再探统计学
概览
-
C1-C6: 概率
-
C7-C11: 统计
-
期末 70%
-
平时 30%,可能包含 15%~20% 的期中考试,剩下的是作业
Chapter 1
基本概念
- 个体 unit,通常是一个人或者一个物体
- 个体的总体 population of units,没有明确的翻译,可以理解成所有人或所有物体
- 统计总体 statistical population,也可以简叫做 总体 population,是统计的属性的总体,比如人的身高啊之类的
- 样本 samples from a population,一般来说 \(\geq 30\) 且 随机 选择
- 随机数表 Random number table,表建好后,选数字,值域超出范围·或者重复出现的,删掉。
Chapter 2 描述数据的方法
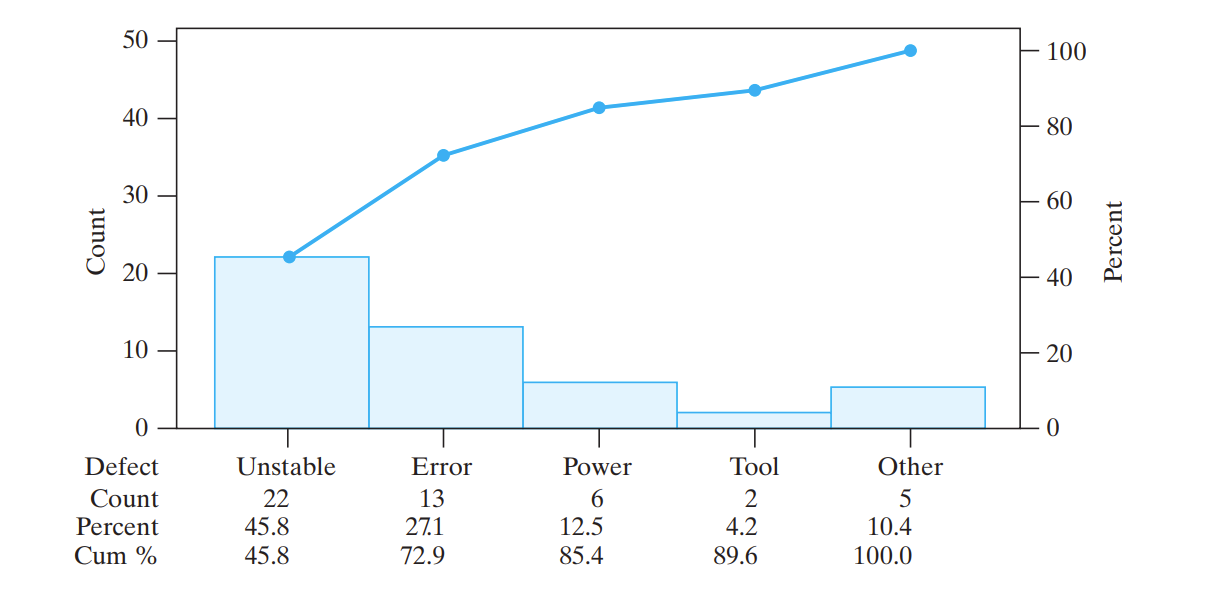
帕累托图 Pareto Diagrams
条形图和折线图的结合。
差不多就是,几个数据,最多的放左边,最少的放右边,Other(其他)放在最右边,条形柱子表示数量,百分比的前缀和用折线图。
这样,最左边的通常就是比较主要的数据。
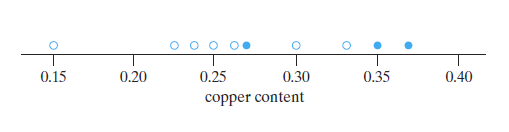
散点图 Dot Diagrams
两点作用。
- 可以很方便的看出异常值(离群值)。离群值 outlier,比如一堆几十的混进去一个几万的,无论是不是测量错误,都需要特殊关照。
- 感官上区分两组数据是否不同。比如实心点表示第一次测量,虚线点表示第二次。如果第一次普遍在左边,第二次普遍在右边,那么两组就明显数据不同。
频率分布 Frequency Distributions
几十个数据,一般分成五六个区间(等距、等间隔)。然后统计每个区间内的数量,换算成频率。应当是左闭右开或者左开右闭。
max 和 min 不一定是左端点或者右端点。比如 max 可能是 388,右端点可以取 400,好算。
最大的缺点是,位于一个区间内的数据出现了多少次,能知道,但是这个数字具体是谁,不知道。有一种不太精确的解决方案,是用一个区间的中点的值,作为 class mark,代表这个区间的所有数。
也有一种,把频率换成了前缀和。
频率分布(直方)图
通常,频率分布图都是 histogram(柱状图),常见的是频率分布直方图。
横坐标可以标注区间,也可以标注 class mark。
有单峰(peak)、双峰、斜的……
有的图纵坐标是个数,也有的图纵坐标是 \(\frac{\text{相对频率}}{区间宽度}\)。这样,所有条柱的面积总和就是 \(1\)。这种叫做 密度柱状图 density histogram。这种处理方式是「归一化」。
茎叶图 Stem-and-Leaf Displays
频率图可以知道有 \(x\) 个数在某个区间里,但是不知道具体是多少。茎叶图可以直观地看出来一个区间有多少个数字,还能保留原始数据。
然而一般茎叶图都是,每 10 个分一个区间。左侧(stem,茎)记录抠掉个位的,右边(leaf,叶)是个位。
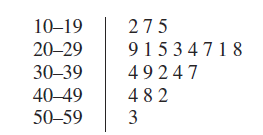
描述测量 Descriptive measures
- 平均值 sample mean,$$\bar x = \frac{1}{n} \times \sum_{i=1}^n x_i$$
- 中位数 sample median,若 \(n\) 是奇数,就是第 \(\frac{n+1}{2}\) 个;若 \(n\) 是偶数,就是第 \(\frac{n}{2}\) 和 \(\frac{n}{2}+1\) 个的平均。
中位数不容易被少数的异常值影响。如:\([10, 10, 10, 10, 200]\)。
在统计学中,异常值是指与其他观测值有显著差异的数据点。异常值可能是由实验误差造成;后者有时会从数据集中排除。异常值可能会导致统计分析中出现严重问题。能妥善处理异常值的估计量,称为“稳健”。例如,中位数是集中趋势的稳健统计量,但平均数则不然。
- 样本方差 sample variance,描述偏离程度,$$s^2 = \frac{\sum_{i=1}^{n}(x_i - \bar x)^2 }{n-1} = \frac{ \sum_{i=1}{n}x_i2 - \frac{(\sum_{i=1}{n}x_i)2}{n}}{n-1}$$,这个等式可以用完全平方公式推导。关于分母为啥是 \(n-1\) 不是 \(n\),大概原因是因为这个式子的分子永远偏小,所以调整一下分母,具体原因后面再推。可参考 知乎.
