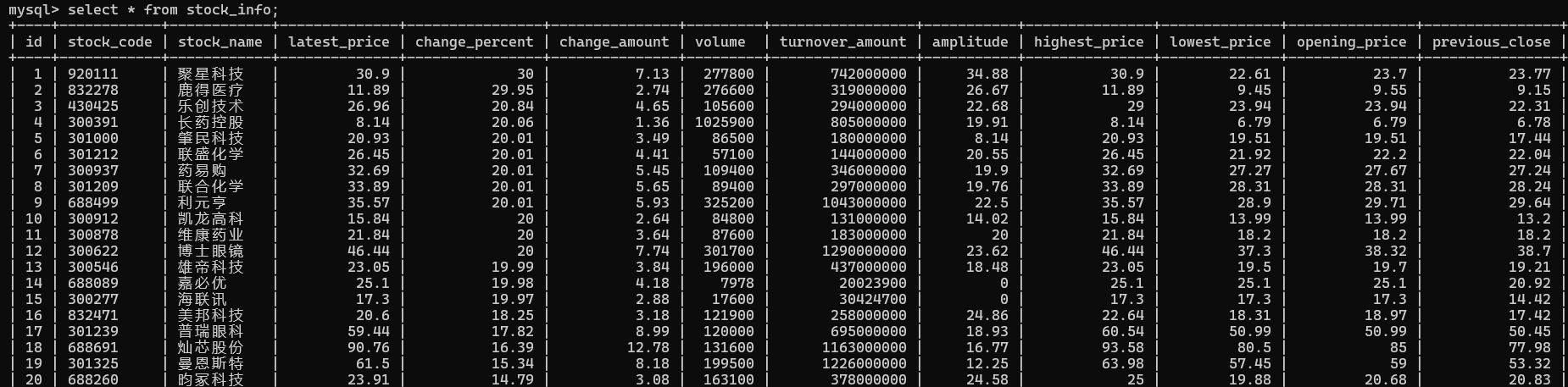
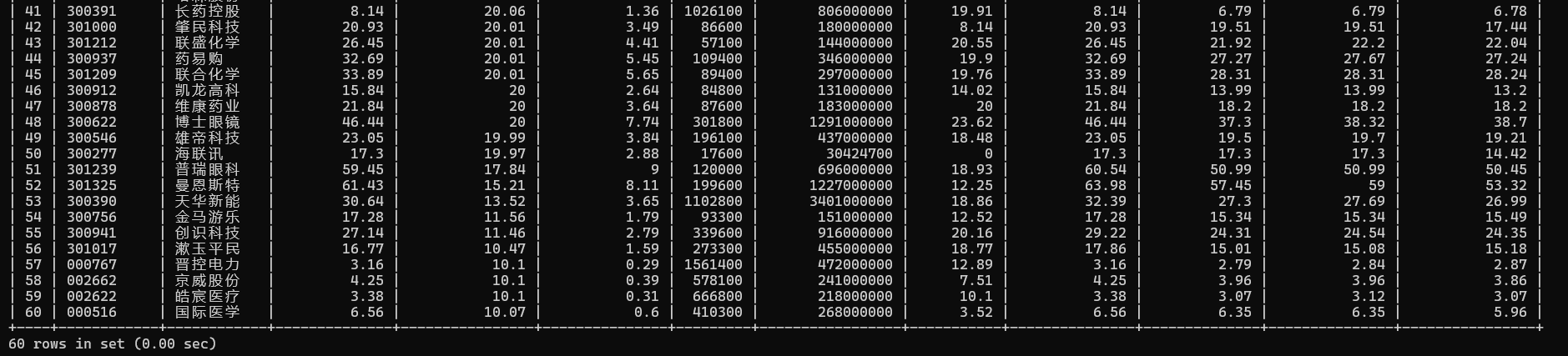
8. 程序运行结果
在数据库中查看成功爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息:

9.Gitee文件夹链接
https://gitee.com/lan-minlong/crawl_project_2024/tree/master/作业4
二、作业心得
1、问题与解决方案
在实际的爬取过程中,我遇到了一些问题,并通过查找资料和调试代码进行了相应的解决。
①. 页面元素定位困难
问题描述:由于网页结构复杂,某些元素的XPath路径较长且不稳定,导致元素定位失败。
解决方案:使用更通用和稳健的定位方法,例如通过元素的id、class属性,或者使用CSS Selector。同时,避免使用绝对路径,尽量使用相对路径。
# 例如,使用相对路径定位股票表格
stock_rows = driver.find_elements(By.CSS_SELECTOR, 'table tbody tr')
②. 数据单位转换错误
问题描述:在处理成交量和成交额时,原始数据包含“万”、“亿”等单位,直接转换为浮点数会报错。
解决方案:在提取数据时,先将单位替换为科学计数法表示的乘数,然后再进行类型转换。
volume_text = stock_rows[i].find_element(By.XPATH, './td[8]').text
volume = float(volume_text.replace('万', 'e4').replace('亿', 'e8'))
2、 心得与收获
-
Selenium动态网页爬取:
在这次作业中,Selenium帮助我成功应对了动态网页的数据爬取问题。通过WebDriverWait和expected_conditions,我能够确保在页面元素完全加载后再进行数据提取,避免了常见的抓取不完全的情况。动态网页的处理让爬虫更加稳定,也减少了错误的发生,特别是在爬取多个板块数据时,避免了等待时间过长导致的程序崩溃。 -
精确元素定位:
页面元素的位置可能会发生变化,因此我使用XPath进行精准定位,确保每个数据字段的提取都准确无误。在实际爬取过程中,每次获取股票数据时,我都重新查找表格元素,避免了Selenium因页面变化导致的stale element错误。这种方式提高了程序的稳定性和抓取的准确性。 -
MySQL数据存储:
我将爬取的数据成功存储到MySQL数据库中,通过mysql.connector模块与MySQL进行交互。为了确保数据存储的规范性,我设计了合理的数据库表结构,每个字段根据数据的性质进行了适当的类型设置。使用批量插入操作提高了存储效率,同时对可能发生的异常进行捕捉,确保数据插入过程中不会影响程序的执行。 -
数据单位转换:
股票数据中的成交量和成交额字段常常带有“万”和“亿”等单位,为了确保数据能够正确存储,我在抓取过程中使用了字符串替换方法,将这些单位转换为科学计数法。例如,将“万”转换为e4,这样不仅使数据存储一致,还避免了因单位不统一导致的计算错误。
任务二:爬取中国MOOC网课程资源并存储到MySQL
代码实现与讲解
1. MySQL数据库操作
