多种类型的神经网络(孪生网络)
目录:
一、CPPN(Compositional Pattern Producing Network)复合模式生成网络
CPPN是一种基于遗传算法演化神经网络结构的生成式模型。
1、前言:
一个圆的图像可以用函数表示:(x-x0)2+(y-y0)2 = 1
故图像可以表示为函数。而另一方面,神经网络可以逼近任何函数。因此,图像可以表示为神经网络。
2、CPPN结构

以上图中,网络输入是像素的坐标值(x,y),r为(x,y)到原点的距离,即根号(x2+y2)。z是一个随机的向量。输入为是三个标量和一个向量。
网络中的参数随机取值。
网络输出是一个像素的RGB值
把【0,0】-【100,100】坐标逐个输入,将输出的RGB值组成完整图像,将会是什么样子?

二、孪生网络(Siamese)【2-branches networks】
孪生网络(Siamese network)是一种网络结构,通过一个NN将样本的维度降低到某个较低的维度。
在低维空间,任意两个样本:
- 如果它们是相同类别,空间距离尽量接近0
- 如果它们是不同类别,空间距离大于某个间隔
1、孪生网络结构:
Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示。


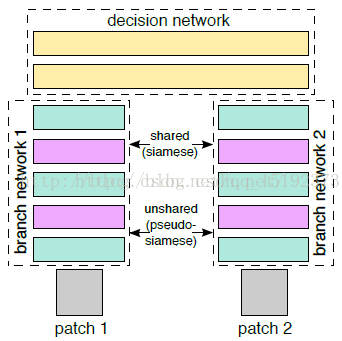
目的:比较两幅图片是否相似,或者说相似度是多少【匹配度】
输入:两幅图片
输出:一个相似度数值
Network1和Network2两个神经网络的权重一样,甚至可以两者是同一个网络,不用实现另外一个,因为权值都一样。对于siamese network,两边可以是lstm或者cnn,都可以。
2、伪孪生神经网络:
如果左右两边不共享权值,而是两个不同的神经网络,则模型叫pseudo-siamese network,伪孪生神经网络,如下图所示。对于pseudo-siamese network,两边可以是不同的神经网络(如一个是lstm,一个是cnn),也可以是相同类型的神经网络。
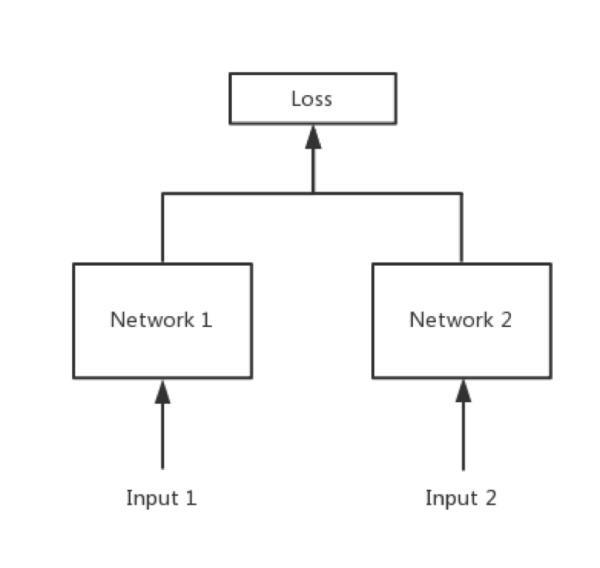
3、孪生神经网络的用途:衡量两个输入的相似程度。
孪生神经网络有两个输入(Input1 and Input2),将两个输入feed进入两个神经网络(Network1 and Network2),这两个神经网络分别将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
用途:
-
词汇的语义相似度分析,QA中question和answer的匹配,签名/人脸验证。
-
手写体识别也可以用siamese network,网上已有github代码。
-
还有kaggle上Quora的question pair的比赛,即判断两个提问是不是同一问题,冠军队伍用的就是n多特征+Siamese network,知乎团队也可以拿这个模型去把玩一下。
-
在图像上,基于Siamese网络的视觉跟踪算法也已经成为热点《Fully-convolutional siamese networks for object tracking》。
4、孪生神经网络和伪孪生神经网络分别适用于什么场景呢?
5、Siamese network 的损失函数:
Softmax当然是一种好的选择,但不一定是最优选择,即使是在分类问题中。【分类问题用交叉熵】
传统的siamese network使用Contrastive Loss【对比损失函数】。
对比损失函数如下:
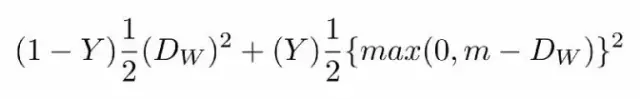