- 标准差 standard deviation,\(s = \sqrt{s^2}\)
- 相对方差 relative variation,\(V = \frac{s}{\bar x} \times 100\%\),意义参考课本 P39 E13
推导方差
对于 独立 的随机变量 \(X_1\), \(X_2\),有 $$\begin{aligned}0 &= E[(X_1-\mu_1)(X_2-\mu_2)] \ &= E(X_1X_2-\mu_1X_2-\mu_2X_1+\mu_1\mu_2) \ &= E(X_1X_2)-\mu_1E(X_2) - \mu_2E(X_1)+\mu_1\mu_2 \ &= E(X_1X_2)-\mu_1\mu_2-\mu_2\mu_1+\mu_1\mu_2 \ &= E(X_1X_2)-\mu_1\mu_2\end{aligned}$$,因此 $$E(X_1X_2)=\mu_1\mu_2$$
于是:
四分位、百分位 Quartiles and Percentiles
(这个概念的定义不同教材可能不同)
直观理解,中位数就是排在 50% 位置的,那么第一二三四分位就分别是 25%,50% 和 75% 位置的,分别表示为 \(Q_1, Q_2, Q_3\)。百分位,就是任意百分之几位置的。
具体定义,\(100p\)-th 的数,就代表至少有 \(100p\%\) 的数小于等于它,也有至少 \(100(1-p)\%\) 的大于等于它。计算方法就是,先排序,若 \(np\) 不是整数,然后计算出 \(k = \lceil np \rceil\) 的值,那么第 \(k\) 个就是;如果 \(np\) 是整数,那么第 \(np\) 和第 \(np+1\) 个的平均值就是。
极差 range 就是最大值减去最小值。四分位距 interquartile range 就是 \(Q_3 - Q_1\)。
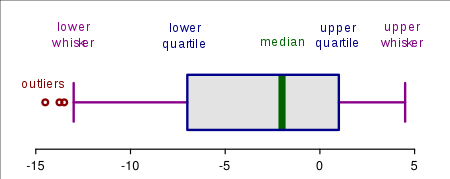
箱线图 boxplot
表示从 \(Q_1\) 到 \(Q_3\) 的数据;是个方块;方块以外用横线表示。
中间那条竖线是 \(Q_2\),也就是中位数。
但是不能体现异常值。
修正箱线图 modified boxplot
可以体现异常值。原理就是,如果最大值与 \(Q_3\) 的距离在 1.5 倍箱线长度之内,就正常画线;否则,线画到 1.5 倍以内最远的一个数据,将离群值用圆点标注。\(Q_1\) 那一段同理。
注意,修正箱线图的边界,是 正常值范围内的最大/最小值,而不是正常值范围。
Chapter 3 概率
样本空间与事件 Sample Spaces and Events
样本空间一般用花体字母 \(\mathcal{S}\) 表示。可以分为离散样本空间、连续样本空间。
样本空间的任何子集,叫做事件。当然空集 \(\emptyset\) 也是子集,算一个事件。
互斥事件 mutually exclusive event,就 看交集是不是空集。是空集就互斥了,\(A\) 发生则 \(B\) 不可能发生。
排列组合
公理和定理
公理
对于 有限集 的样本空间 \(\mathcal{S}\):
- \(\forall A \in \mathcal{S}, 0 \leq P(A) \leq 1\)
- \(P(S) = 1\)
- 若 \(A\) 与 \(B\) 是 \(\mathcal{S}\) 当中的 互斥 事件(\(A \cap B = \emptyset\)),则 $$P(A \cup B) = P(A) + P(B)$$
- 推论:若 \(A_1, A_2, \cdots, A_n\) 两两互斥 的,则它们当中至少发生一个的概率,等于所有概率之和 $$P(A_1 \cup A_2 \cup \cdots A_n) = P(A_1) + P(A_2) + \cdots + P(A_n)$$
定理
- 对于 任意两个事件(不要求互斥)(\(A \cap B \not= \emptyset\)),$$P(A \cup B) = P(A) + P(B) - P(A \cap B)$$,可以结合韦恩图辅助理解。
- \(P(\overline A) = 1 - P(A)\)
- 德摩根:\(\overline{A \cup B} = \overline A \cap \overline B\),\(\overline{A \cap B} = \overline A \cup \overline B\)
条件概率 conditional probability
若 \(A, B \in \mathcal{S}\) 且 \(P(B) \not= 0\),则已知 \(B\) 的情况下 \(A\) 发生的概率(the conditional probability of \(A\) given \(B\))记作 \(P(A|B)\),$$P(A|B) = \frac{P(A \cap B)}{P(B)}$$
如果知道了条件概率,也可以反推他们交的概率(其实就是相当于把分母挪走了)。$$P(A \cap B)= \begin{cases}P(A) P(B \mid A) & \text { if } P(A) \neq 0 \ P(B) P(A \mid B) & \text { if } P(B) \neq 0\end{cases}$$
独立事件
若 \(A, B\) 相互独立,当且仅当 \(P(A|B)=P(A)\),或 \(P(B|A)=P(B)\)。
也有的地方说 独立 事件的定义是,$$P(A \cap B) = P(A)P(B)$$,这两种不同写法是等价的。
独立意味着条件概率没有意义了,也就是两个事件没关系的意思。
有的题目当中,是否独立需要算算;也有的题目当中,是否独立需要根据实际生活i经验判断。
注意,独立事件和互斥事件是两码事 https://zhuanlan.zhihu.com/p/53736521。
如果事件 \(A\) 和事件 \(B\) 发生的概率都不为 \(0\),那么独立和互斥有这样一层关系:互斥不独立,独立不互斥。可以这样理解:互斥是指 A 发生则 B 必不发生,这相当于一种特殊的关系,所以他不能算是「独立」。
零概率事件与任何事件独立;\(1\) 概率事件与任何事件独立。
不可能事件与任何事件既独立又互斥(零概率事件与不可能事件是不同的)
贝叶斯公式 Bayes' Theorem
全概率公式 rule of total probability
若 \(B_1, B_2, \cdots, B_n\) 互斥且至少有一个必定发生(\(\bigcup_{i=1}^n B_i = \mathcal{S}\)),则 $$\boxed{P(A) = \sum_{i=1}^nP(B_i)\cdot P(A\mid B_i)}$$,这两坨相乘相当于求交的概率。
贝叶斯公式
Bayes' theorem provides a formula for finding the probability that the “effect” A was “caused” by the event \(B_r\).
贝叶斯公式由果推因。$$\boxed{\begin{aligned}P\left(B_r \mid A\right) &= \frac{P(A \cap B_r)}{P(A)} \ &= \frac{P\left(B_r\right) \cdot P\left(A \mid B_r\right)}{\sum_{i=1}^n P\left(B_i\right) \cdot P\left(A \mid B_i\right)}\end{aligned}}$$
贝叶斯公式的分母,就是全概率公式。
Chapter 4 概率分布
一些概念
随机变量 Random Variable:是一个函数,对每个输出指定一个数值。比如抛硬币,正面指定是 \(1\),反面指定是 \(0\)。
概率分布 Probability Distribution:随机变量等于某一个数值 \(x\) 的概率,就是概率分布。比如 \(f(x) = P[X = x]\).对于离散变量的分布,可以画表格表示。概率分布一定满足 \(f(x) \geq 0 \wedge \Sigma f(x) = 1\).
