数据采集第一次作业
作业①:爬取大学排名信息
代码与展示
import urllib.request
from bs4 import BeautifulSoup
from prettytable import PrettyTable # 导入prettytable库
# 设置请求头,模拟浏览器访问,避免被服务器拒绝
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
# 创建请求对象,包含URL和请求头
req = urllib.request.Request(url=url, headers=headers)
try:
# 发送请求并获取响应
response = urllib.request.urlopen(req)
# 读取响应内容并以UTF-8编码解码
html = response.read().decode('utf-8')
# 使用BeautifulSoup解析HTML文档
soup = BeautifulSoup(html, 'lxml')
# 查找包含排名的表格,class为'rk-table'
table = soup.find('table', class_='rk-table')
if table is None:
print("未能找到排名表格,请检查网页结构。")
else:
# 获取表格主体中的所有行
rows = table.find('tbody').find_all('tr')
# 初始化prettytable对象并设置表头
pt = PrettyTable()
pt.field_names = ['排名', '学校名称', '省市', '学校类型', '总分']
# 遍历每一行,提取数据并添加到表格
for row in rows:
cols = row.find_all('td')
rank = cols[0].text.strip() # 排名
# 提取学校名称部分,仅保留中文名称
name_parts = cols[1].text.strip().split('\n')
name = name_parts[0] # 只保留第一个部分,即中文学校名称
province = cols[2].text.strip() # 省市
category = cols[3].text.strip() # 学校类型
score = cols[4].text.strip() # 总分
# 添加提取的数据到表格
pt.add_row([rank, name, province, category, score])
# 打印表格
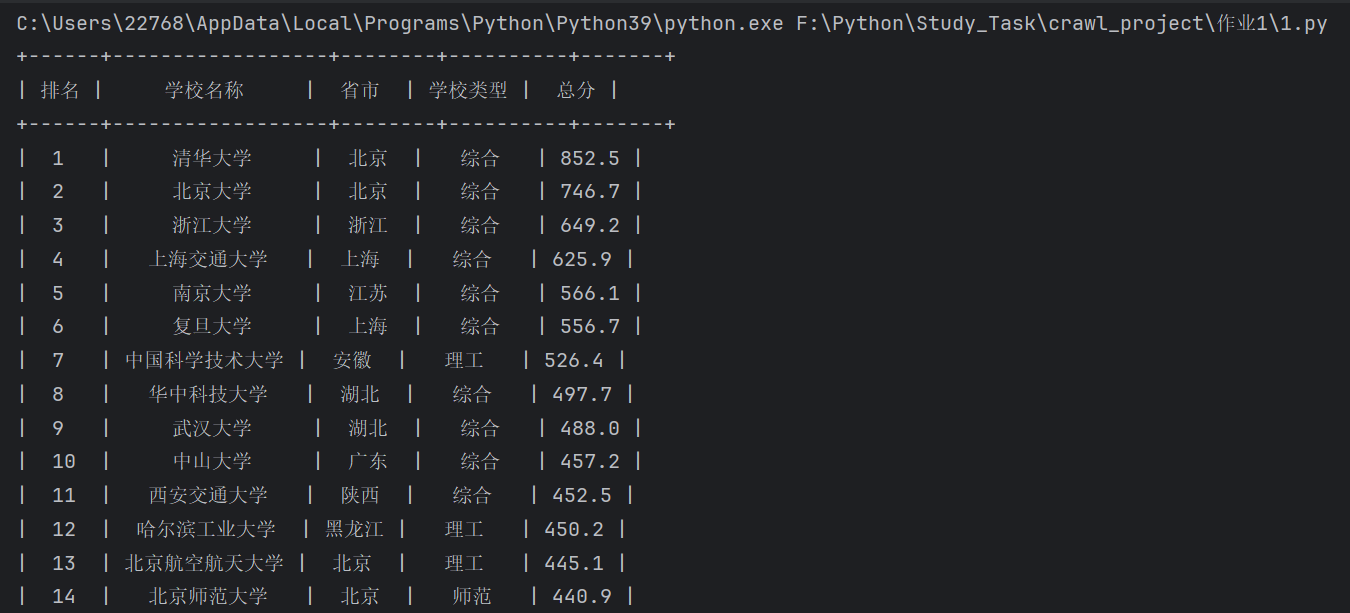
print(pt)
except Exception as e:
print(f"请求网页失败:{e}")
运行结果:
作业心得
通过这次作业,我学习了如何使用 urllib.request 和 BeautifulSoup 库来爬取网页数据。主要收获有:
- 请求网页数据: 了解了如何设置请求头来模拟浏览器访问,避免被反爬机制拦截。
- 解析网页内容: 掌握了使用
BeautifulSoup解析 HTML 文档,定位并提取所需的信息。 - 数据展示: 学会了使用
prettytable库将数据以表格形式美观地输出,提升了数据的可读性。
作业②:商品比价定向爬虫
代码与展示
import requests
import re
def crawl_jd_bookbags(cookies):
"""
爬取京东商城中搜索关键词“书包”的商品名称和价格。
参数:
cookies (dict): 模拟浏览器的Cookies。
"""
url = 'https://search.jd.com/Search?keyword=书包&enc=utf-8'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
# 使用提供的cookies
session = requests.Session()
session.cookies.update(cookies)
response = session.get(url, headers=headers)
html_content = response.text
name_pattern = re.compile(r'<div class="p-name p-name-type-2">.*?<em>(.*?)</em>.*?</div>', re.S)
price_pattern = re.compile(r'<i data-price=".*?">(.*?)</i>', re.S)
product_names = name_pattern.findall(html_content)
product_prices = price_pattern.findall(html_content)