在本作业中,我们首先需要设置MySQL数据库,用于存储抓取到的课程数据。使用Python的mysql.connector模块连接数据库,创建一个名为mooc_courses的数据库,并在其中创建一个mooc表,用于存储课程信息。
# MySQL数据库连接
def get_db_connection():
return mysql.connector.connect(
host="localhost",
user="root",
password="llmmll",
database="mooc_courses"
)
# 创建MOOC表格
def create_table(cursor, conn):
cursor.execute("""
CREATE TABLE IF NOT EXISTS mooc (
Id VARCHAR(20),
cCourse VARCHAR(100),
cCollege VARCHAR(100),
cTeacher VARCHAR(100),
cTeam VARCHAR(200),
cCount INT,
cProcess VARCHAR(100),
cBrief TEXT
)
""")
conn.commit()
2. Selenium模拟登录
在获取课程信息之前,首先需要模拟登录操作,使用Selenium打开中国MOOC网并输入用户名和密码进行登录。通过webdriver.Chrome启动浏览器,利用XPath定位元素,输入账号密码并点击登录按钮。
# 获取浏览器并登录
def get_browser_and_login(user_name, password):
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.maximize_window()
driver.get("https://www.icourse163.org/")
# 同意隐私政策
driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div').click()
time.sleep(3)
# 切换到登录 iframe
iframe = driver.find_element(By.XPATH, '/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(iframe)
# 输入账号密码并登录
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input').send_keys(user_name)
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]').send_keys(password)
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a').click()
time.sleep(5)
driver.switch_to.default_content()
time.sleep(3)
return driver
3. 获取课程信息
模拟登录后,接下来是获取课程数据。课程页面由多个课程信息块组成,每个信息块包含课程名称、学校、主讲教师等数据。使用Selenium通过XPath获取每个课程的详细信息,如课程号、课程名称、主讲教师等,并点击每个课程进入详情页以提取更多信息(如团队成员、课程人数、课程进度等)。
# 获取单个课程的详细信息
def get_course_info(driver, course_index):