结合使用随机变量和概率分布,能把现实生活中的问题转换成数的问题。
定义大写 \(F(x) = P[X \leq x] \forall x \in (-\infty, \infty)\). 这个叫做 累积分布 cumulative distribution,就跟前缀和似的。
因为 离散 的累积分布像是前缀和,所以 \(P(a \leq X \leq b) = F(b) - F(a-1)\) 而不是 \(F(b) - F(a)\)!如果是连续的,那就无所谓了。
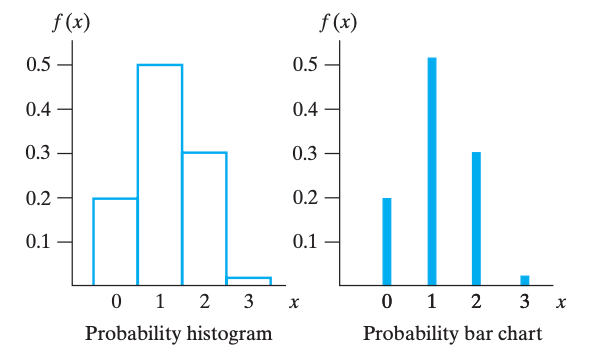
概率分布画图有两种,一种是 柱状图 histogram(左),另一种是 bar 图(右)。
二项分布 Binomial Distribution
注意,二项分布不是伯努利分布。伯努利分布就是二点分布(\(n=1\))。二项分布相当于二点分布重复 \(n\) 次。
首先考虑 伯努利试验 Bernoulli trials,它满足以下条件:
- 每一个试验只有 两个输出。比如抛硬币
- 不管是第几次试验,两个输出的 概率都是恒定的,一个概率恒定是 \(p\),另一个恒定是 \(1-p\);也就是说每次试验概率保持一致。比如抛硬币
- 每一次试验之间是 独立 的,互不影响。比如抛硬币
在本节课中,额外加入一个条件:固定 \(n\) 次。
定理:二项分布,进行 \(n\) 次伯努利试验,每次成功概率是 \(p\),那么恰好成功 \(x\) 次的概率是 $$\boxed{b(x; n, p) = C_nxpxq^{n-x}}$$, 其中 \(x=0,1,\cdots,n\),\(q=1-p\)。
定义大写 $$B(x; n, p) = \sum_{k=0}^xb(k; n, p)$$,其中 \(x=0,1,\cdots,n\),\(q=1-p\)。相当于前缀和。
备注:假设检验:统计上,一般以 \(5\%\) 作为界限。若根据某断言计算出概率小于 \(5\%\),则一般认为断言是错误的,因为概率低的事件一般不会在偶然试验当中发生。
期望与方差
随机变量 \(X\) 的平均值(期望值),记作 \(\mu\) 或 \(E(X)\),定义为:$$\mu=E(x)=\sum_x x \cdot f(x)$$;而随机变量 \(X\) 的 方差(variance) 记作 \(\sigma^2\),定义为:$$\begin{aligned}\sigma2&=\sum_x(x-\mu)2 f(x) \ &=E\left(X2\right)-(E(X))2\end{aligned}$$,等于「平方的期望减去期望的平方」;标准差(standard deviation) 记作 \(\sigma\),定义为:$$\sigma=\sqrt{\sum_x(x-\mu)^2 f(x)}$$。
平方求和公式
\(\sum_{i=1}^n i^2 = \frac{n(n+1)(2n+1)}{6}\)
常见分布的期望与方差
- 二项分布:期望 \(np\),方差 \(npq\)
- 泊松分布:期望 \(\lambda\),方差 \(\lambda\)
切比雪夫定理 Chebyshev’s theorem
也有的教材管它叫做「切比雪夫不等式」。
切比雪夫定理:对于一个随机变量,若期望是 \(\mu\),标准差是 \(\sigma\),那么取到一个在 \(k\) 倍标准差以外的值的概率不会高于 \(\frac{1}{k^2}\),即 $$\boxed{P(|X - \mu| \geq k\sigma) \leq \frac{1}{k^2}}$$,也就是说,随机变量的所有值,基本都是接近于期望(平均)的。这个式子也叫做切比雪夫不等式。
泊松分布 Poisson
假如已知 \(X\) 的平均值是 \(\lambda\),\(X = x\) 的概率是 $$\boxed{f(x;\lambda) = \frac{\lambdaxe{-\lambda}}{x!}}$$。
在网上找到了一个泊松分布公式的记忆方法:
- 在马路上,有人戴着奇形怪状的帽子(\(\lambda^x\));你看到了,说:「咦(\(e\)),有一个人(\(-\lambda\)),」
- 「帽子很怪!(\(x!\))」
- 上面一句话是分子,下面一句话是分母,合起来就是泊松分布公式 $$\frac{\lambdaxe{-\lambda}}{x!}$$
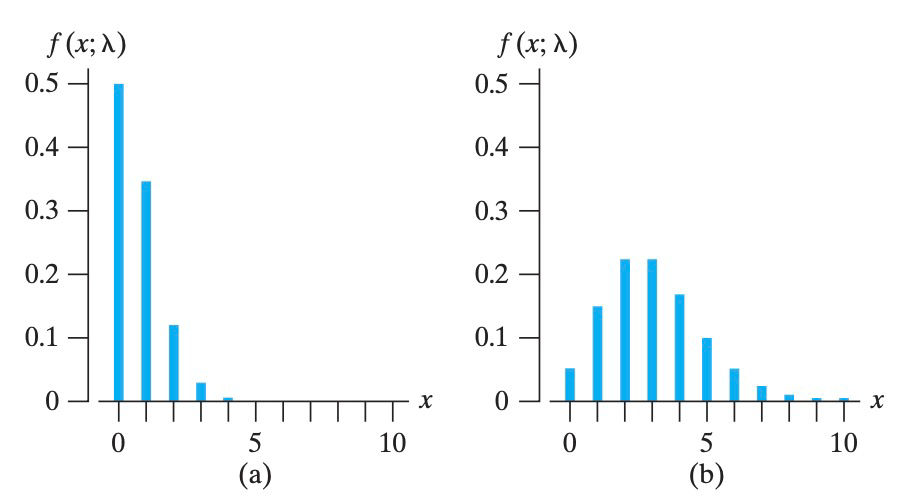
若 \(\lambda\) 是整数,那么 \(f_{\max}(x;\lambda) = f(\lambda-1;\lambda) = f(\lambda;\lambda)\);若 \(\lambda\) 不是整数,则 \(f_{\max}(x;\lambda) = f(\lfloor\lambda\rfloor;\lambda)\)。下图分别表示 \(\lambda=0\) 和 \(\lambda=3\) 的情况:
用泊松分布近似计算二项分布
若 \(n \to \infty\) 且 \(p \to 0\),\(np=\lambda\) 视作常数,那么二项分布的计算(\(n\) 太大组合数和幂次不好算)可以用泊松分布来近似:$$\boxed{b(x;n,p) = f(x;np)}$$,具体证明如下:$$\begin{aligned}b(x ; n, p) &= C_nxpxq^{n-x} \ &= \frac{n !}{x !(n-x) !}\left(\frac{\lambda}{n}\right)x\left(1-\frac{\lambda}{n}\right) \ &\approx \frac{\lambda^x e^{-\lambda}}{x !} \ &= f(x; np)\end{aligned}$$;根据经验,\(n\geq 20\) 且 \(p \leq 0.05\) 的时候,或 \(n\geq 100\) 且 \(\lambda = np \leq 10\) 的时候,可以用这个近似。
泊松过程 Poisson Process
把一大段时间等分成若干份极短的时间 \(T = n\Delta t\),假设每一段小时间上事件发生都是独立的,概率都是 \(p = \alpha\Delta t\),且要么发生要么不发生(每个小区间上都是二项分布)。
若 \(\Delta t\) 极小,就意味着 \(n\) 非常大。
于是,\(np = n\alpha\Delta t = \alpha T\),这意味着这个概率服从 \(\lambda = np = \alpha T\) 的泊松分布,\(\lambda\) 与 \(T\) 成正比。i.e,如果 \(T\) 是一天的时候 \(\lambda=5\),那么 \(T\) 取两天的时候,\(\lambda\) 就是 \(2\times 5=10\) 了。
Chapter 5 概率密度 Probability Density
这一章的重点内容是正态分布与联合分布
连续随机变量和概率密度函数
对于区间 \([a,b]\),分成 \(m\) 个区间,每个区间长度都是 \(\Delta x\),第 \(i\) 个区间的高度记作 \(f(x_i)\),一段小区间的概率就是这段的面积。这个 \(f(x_i)\) 就是概率密度函数。
如果 \(\Delta x\) 足够小,那么 \(f(x_i)\) 就是一个光滑的函数图。整个的面积 \(\sum_{i=1}^m f(x_i)\Delta x_i\)。
所以,$$\begin{aligned}P(a\leq X \leq b) &= \sum_{i=1}^m f(x_i)\Delta x_i \ &= \int_a^bf(x)\text{d}x\end{aligned}$$。
由于是连续的,所以对于一个 单独的点上的概率,是零,因为线的面积是零。于是:$$P(a\leq X \leq b) = P(a < X < b)$$。
这个叫做 概率密度函数(probability density function),也可以叫
做概率密度,满足:
- \(\forall x\), \(f(x) \geq 0\)
- \(\int_{-\infty}^{\infty}f(x)\text{d}x = 1\)
它的累积分布函数 \(F(x)\),显然满足:
- 定义式:$$F(x) = P(X \leq x) = \int_{-\infty}^x f(t)\text{d}t$$
- 一段上的概率:$$P(a \leq x \leq b) = \int_a^b f(x)\text{d}x = F(b) - F(a)$$
- 导数:$$\frac{\text{d}F(x)}{\text{d}x} = f(x)$$,因为「先积分再求导就是函数本身」
例子 5.2(课本 5.3),为啥 \(k=8\)
期望和方差
定义期望 $$\mu = E(x) = \int_{-\infty}^{\infty}xf(x)\text{d}x$$,定义方差 $$\begin{aligned}\sigma^2 &= \int_{-\infty}{\infty}(x-\mu)2f(x)\text{d}x \ &= \int_{-\infty}{\infty}x2f(x)\text{d}x - \mu^2 \ &= E(x^2) - (E(x)^2) \end{aligned}$$,依然满足「平方的期望减去期望的平方」。
回顾:分部积分
LIATE
按照以下优先级顺序,从上往下依次选择 \(u = u(x)\),从下往上选择 \(\text{d}v = v'(x)\text{d}x\):
- 对数函数,\(\ln x\) 等
- 反三角函数,\(\arctan(x)\) 等
- 幂函数(代数函数),\(x^2\), \(3x^{50}\) 等
- 三角函数,\(\sin(x)\) 等
- 指数函数,\(e^x\) 等
正态分布 normal distribution(在 \(\mathbb{R}\) 上取值)
定义正态分布表达式:$$f(x;\mu,\sigma^2) = \frac{1}{\sqrt{2\pi}\sigma}e{-\frac{(x-\mu)2}{2\sigma^2}}$$,其中的 \(\mu\) 和 \(\sigma^2\) 分别表示期望和方差,但是这里的计算(积分)不做要求。
根据图像可以得知,正态分布图像是以 \(\mu\) 为对称轴,左右对称的。

标准正态分布(在 \(\mathbb{R}\) 上取值)
期望是零、方差是一 的正态分布叫做 标准正态分布(standard normal distribution):$$f(x; 0, 1) = \frac{1}{\sqrt{2\pi}}e{-\frac{x2}{2}}$$,它的积分也不做要求。
(标准正态分布习惯上喜欢用字母 \(z\) 代替 \(x\)),它的概率密度函数(Excel 可以算)是: $$\begin{aligned} & F(z) = P(Z \leq z) = \frac{1}{\sqrt{2\pi}}\int_{-\infty}^z e{\frac{-t2}{2}} \text{d}t \ & F(-z) = 1 - F(z)\end{aligned}$$。
关于分位点 \(z_{\alpha}\)
\(P(Z > z_\alpha) = \text{val}\) 的点就是 \(z_\alpha\),即 \(F(1 - Z_\alpha) = \text{val}\),在 Excel 当中可以用 NORM.S.INV() 计算。
换句话说,\(z_\alpha = \text{val}\) 表示,横坐标 \(\text{val}\) 之后的部分的面积是 \(\alpha\).