items = list(zip(product_names, product_prices))[:60]
for idx, (name, price) in enumerate(items, start=1):
name_clean = re.sub('<.*?>', '', name).strip()
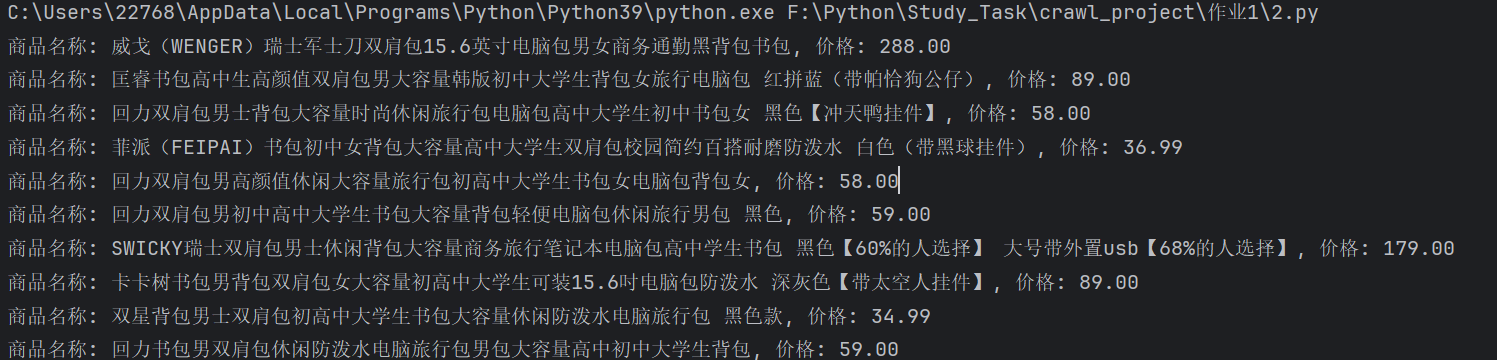
print(f"{idx}\t价格: {price}\t商品名称: {name_clean}")
if __name__ == "__main__":
# 在这里填入从浏览器复制的cookie
cookies = {
'cookie_name1': 'your_cookie_value1',
'cookie_name2': 'your_cookie_value2',
# ...
}
crawl_jd_bookbags(cookies)
注意事项:
- Cookies 设置: 需要将自己的浏览器 Cookies 复制到代码中,才能成功获取京东的商品数据。
- 运行结果:
作业心得
这次作业让我深入了解了电商网站的爬虫技巧,主要体会有:
- 模拟登录: 学习了如何使用会话和 Cookies 模拟登录状态,绕过网站的反爬机制。
- 正则表达式提取: 熟练使用正则表达式从复杂的 HTML 中提取所需的商品名称和价格信息。
- 数据处理: 注意到提取的数据可能包含 HTML 标签,需要进一步清洗以获得纯净的文本内容。
作业③:下载网页中的JPEG和JPG图片
代码与展示
import re
import requests
import os
import urllib.parse
def download_jpeg_images(target_url, request_headers):
"""
从指定网页下载所有JPEG和JPG格式的图片,并保存到本地文件夹。
参数:
target_url (str): 要爬取的网页URL。
request_headers (dict): HTTP请求头信息。
"""
# 发送HTTP GET请求获取网页内容
html_response = requests.get(url=target_url, headers=request_headers)
html_content = html_response.text
# 使用正则表达式查找所有以.jpg或.jpeg结尾的图片链接
image_urls = re.findall(r'<img[^>]+src=["\'](.*?\.(?:jpg|jpeg))["\']', html_content, re.IGNORECASE)
# 创建保存图片的目录,如果不存在则创建
save_folder = 'images'
if not os.path.exists(save_folder):
os.makedirs(save_folder)
# 遍历所有图片链接并下载
for img_url in image_urls:
# 处理相对路径的图片链接
full_img_url = urllib.parse.urljoin(target_url, img_url)
# 获取图片内容
img_response = requests.get(full_img_url, headers=request_headers)
# 从图片URL中提取文件名
img_filename = os.path.basename(img_url)
# 定义图片保存路径
img_save_path = os.path.join(save_folder, img_filename)
# 将图片内容写入文件
with open(img_save_path, 'wb') as img_file:
img_file.write(img_response.content)
print(f'已下载图片:{img_filename}')
if __name__ == "__main__":
# 指定要爬取的网页URL
url_to_scrape = 'https://news.fzu.edu.cn/yxfd.htm'
# 定义HTTP请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
# 调用函数下载图片
download_jpeg_images(url_to_scrape, headers)
运行结果:

作业心得
通过这次实践,我学会了从网页中批量下载图片的方法,主要收获有:
- 正则表达式应用: 熟悉了使用正则表达式匹配图片链接,尤其是针对特定格式文件的匹配。
- 路径处理: 学会了处理相对路径和绝对路径的问题,确保下载的图片链接正确无误。
- 文件操作: 掌握了使用
os模块创建目录和保存文件的方法,提高了对文件系统操作的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号