course_info = driver.find_element(By.XPATH, f'//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div[{course_index + 1}]/div/div[3]/div[1]').text.split("\n")
driver.find_element(By.XPATH, f'//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div[{course_index + 1}]').click()
driver.switch_to.window(driver.window_handles[-1])
# 获取团队成员
team = driver.find_elements(By.XPATH, '//*[@class="f-fc3"]')
course_info.append(','.join([t.text for t in team]))
# 获取课程人数
try:
count = driver.find_element(By.XPATH, '//*[@class="count"]').text
except:
count = "已有0人参加"
course_info.append(count[2:-3]) # 处理人数字段
# 获取课程时间
try:
date = driver.find_element(By.XPATH, '//*[@id="course-enroll-info"]/div/div[1]/div[2]/div/span[2]').text
except:
date = "无"
course_info.append(date)
# 获取课程简介
brief = driver.find_element(By.XPATH, '//*[@id="j-rectxt2"]').text
course_info.append(brief)
return course_info
4. 数据存储与分页爬取
在获取了每个课程的信息后,我们将其插入到MySQL数据库中。我们使用一个循环模拟翻页,确保爬取多个页面的数据。
# 插入数据到数据库
def insert_course_data(cursor, conn, sql, course_info, n):
values = (n, *course_info)
cursor.execute(sql, values)
conn.commit()
# 循环抓取课程数据
def scrape_courses(driver, cursor, sql):
n = 1
for _ in range(2): # 爬取2页数据
for i in range(5): # 每页5个课程
try:
course_info = get_course_info(driver, i)
insert_course_data(cursor, sql, course_info, n)
n += 1
driver.close()
driver.switch_to.window(driver.window_handles[-1]) # 切换回主标签页
except Exception as e:
print(f"错误:{e}")
driver.close()