\(z_{0.01}=2.33\),\(z_{0.05}=1.96\),\(z_{0.025}=1.645\),这三个分位点在数据分析和假设检验等领域很常用。
例子 5.5
正态分布转化到标准正态分布
对于一个普通正态分布函数,先平移 \(\mu\) 个单位,期望就从 \(\mu\) 变成 \(0\) 了;再伸缩到 \(\frac{1}{\sigma}\),标准差就从 \(\sigma\) 变成 \(1\) 了,于是它变成了一个标准正态分布函数。
因此,如果 \(X\) 满足正态分布,那么 \(Z = \frac{X - \mu}{\sigma}\) 就满足标准正态分布。
于是,对于正态分布:
例子 5.11,5.12
\(\ln x\) 的期望和标准差分别是 \(\alpha\), \(\beta\),对于 \(x\) 是:
- 期望:\(e^{\alpha + \frac{\beta^2}{2}}\)
- 方差:\(e^{2\alpha + \beta^2}(e^{\beta^2}-1)\)
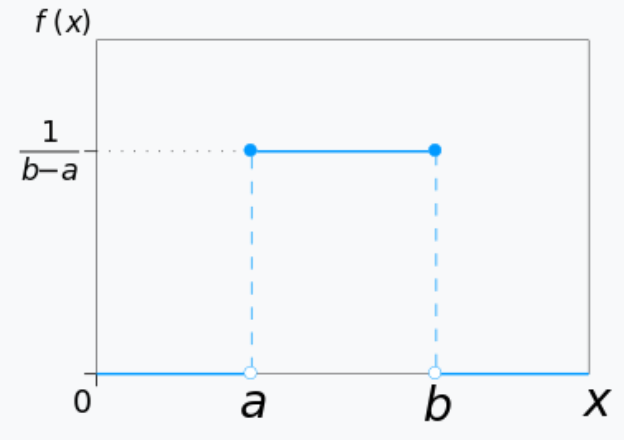
均匀分布 uniform distribution(在 \(\mathbb{R}\) 上取值)
均匀分布有两个参数 \(\alpha\),\(\beta\),它的概率密度函数是 $$f(x) = \begin{cases}\frac{1}{\beta - \alpha} &, \alpha < x < \beta \ 0 &,\text{otherwise}\end{cases}$$。均值是 \(\frac{\alpha + \beta}{2}\),方差是 \(\frac{(\beta - \alpha)^2}{12}\)。
伽马分布 Gamma Distribution(在 \((0,\infty)\) 上取值)
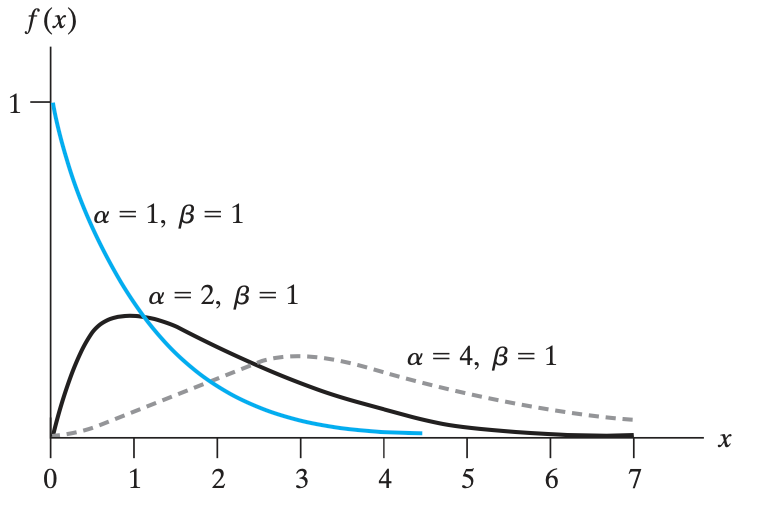
定义伽马分布(取值只能是正的):$$f(x)= \begin{cases}\frac{1}{\beta^\alpha \Gamma(\alpha)} x^{\alpha-1} e^{\frac{-x}{\beta}}, & \text { for } x>0, \alpha>0, \beta>0 \ 0, & \text { elsewhere }\end{cases}$$,其中 \(\Gamma(\alpha)\) 是伽马函数的值,定义为:$$\Gamma(\alpha) = \int_0{\infty}xe^{-x}\text{d}x$$。
伽马函数性质
当 \(\alpha > 1\),有 $$\Gamma(\alpha) = (\alpha - 1)\Gamma(\alpha-1)$$,这个性质可以用 \(\Gamma(\alpha+1)\) 推导。
另外,由于 $$\begin{aligned}\Gamma(1) &= \int_0{\infty}e\text{d}x \ &=-e^{-x} \mid_0^{\infty} \ &= -(0 - 1) \ &= 1 \end{aligned}$$,因此当 \(\alpha\) 是正整数的时候,伽马函数表示阶乘,容易得到:$$\Gamma(\alpha) = (\alpha-1)!$$。顺带一提,\(\Gamma(0.5) = \pi\)。
伽马分布的期望与方差
- 期望:\(\alpha\beta\)
- 方差:\(\alpha\beta^2\)
指数分布
当 \(\alpha=1\),伽马分布就变成了一个 指数分布(exponential distribution) 的形式:$$\boxed{f(x)= \begin{cases}\frac{1}{\beta} e^{\frac{-x}{\beta}}, & \text { for } x>0, \beta>0 \ 0, & \text { elsewhere }\end{cases}}$$。
二级结论:关于泊松过程与指数分布
先回顾一下,泊松分布的式子是:\(f(x;\lambda) = \frac{\lambda^xe^{-\lambda}}{x!}\),泊松过程是 \(\lambda=\alpha T\) 即 \(f(x;\lambda)=\frac{(\alpha T)^xe^{-\alpha T}}{x!}\)。
若在一个泊松过程当中,单位时间内的发生次数是 \(\alpha\),那么,相邻两次发生之间的 间隔时间,服从参数 \(\beta = \frac{1}{\alpha}\) 的指数分布。代入指数分布的式子,得到 $$\boxed{f(x) = \alpha e^{-\alpha x}}$$。
例题 5.13
假如每个小时平均会有三辆卡车到仓库卸货。求:
- 连续两辆车到达之间的间隔时间,少于 5min 的概率
- 连续两辆车到达之间的间隔时间,不少于 45min 的概率
方法一:用泊松过程计算
- 此时 \(\lambda = 3 \times \frac{5}{60} = 0.25\)。题目要求间隔时间小于 5min,那 5min 内再来 1 个、2 个、3 个…只要不是零个,都行。所以答案就是 1 减去 0 个来的概率 $$1 - f(0;\lambda) = 1-0.779 = 0.221$$
- 此时 \(\lambda = 3 \times \frac{45}{60} = 2.25\)。题目要求间隔时间至少 45min,那 45min 内一个都不能来,只能是零个,所以答案是 $$f(0;\lambda) = 0.105$$
方法二:用指数分布计算
-
\[\int_0^\frac{1}{12}3e^{-3x}\text{d}x = 1-e^{-\frac{1}{4}} = 0.221 \]
-
\[\int_\frac{3}{4}^\infty3e^{-3x}=e^{-\frac{9}{4}} = 0.105 \]
作业 5.61,5.62 都没搞明白
贝塔分布 Beta Distribution(在 \((0,1)\) 上取值)
定义贝塔分布 $$f(x)= \begin{cases}\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha) \Gamma(\beta)} x{\alpha-1}(1-x), & \text { for } 1>x>0, \alpha>0, \beta>0 \ 0, & \text { elsewhere }\end{cases}$$,期望方差分别是 $$\mu=\frac{\alpha}{\alpha+\beta}, \quad \sigma^2=\frac{\alpha \beta}{(\alpha+\beta)^2(\alpha+\beta+1)}$$。
例子 5.14
韦伯分布 Weibull distribution(在 \((0,\infty)\) 上取值)
例子 6.2
中心极限定理 Central limit theorem(要求 \(\sigma\) 已知)
有一个均值为 \(\mu\)、方差是 \(\sigma^2\) 的总体,从中搞一个样本出来,若样本均值是 \(\overline{X}\),则标准化后的样本均值 standardized sample mean 是 $$Z=\frac{\overline{X}-\mu}{\frac{\sigma}{\sqrt{n}}}$$,当 \(n\) 足够大,这个 \(Z\) 就服从标准正态分布(做题的时候一般 \(n\geq25\) 就是了)
\(Z\) 的分母里面是 \(Var(\overline{X})\) 开根号。也就是说,\(\overline{X} \sim N\left(\mu, \left(\frac{\sigma}{\sqrt{n}}\right)^2\right)\)。
注意:这里的正态分布,标准差是样本的,而不是原始总体的!