- 其中Dw被定义为姐妹孪生网络的输出之间的欧氏距离。Dw欧式距离公式如下:
![]()
- 其中Gw是其中一个姐妹网络的输出。X1和X2是输入数据对。
- Y值为1或0。如果模型预测输入是相似的,那么Y的值为0,否则Y为1。
- max()是表示0和m-Dw之间较大值的函数。
- m是大于0的边际价值(margin value)。有一个边际价值表示超出该边际价值的不同对不会造成损失。这是有道理的,因为你只希望基于实际不相似对来优化网络,但网络认为是相当相似的。
【损失函数还有更多的选择,siamese network的初衷是计算两个输入的相似度,。左右两个神经网络分别将输入转换成一个"向量",在新的空间中,通过判断cosine距离就能得到相似度了。Cosine是一个选择,exp function也是一种选择,欧式距离什么的都可以,训练的目标是让两个相似的输入距离尽可能的小,两个不同类别的输入距离尽可能的大。其他的距离度量没有太多经验,这里简单说一下cosine和exp在NLP中的区别。
根据实验分析,cosine更适用于词汇级别的语义相似度度量,而exp更适用于句子级别、段落级别的文本相似性度量。其中的原因可能是cosine仅仅计算两个向量的夹角,exp还能够保存两个向量的长度信息,而句子蕴含更多的信息(当然,没有做实验验证这个事情)。】
三、改进的Siamese网络(2-channel networks):
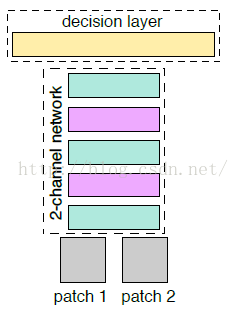
1. 让patch1、patch2分别经过网络,进行提取特征向量(Siamese 对于两张图片patch1、patch2的特征提取过程是相互独立的)
2. 然后在最后一层对两个两个特征向量做一个相似度损失函数,进行网络训练。
1. 把patch1、patch2合在一起,把这两张图片,看成是一张双通道的图像。也就是把两个(1,64,64)单通道的数据,放在一起,成为了(2,64,64)的双通道矩阵,
2. 然后把这个矩阵数据作为网络的输入,这就是所谓的:2-channel。
四、Triplet Network
Siamese network是双胞胎连体,Triplet network是三胞胎连体
论文是《Deep metric learning using Triplet network》,输入是三个,一个正例+两个负例,或者一个负例+两个正例,训练的目标是让相同类别间的距离尽可能的小,让不同类别间的距离尽可能的大。Triplet在cifar, mnist的数据集上,效果都是很不错的,超过了siamese network。
输入:x-与x是负样本,x+与x是相似正样本。
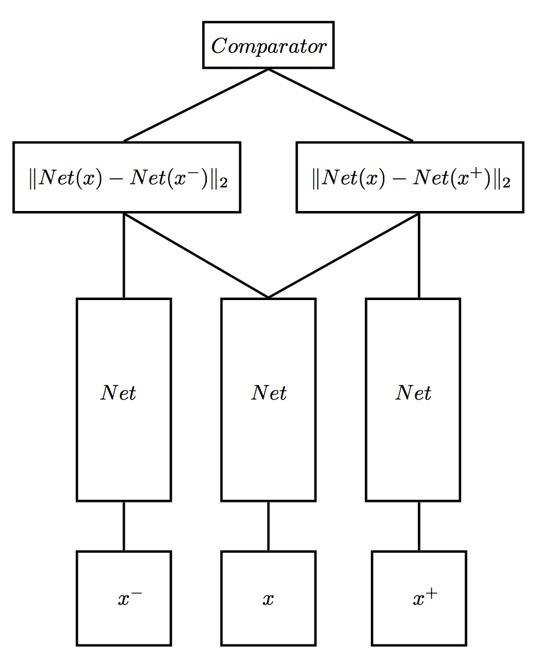
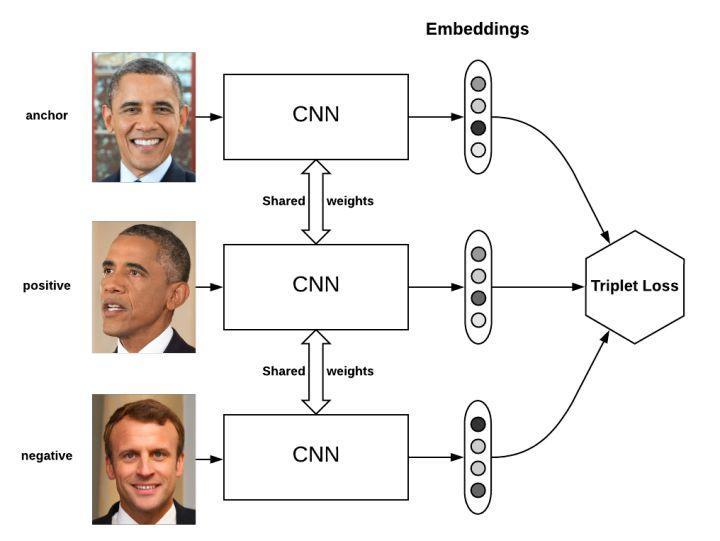
吴恩达老师视频中的三重损失函数:
代价函数是训练集的所有个体的三重损失的和:
![]()
三重损失函数:
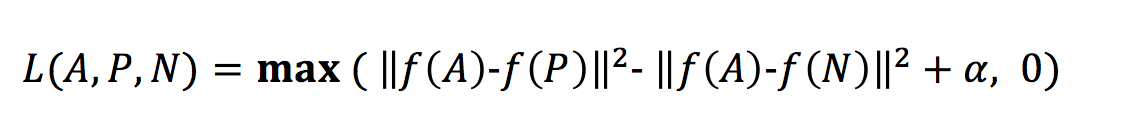
解释:
这里的最大化处理意味着只要 d(A, P)—d(A, N)+ α小于等于 0,那么 loss L(A, P, N) 就会是 0,但是一旦它大于 0,那么损失值就是正的,这个函数就会将它最小化成 0 或者小于 0。
这里的问题是,模型可能学习给不同的图片做出相同的编码,这意味着距离会成为 0,不幸的是,这仍然满足三重损失函数。因为这个原因,我们加入了边际α(一个超参数)来避免这种情况的发生。让 d(A,P) 与 d(N,P) 之间总存在一个差距。