driver.switch_to.window(driver.window_handles[-1])
# 点击下一页按钮
driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]').click()
time.sleep(2)
5. 主程序
def main():
conn = get_db_connection()
cursor = conn.cursor()
create_table(cursor, conn)
user_name = "18750362889"
password = "Mooc123456"
driver = get_browser_and_login(user_name, password)
sql = """
INSERT INTO mooc (Id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
"""
scrape_courses(driver, cursor, sql)
cursor.close()
conn.close()
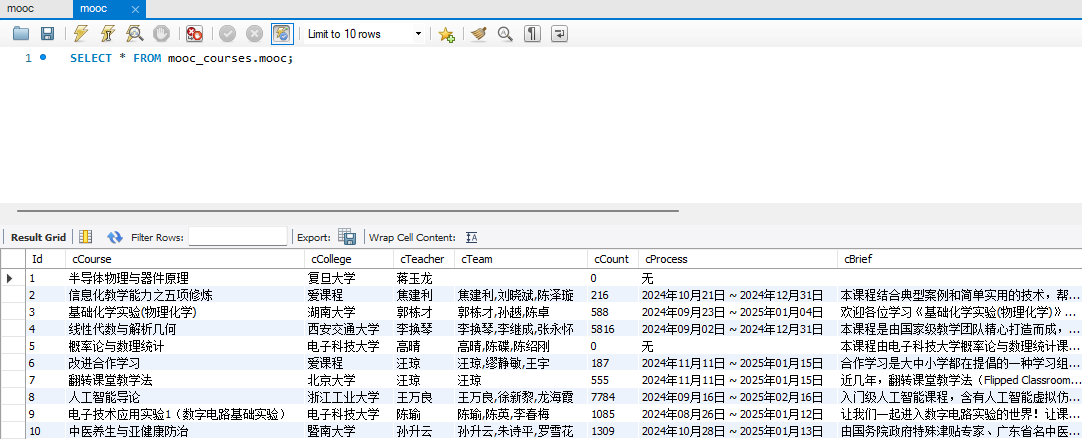
6. 程序运行结果
数据库显示成功爬取中国mooc网课程资源信息
7. Gitee文件夹链接
https://gitee.com/lan-minlong/crawl_project_2024/tree/master/作业4
心得体会
遇到的问题与解决方案
-
隐私政策点击问题:
在模拟登录过程中,第一次访问MOOC网站时,页面上会弹出隐私政策通知,必须点击同意才能继续操作。由于这是一个动态生成的元素,因此我需要确保在程序中能够定位并正确点击同意按钮。解决方案是通过driver.find_element(By.XPATH)来定位隐私政策同意按钮,并使用time.sleep()等待页面稳定加载后再进行点击。# 同意隐私政策 driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div').click() time.sleep(3) -
登录时的iframe切换问题:
使用Selenium进行模拟登录时,页面存在一个嵌套的iframe,导致元素定位变得复杂。为了解决这个问题,我使用了driver.switch_to.frame()切换到相应的iframe,然后进行账号和密码的输入,并点击登录按钮。登录后,记得切换回默认页面,以确保后续操作的正确执行。# 切换到登录 iframe iframe = driver.find_element(By.XPATH, '/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe') driver.switch_to.frame(iframe) # 输入账号密码并登录 driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input').send_keys(user_name) driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]').send_keys(password) driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a').click() -
动态加载元素定位困难:
在抓取课程信息时,网页中的某些元素是通过Ajax异步加载的,这导致了在某些情况下Selenium无法及时找到这些元素。为了解决这个问题,我使用了time.sleep()来等待页面加载完成,或者使用显式等待(WebDriverWait)确保元素加载完成后再进行操作。# 显式等待,确保元素加载完成 WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, 'xpath_to_element'))) -
翻页时的元素定位问题:
在爬取多页课程时,点击“下一页”按钮是一个常见操作,但有时页面元素加载不完全或XPath路径发生了变化,导致无法找到“下一页”按钮。为了避免这种问题,我在每次点击翻页按钮之前,增加了time.sleep()确保页面加载完成,并且在异常处理中加入了元素定位的检查,避免出现点击失败的情况。# 点击下一页按钮 driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]').click() time.sleep(2) -
浏览器窗口切换问题:
在抓取课程信息时,每次点击课程链接会打开一个新的浏览器标签页。抓取完成后,程序需要关闭当前标签页并切换回主标签页。由于Selenium无法直接定位关闭的标签页,所以我通过driver.window_handles获取所有标签页句柄,并在关闭当前标签页后,切换到最后一个打开的标签页,确保程序继续执行。# 关闭当前标签页并切换回主标签页 driver.close() driver.switch_to.window(driver.window_handles[-1])
心得与收获
-
Selenium的实用性:
通过本次作业,我深刻理解了Selenium在自动化测试和爬虫中的重要性,特别是在处理动态网页时,它的显式等待和元素定位功能大大提高了程序的稳定性和准确性。 -
数据库操作的熟练度:
本作业让我更熟练地掌握了Python与MySQL的连接与操作,学会了如何使用Python与数据库进行交互,并通过SQL语句批量插入数据。 -
网页元素的抓取技巧:
在抓取网页时,遇到过不少问题,如元素定位困难、页面跳转等。这些问题让我更深入地理解了网页结构和爬虫技术,也让我学会了如何灵活应对各种问题。
任务三:实时分析开发实战
环境的搭建
一、开通MapReduce服务
申请弹性公网IP
MapReduce服务开启成功

实时分析开发实战
实验主要是通过Flink来完成实时流数据的处理,Flink接收Kafka中的数据,处理完成之后写入MySQL中
一、Python脚本生成测试数据
脚本生成测试数据成功
通过以下步骤,利用Python脚本能够生成测试数据
步骤1 登录MRS的master节点服务器
步骤2 编写Python脚本
步骤3 创建存放测试数据的目录
步骤4 执行脚本测试
生成的数据如下:

二、配置Kafka
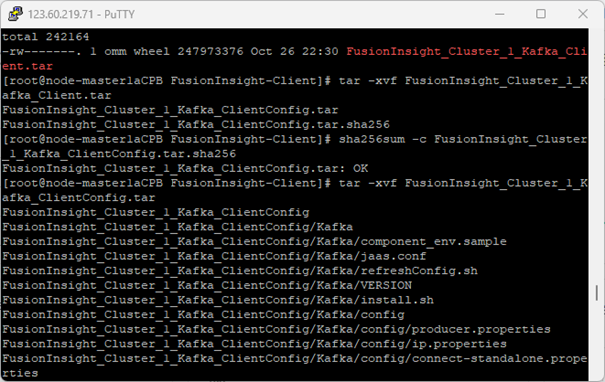
1.检验下载的Kafka客户端文件包
进入MRS Manager集群管理后下载客户端。随后检验下载的客户端文件包:
2.安装Kafka运行环境
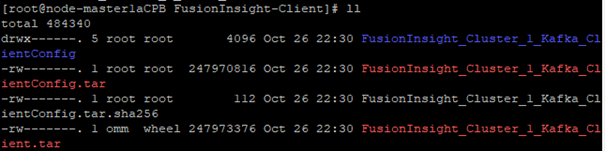
解压“MRS_Flume_ClientConfig.tar”文件。并查看解压后文件:
3.客户端运行环境安装成功