就是说,计算一个平均值(\(\overline{X}\))满足的分布,很难(因为即使是 \(X\) 的分布都不一定能算)。由于不太关心精确值,\(n\) 充分大的时候,尽管精确表达式不知道,就可以用正态分布去很好的逼近,所以直接用正态分布算就行了。前提是原始的方差 \(\sigma\) 已知。
顺带一提,如果原始数据本身(总体)就已经服从正态分布了,那么随机样本还是服从正态分布的。即:若总体不是正态分布,只有 \(n\) 足够大的时候样本才接近正态分布;总体服从正态分布,无论 \(n\) 多大样本都服从正态分布。
t-分布:\(\sigma\) 未知,但 \(\mu\) 已知
\(\overline{X}\) 是从一个服从 \(N(\mu,\sigma^2)\) 的 正态分布的总体(\(\sigma\) 未知)当中抽出来的样本的均值,且 \(S = \sqrt{\sum\frac{(X_i-\overline{X})^2}{n-1}}\) 是 样本 的标准差,那么 $$t=\frac{\overline{X}-\mu}{\frac{S}{\sqrt{n}}}$$,这个 \(t\) 就服从参数(自由度)为 \(\nu=n-1\) 的 t-分布。
\(t\) 的概率密度函数长得很复杂:$$p_t(y)=\frac{\Gamma\left(\frac{n+1}{2}\right)}{\sqrt{n \pi} \Gamma\left(\frac{n}{2}\right)}\left(1+\frac{y2}{n}\right){2}}, \quad y \in \mathbb{R}$$。
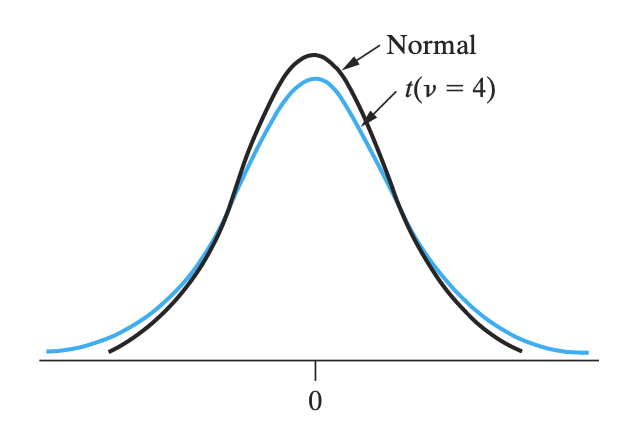
t-分布的性质
- t-分布的形状左右对称
- t-分布的尾巴比正态分布的大,意味着不太集中(发散),也就是方差大一些
- 若 \(n>1\),则 t-分布的均值是零(对称轴)
- 若 \(n>2\),则 t-分布的方差是 \(\frac{n}{n-2}\)
- 当 \(n\) 足够大(一般 \(n \geq 30\)),则 t-分布非常接近正态分布
- 在实际上,t-分布假设了总体是服从正态分布的,但是严格正态分布可能比较难。所以基本上是正态分布的也可以用 t-分布。
例子 6.4
卡方分布 chi-square:\(\sigma\) 已知,不关心 \(\mu\)
设 \(S^2\) 是一个从服从方差为 \(\sigma^2\) 的 正态分布的总体 当中抽取的大小为 \(n\) 的样本的方差。那么 $$\chi^2=\frac{(n-1) S2}{\sigma2}=\frac{\sum_{i=1}n\left(X_i-\bar{X}\right)2}{\sigma^2}$$,这个变量 \(\chi^2\) 就服从参数自由度为 \(v=n-1\) 的 chi-square 分布。
卡方分布是 \(\alpha=\frac{\nu}{2}\),\(\beta=2\) 的伽马分布的特例。=???remark 6.3
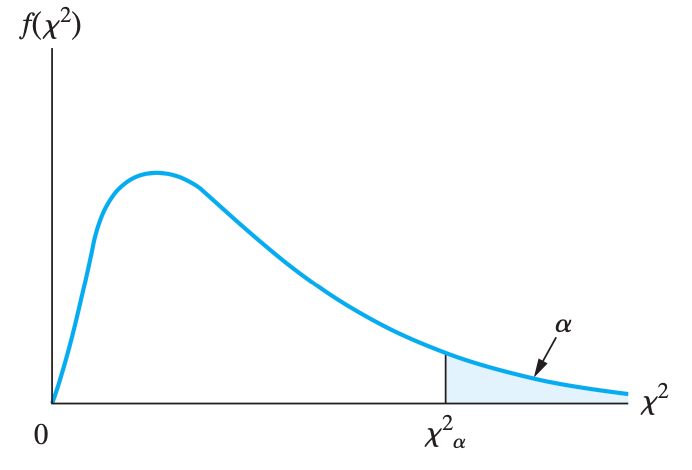
例子 6.5
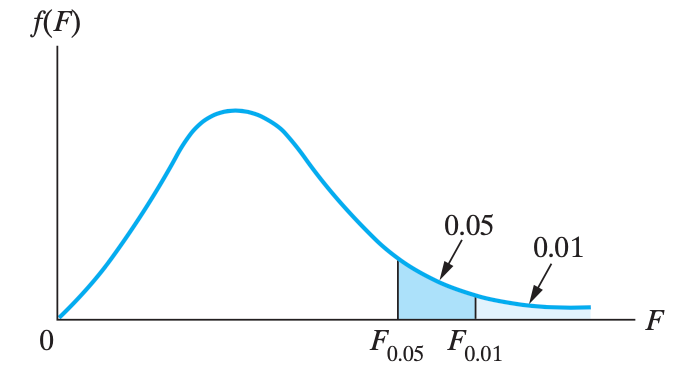
F 分布:用于检查两个总体的 \(\sigma\) 是否相同
若从 方差相等但未知的服从正态分布的两个总体 当中,分别抽取两个大小为 \(n_1\), \(n_2\) 的样本。设两个样本方差分别是 \(S_1^2\), \(S_2^2\),那么 \(F = \frac{S_1^2}{S_2^2}\) 就是一个服从参数为 \(\nu_1=\nu_2=n-1\) 的 F 分布的随机变量。
F 分布的概率密度函数是 $$p(y)=\frac{\Gamma\left(\frac{m+n}{2}\right)\left(\frac{m}{n}\right)^{\frac{m}{2}}}{\Gamma\left(\frac{m}{2}\right) \Gamma\left(\frac{n}{2}\right)} y^{\frac{m}{2}-1}\left(1+\frac{m}{n} y\right)^{-\frac{m+n}{2}}$$
例子 6.6
对于其分位点,还满足 $$F_{1-\alpha}\left(\nu_1, \nu_2\right)=\frac{1}{F_\alpha\left(\nu_2, \nu_1\right)}$$,这个性质,它的用处是,做分布表格的时候,可以假设 \(\nu_1<\nu_2\),节省纸面空间。所以考试的时候如果查表查不到,那就交换分位点,交换自由度,取个倒数再去查查。
例子 6.7
图像如下
Chapter 7 关于均值的推断
需要掌握的例题有
区间估计:6(大样本知道方差) 7(大样本不知道方差) 8(小样本)
极大似然估计:9 10 11 12(极大似然估计的基本做法)
假设检验:19(大样本方差未知) 20(小样本)
只知道样本的,不知道总体的,用样本的对总体的进行推断和估计。
The two main classes of statistical inference are estimation of
parameters and testing hypotheses(参数估计(包括点估计、区间估计)、假设检验)
点估计:均值
根据 \(X_1, X_2, \cdots, X_n\),可以得到 \(\overline X\),这个值就是估计的总体均值 \(\mu\),这个估计的标准误差是 \(\frac{s}{\sqrt n}\)。
最大估计误差 maximum error of estimate
根据中心极限定理,有 $$Z=\frac{\overline X - \mu}{\frac{\sigma}{\sqrt{n}}} \sim N(0,1)$$。要让服从标准正态分布的 \(Z\) 落在区间 \([-z_{\alpha/2}, z_{\alpha/2}]\) 内,通过化简得到:$$\left|\overline X - \mu\right| \leq z_{\alpha/2}\cdot\frac{\sigma}{\sqrt{n}}$$,于是,$$\boxed{E = z_{\alpha/2}\cdot\frac{\sigma}{\sqrt{n}}}$$,即 $$\mu-E \leq \overline X \leq \mu+E$$。