为了比较图片 x(1) 和 x(2),我们计算了编码结果 f(x1) 和 f(x2) 之间的距离。如果它比某个阈值(一个超参数)小,则意味着两张图片是同一个人,否则,两张图片中不是同一个人。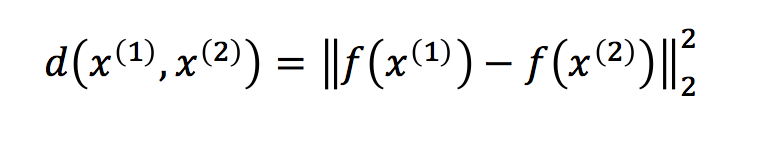 上式是 x1 和 x2 的编码之间的距离。
上式是 x1 和 x2 的编码之间的距离。
这适用于任何两张图片。【存在正负样本】

那么,为了得到对输入图片的良好编码,我们如何学习相应的参数呢?梯度下降
应用:
- Image ranking
- face verification
- metric learning
参考:
https://blog.csdn.net/qq_15192373/article/details/78404761
https://blog.csdn.net/Suan2014/article/details/80599595
pytorch人脸识别:http://www.techweb.com.cn/news/2017-07-21/2561327.shtml

 浙公网安备 33010602011771号
浙公网安备 33010602011771号