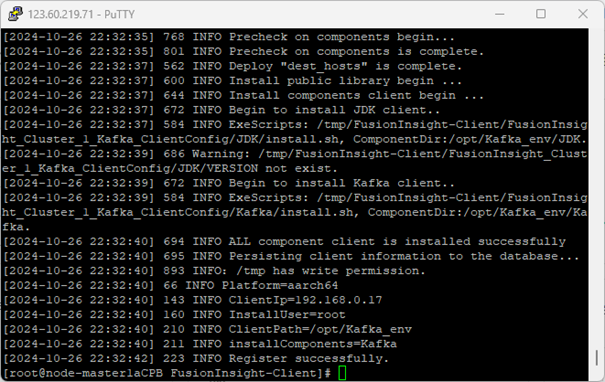
安装客户端运行环境到目录“/opt/Kafka_env”(安装时自动生成目录),有以下输出,表明安装成功:
4.安装Kafka客户端
安装Kafka到目录“/opt/KafkaClient”(安装时自动生成目录,-d:表示Kafka客户端安装路径)。

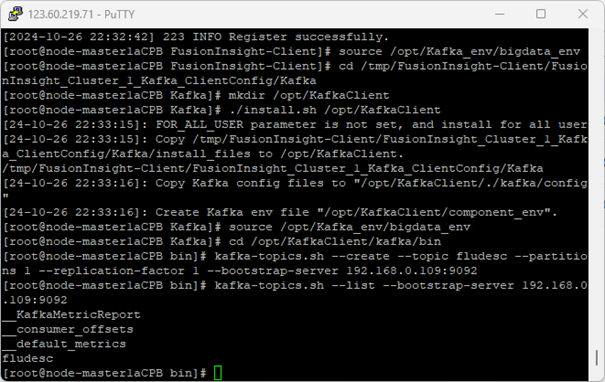
5.在kafka中创建topic并查看信息
执行命令创建topic,并查看信息:
三、安装Flume客户端
1.安装Flume运行环境
进入MRS Manager集群管理,下载Flume客户端。
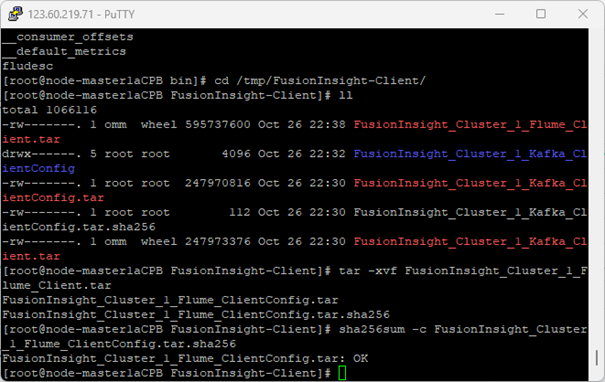
2.安装成功
解压“MRS_Flume_ClientConfig.tar”文件,安装客户端运行环境到目录“/opt/Flume_env”(安装时自动生成目录)。有以下输出,表明安装成功:
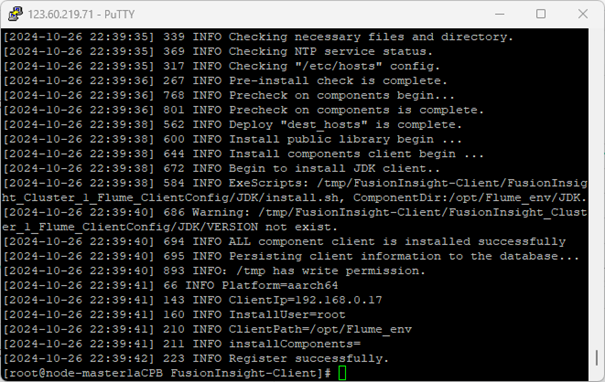
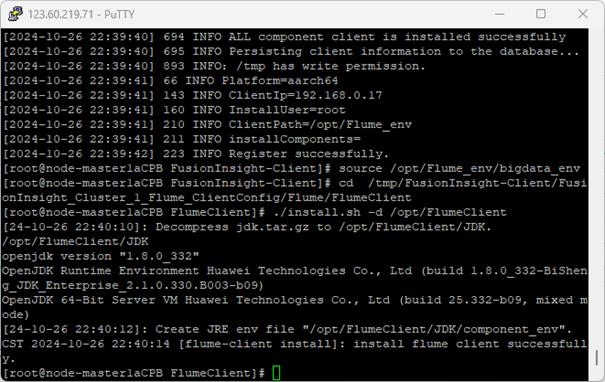
3.安装Flume客户端
安装Flume到目录“/opt/FlumeClient”(安装时自动生成目录,-d:表示Flume客户端安装路径)。
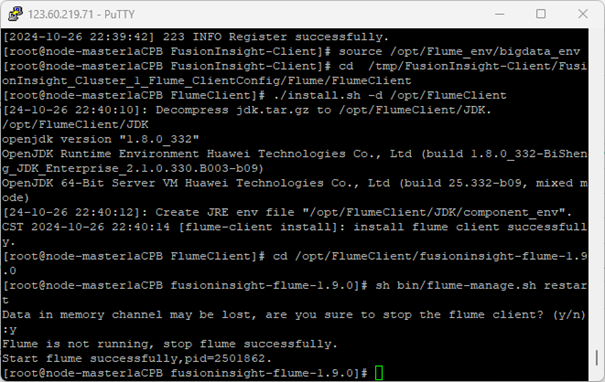
4.重启Flume服务
执行以下命令重启Flume的服务。
四、配置Flume采集数据
1.配置Flume采集数据
在conf目录下编辑文件properties.properties。创建消费者消费kafka中的数据:
心得体会
1. 问题及解决方案
Kafka连接失败问题:
在运行Flink作业读取Kafka中的数据时,出现了“无法连接到Kafka Broker”的错误。经过分析,问题出在Kafka的Broker未开放9092端口,导致网络不通。解决方案如下:
-
登录Kafka所在的服务器,检查Kafka服务状态,确保服务已启动:
systemctl status kafka -
修改Kafka所在服务器的安全组规则,在入方向规则中放通9092端口(TCP协议),确保DLI能够访问Kafka Broker。
-
使用命令
netstat -tulnp | grep 9092验证端口是否监听。
2. 主要收获与心得
2.1 系统掌握大数据实时处理的核心流程
实验涵盖了从数据采集(Flume + Kafka)、实时处理(Flink)、到存储与展示(MySQL + DLV)的完整流程。这一实践让我熟悉了各组件之间的数据流通与协同工作的重要性,也让我更加深入地理解了大数据实时处理架构的构建与实施。
2.2 强化多组件集成与跨网络协作能力
实验过程中涉及了多个云服务的配置与调试(如MRS、DLI、RDS、DLV),并需要确保跨网络资源的连通性。通过这些实践,我掌握了在复杂云环境中如何处理不同组件间的通信问题,提升了系统集成与跨网络协作的能力。
2.3 提升问题分析与解决能力
在实验过程中,我遇到了Kafka网络不通、数据库连接错误及数据实时展示失败等问题。这些问题促使我深入分析配置细节,并结合日志进行定位,培养了快速排查与解决实际问题的能力。这一过程使我对系统调试与优化有了更深刻的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号