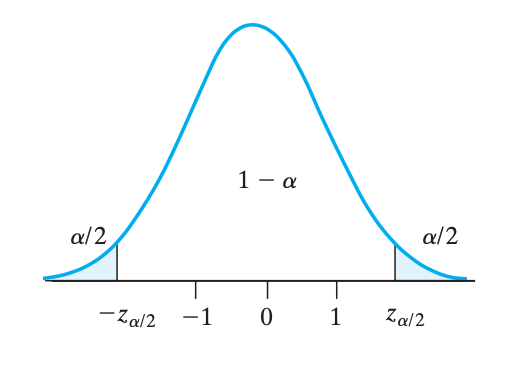
二级结论:\(\sigma\) 未知的情况
如果 \(\sigma\) 未知且 \(n\) 比较大,那直接用 \(s\) 代替 \(\sigma\) 就好了。但是如果 \(n\) 不是很大,也可以用 \(s\) 代替 \(\sigma\),但是要把 \(z\) 分位点改成 \(t\) 分位点:$$E = t_{\alpha/2}\cdot\frac{s}{\sqrt{n}}$$。
二级结论:样本要多大?
要满足 \(P(|\overline X - \mu| < E) = 1-\alpha\),需要满足样本大小 \(n\),把之前 \(E\) 的公式移项化简一下,得到 \(n\) 至少要是:$$n_{\min} = \left(\frac{\sigma\cdot z_{\alpha/2}}{E}\right)^2$$。
无偏估计
无偏性、有效性
知道有这么回事儿就行了(稀里糊涂的)
当且仅当 \(E(\hat\theta) = \theta\) 则称这个 \(\theta\) 的估计是无偏的,其中 \(\hat\theta\) 表示估计量,即对 \(\theta\) 的估计值。大概意思就是估计的值恰好就是真实值,比如 \(E(\overline X) = \mu\)
若有两个估计都是无偏的,那么方差小的那个就是 更好(more efficient) 的。
区间估计:均值
置信区间 confidence interval
对于较大(\(n\geq30\))的样本,若总体标准差 \(\sigma\) 已知,则 \((1-\alpha)100\%\) 的置信区间是:$$\boxed{\left(\bar{X}-z_{\alpha / 2} \cdot \frac{\sigma}{\sqrt{n}}, \quad \bar{X}+z_{\alpha / 2} \cdot \frac{\sigma}{\sqrt{n}}\right)}$$。换句话说就是,\(\mu\) 落在这个区间里面的概率是 \(1-\alpha\)。
如果总体标准差 \(\sigma\) 未知,且样本较大,可以用样本标准差 \(s\) 代替。
如果总体标准差 \(\sigma\) 未知,且样本不够大(\(n<30\)),用样本标准差 \(s\) 代替之后,还要把正态分布 \(z\) 换成 \(t\):$$\left(\bar{X}-t_{\alpha / 2} \cdot \frac{s}{\sqrt{n}}, \bar{X}+t_{\alpha / 2} \cdot \frac{s}{\sqrt{n}}\right)$$。
极大似然估计 maximum likelihood estimate
只要出现了,极大似然估计就认为,这个出现的概率很高。
从简单例子开始:抛硬币
假如有一个硬币(不一定均匀),抛出四次,三次正面朝上。设单次正面朝上的概率是 \(p\)。
根据伯努利分布,三次正面朝上的概率是 \(4p^3(1-p)^1\),把这个函数的图像画出来
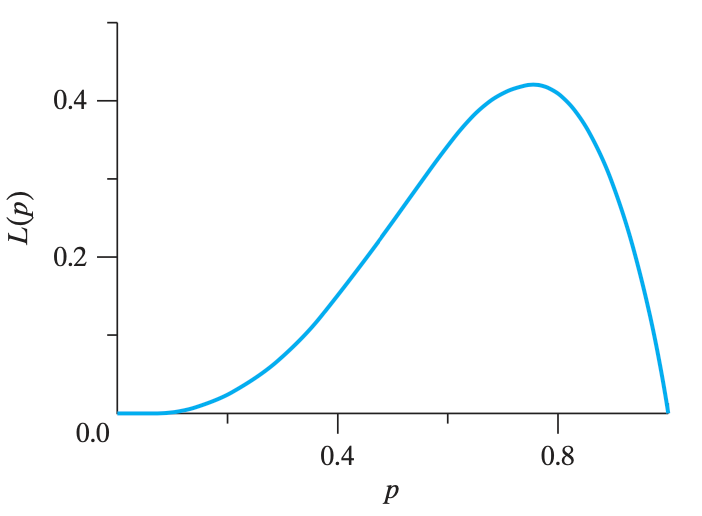
极大似然估计就是,找出这个函数图像最大值(求导之后就知道最大值是多少了)。最大值对应的点,就是估计的 \(p\) 的值(在本题中,\(\hat p=0.75\))
更一般的情况
有一个跟参数 \(\theta\) 相关的概率密度函数 \(f(x;\theta)\),(\(\theta\) 就像是刚刚例子里面的 \(p\))。
把 \(X_i\) 分别代入 \(x_i\),用函数 \(f\) 再构造一个极大似然函数 \(L\):$$L\left(\theta \mid x_1, \cdots, x_n\right)=\prod_{i=1}^n f\left(x_i ; \theta\right)$$,极大似然估计就是指,找到一个 \(\theta\) 的取值,让这个函数 \(L\) (一堆 \(f\) 的乘积)取得极大值。
没太懂。会做题就行
例子:再抛一次硬币
进行了 \(n\) 次抛硬币,每次都是 \(p\) 的概率正面朝上。第 \(i\) 次是否朝上,用随机变量 \(X_i\) 表示:$$P\left[X_i=0\right]=1-p, \quad P\left[X_i=1\right]=p$$,然后左右两个式子合起来,变成了 $$P(X_i=a)=pa(1-p)$$,代入极大似然函数 \(L\),得到 $$L(p\mid x_1,\cdots,x_n)=p{x_1+x_2+\cdots+x_n}\times(1-p)$$,现在就是要找到一个 \(\hat p\),使 \(L\) 取到最大值。由于有幂次,这个函数 取对数之后再求导 比较好算。令取对数后的导数等于零:$$\frac{x_1+\cdots+x_n}{p}-\frac{n-(x_1+\cdots+x_n)}{1-p}=0$$,最终能得到 \(\hat p = \frac{x_1+\cdots+x_n}{n}\) 使函数 \(L\) 最大。
- Note 1: 这里极大似然估计的对象是 \(p\),而不是 \(x\)
- Note 2: 巧合的是,课件上给出的例题(7.8~7.13)几乎算出来答案都是 \(\frac{x_1+\cdots+x_n}{n}\)
二级结论
- 对于正态分布,\(\hat\mu = \frac{1}{n}(x_1+x_1+\cdots+x_n)\),\(\hat\sigma^2 = \frac{1}{n}\sum_{i=1}^n(x_i-\mu)^2\),具体的推导过程可以看例子 7.10 和例子 7.11
- 若 \(\hat\theta\) 是 \(\theta\) 的极大似然估计,有一个 one-to-one 的函数 \(g\),而那么 \(g(\hat\theta)\) 就是 \(g(\theta)\) 的极大似然估计
假设检验
- 第一类错误,就是原本假设是对的,但拒绝了(主要讨论这一类)
- 第二类错误,就是原本假设是错的,但没拒绝(牵涉真实值,反正比较复杂,参考课件 24 页的图)
发生第一类错误的概率,也叫做 显著性水平(level of significance),通常 \(\alpha=0.05\) 或 \(\alpha=0.01\),看题目指定。
两类错误是跷跷板的关系,一类的概率大,另一类概率就会小。
假设检验步骤
- 确定好原假设和备选假设
- 说明显著性水平
- 基于样本的分布,构造一个关于原假设和备选假设的判别
- 计算出决策所依据的统计量的值
- 决定是否拒绝假设
注意,原假设不能用「接受」这个词,而应该说「不能拒绝」
原假设 null hypothesis
- 用 \(H_0\) 表示
- 还有个叫做 备选假设 alternative hypothesis 的东西,总是与原假设成对出现
- 一旦原假设被拒绝,就认为备选假设成立
- 备选假设有两种,单边假设(one-sided)与双边假设(two-sided)
- 单边就是大于或小于
- 双边就是不等于
对于原假设 \(\mu = \mu_0\) 以及 \(Z = \frac{\mu-\mu_0}{\frac{\sigma}{\sqrt{n}}}\),可以得出这样一个表格:
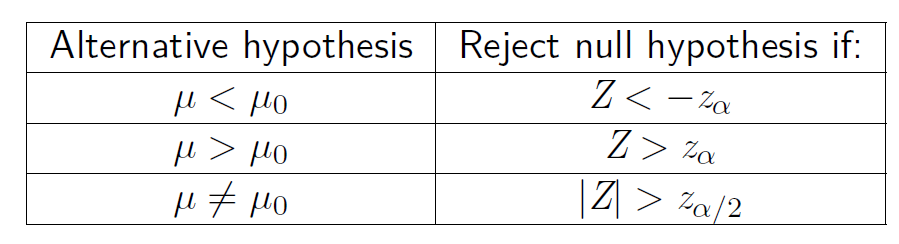
结合例子比较好理解
选取原假设的 guidelines
若一个实验的目标,是建立一个断言,那么原假设应该选取为,断言的否定;备选假设应该是该断言。
P 值
P 值(P value)就是 当原假设为真时,比所得到的样本观察结果更极端的结果出现的概率。说白了就是分位点后面的面积呗。
注意看清楚是单边假设还是双边假设。
用处:\(P \leq \alpha\) 则拒绝原假设,否则不拒绝原假设。
例题 7.16
首先算出来 \(Z = \frac{\bar x - 71}{(s / \sqrt{80}} = -2.38\),这是必须步骤
法一
根据显著性水平算出来那个边界 -2.326(=NORM.S.INV(0.01)),然后 Z 比这个边界更小,所以拒绝原假设
法二
计算 P-value,算出来 P 值约为 0.0086(norm.s.dist(-2.38, true)),小于显著性水平 0.01,所以拒绝原假设
Chapter 8 比较两个对象
-
treatment:处理组
-
experimental unit:实验单元
-
response:响应
-
例子 8.1,专家组,新手组,独立样本设计(independent sample design),在课本 266 页
-
还有例子二,土木工程师,研究车道油漆耐用性的
考虑:
- 独立样本
- 配对的样本
关于独立的大样本的假设
若:
- 样本 \(X_1, X_2, \cdots, X_n\) 来自均值、方差分别为 \(\mu_1, \sigma_1^2\) 的一号总体
- 样本 \(Y_1, Y_2, \cdots, Y_n\) 来自均值、方差分别为 \(\mu_2, \sigma_2^2\) 的二号总体
- 两个样本都是大样本(\(n_1\geq 30\),\(n_2\geq 30\))且相互独立
则两个样本的均值的差值,服从正态分布。形式化的说就是: $$\boxed{Z = \frac{\overline X - \overline Y - \delta}{\sqrt{\frac{S_12}{n_1}+\frac{S_22}{n_2}}}}$$,\(Z \sim N(0, 1)\),因为 \(\overline X - \overline Y \sim N(\mu_1-\mu_2, \frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2})\),其中用 \(\delta\) 表示两个样本均值的差值(\(\delta = \mu_1-\mu_2\))。反正对于大样本,已知 \(\sigma\) 就用 \(\sigma\),不然就用 \(S\) 代替。
跟第七章类似。样本均值的差的 \((1-\alpha)100\%\) 置信区间是:$$\boxed{(\bar x - \bar y) \pm z_{\alpha/2}\sqrt{\frac{S_1^2}{n_1} + \frac{S_2^2}{n_2}}}$$。
对于原假设 \(H_0: \mu_1-\mu_2 = \delta_0\),\(Z\) 是刚才上面那一坨,表格如下(其实跟第七章的基本一样)
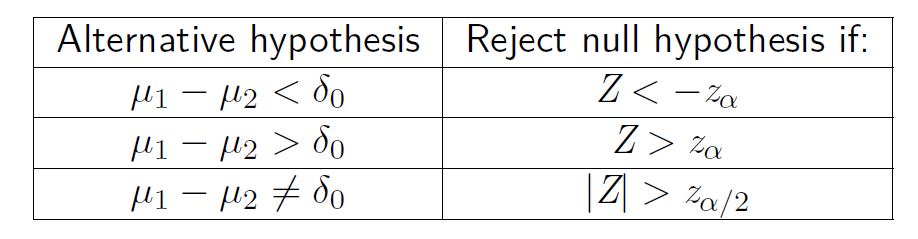
关于独立的小样本(等方差)的假设
注意,对于小样本的题目,必须满足总体服从正态分布才可做!但是对于大样本,就没有这个限制。因为 大样本小样本的区别就在于中心极限定理。大样本无论什么总体分布可以用正态分布,小样本只有总体服从正态分布的时候才能用正态分布,否则用 t 分布。
对于大样本来说,如果方差未知,直接用样本标准差代替就好了;但是对于小样本来说,不能直接用标准差代替。
对于两组小样本方差相差不大的情况,可以池化(pool),就是两组扭起来,以此来估算总体方差 \(\sigma^2\):$$S_p2=\frac{\sum_{i=1}\left(X_i-\bar{X}\right)2+\sum_{i=1}\left(Y_i-\bar{Y}\right)^2}{n_1+n_2-2}= \boxed{\frac{\left(n_1-1\right) S_1^2+\left(n_2-1\right) S_2^2}{n_1+n_2-2}}$$,这个东西 $$t=\frac{\bar{X}-\bar{Y}-\delta}{S_p \sqrt{\frac{1}{n_1}+\frac{1}{n_2}}}$$ 服从 t 分布,自由度是 \(\boxed{n_1+n_2-2}\).
\((1-\alpha)100\%\) 的置信区间是 $$(\bar{x}-\bar{y}) \pm t_{\alpha / 2} \cdot S_p \sqrt{\frac{1}{n_1}+\frac{1}{n_2}}$$,还是移项算出来的,其中 t 的自由度是 \(n_1+n_2-2\).
小样本,不等方差
t 发生了变化$$t{\prime}=\frac{\bar{X}-\bar{Y}-\delta}{\sqrt{\frac{S_12}{n_1}+\frac{S_2^2}{n_2}}}$$,自由度也不再是整数,而是 $$\frac{\left(\frac{S_12}{n_1}+\frac{S_22}{n_2}\right)2}{\frac{\left(S_12 / n_1\right)2}{n_1-1}+\frac{\left(S_22 / n_2\right)^2}{n_2-1}}$$。这个方法是比较近似的,不是精确解,名叫 Smith-Satterthwaite test.
\((1-\alpha)100\%\) 的置信区间是 $$(\bar{x}-\bar{y}) \pm t_{\alpha / 2} \cdot \sqrt{\frac{S_12}{n_1}+\frac{S_22}{n_2}}$$。
算这个实在太麻烦了,所以说,在实际应用当中,如果方差相差不大(三倍以内),一般就当作等方差了。
配对比较
刚才是不配对的,现在研究一下配对的(很简单)。配对意思就是 \(X_i\) 与 \(Y_i\) 一一对应了。定义 \(D_i = X_i - Y_i\),所以本质上就变成一个变量的问题了。
Chapter 9 方差
关于小样本的一点额外知识
考试不会考,了解即可
样本方差 \(S^2\) 是总体方差 \(\sigma^2\) 的无偏估计,但是标准差不无偏。
结论:正态分布的总体,样本的极差 \(R\)(range)的分布的均值是方差的某个倍数即 \(d_2\sigma\),标准差也是方差的某个倍数即 \(d_3\sigma\)。于是,\(R/d_2\) 就是 \(\sigma\) 的无偏估计。样本很小的时候,用 \(s\) 代替 \(\sigma\) 不如用 \(R/d_2\) 代替 \(\sigma\)。样本大的时候,用 \(s\) 更好。

关于卡方分布的方差
方差的置信区间
根据第六章的知识点,\(\frac{(n-1) S^2}{\sigma^2}\) 是服从卡方分布的。所以方差的置信区间应当是 $$\boxed{\frac{(n-1) S^2}{\chi_{\alpha / 2}2}<\sigma2<\frac{(n-1) S^2}{\chi_{1-\alpha / 2}^2}}$$。注意卡方分布的图像不是对称的!所以左右两边 \(\frac{\alpha}{2}\) 的位置也不一样。所以在上述式子当中,用到了俩,式子左边是 \(\chi_{\alpha / 2}^2\),右边是 \(\chi_{1-\alpha / 2}^2\);标准差的区间就是开个根号。
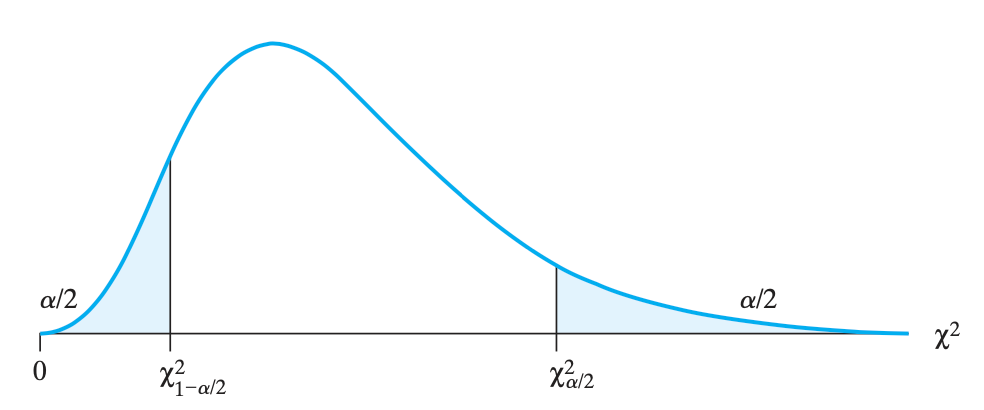
图的左边是 \(\chi^2_{1-\alpha/2}\),右边是 \(\chi^2_{\alpha/2}\),跟式子反过来了。反过来是因为推导区间的时候涉及到了减法和移项。
比较 \(\sigma\) 跟某个值 \(\sigma_0\) 的大小关系
因为不是对称的,所以这个表格不太好记忆。据说考试的时候是不要求记忆的,会给。
原假设是 \(\sigma^2 = \sigma_0^2\),\(\sigma_0\) 是题目给出来,让检验的,\(\sigma\) 是真实的方差。真实的方差会影响到样本的 \(S\)。
这个表格其实跟前面的也基本一样,也是前两个单边的用 \(\alpha\) 第三个双边用 \(\alpha/2\),且其中 $$\boxed{\chi^2 = \frac{(n-1)S2}{\sigma_02}}$$:

关于 F 分布的方差
比较两个总体方差的大小关系
这里要使用 F 分布的知识:\(F = \frac{S_1^2}{S_2^2}\),回顾一下,F 分布实质上就是卡方分布除以各自的自由度。如果两个总体的方差相等,那么 F 分布的表达式就可以化简成这种简单的形式。如果方差不相等,那就是 \(F=\frac{S_1^2 / \sigma_1^2}{S_2^2 / \sigma_2^2}\)。所以这里为了让式子简单一些,三行表格的原假设全都是 \(\sigma_1^2 = \sigma_2^2\).
注意为了方便计算和查表,要让 \(F > 1\),也就是分子用大的,分母用小的。这个表格其实跟前面的也基本一样,也是前两个是单边用 \(\alpha\) 第三个是双边用 \(\alpha/2\)。
跟前面的不同点在于,第三行只有一个条件而不是两个。可以这样理解:因为 F 分布本身的表达式就已经涉及到俩了。

两个总体方差的比值的置信区间
两个总体方差不相等的时候,F 分布表达式稍微复杂:\(F=\frac{S_1^2 / \sigma_1^2}{S_2^2 / \sigma_2^2}\),\((1-\alpha)100\%\) 的置信区间是 $$\frac{\sigma_22}{\sigma_12} \in \boxed{\left(F_{1-\alpha / 2}\left(n_1-1, n_2-1\right) \frac{s_22}{s_12}, \quad F_{\alpha / 2}\left(n_1-1, n_2-1\right) \frac{s_22}{s_12}\right)}$$。看起来很难记忆,所以需要知道怎么推的:
(课件例子 9.6)
Chapter 10 比例
这一节跟二项分布是啥关系
- 总体的比例记作 \(p\)
- \(X\) 表示 \(n\) 次实验里面事件发生的次数
- \(\hat p = \frac{X}{n}\) 是样本比例估计量
- 估计的标准差是 \(\frac{1}{n^2} Var(X)\) 也就是 \(\sqrt{\frac{\hat p(1 - \hat p)}{n}}\)
例子 10.1
比例的置信区间
小样本,保守区间
关于比例 \(p\) 的保守的置信区间,看一眼课件第五六页就能懂了,不太好用语言概括。
大样本,用正态分布近似
对于大样本(\(np > 15\) 且 \(n(1-p)>15\))来说,由于 \(\hat p \sim N\left(p, \frac{p(1-p)}{n}\right)\),所以 \(p\) 的 \((1-\alpha)100\%\) 的置信区间是 $$\frac{x}{n}-z_{\alpha / 2} \sqrt{\frac{\frac{x}{n}\left(1-\frac{x}{n}\right)}{n}}<p<\frac{x}{n}+z_{\alpha / 2} \sqrt{\frac{\frac{x}{n}\left(1-\frac{x}{n}\right)}{n}}$$,===??为啥是这跟正态分布,\(\mu\) 不应该是 \(np\) 吗)
二级结论
最大估计误差是 $$E=z_{\alpha / 2} \sqrt{\frac{p(1-p)}{n}}$$,这又是咋出来的,然后根据这个公式可以再求出来一个 \(n\) 的范围:$$n=p(1-p)\left(\frac{z_{\alpha / 2}}{E}\right)^2$$,若 \(p\) 未知,取最大值,其中 \(\frac{1}{4}\) 是 \(p(1-p)\) 的最大值:$$n=\frac{1}{4}\left(\frac{z_{\alpha / 2}}{E}\right)^2$$
比例的假设检验
检验 \(p=p_0\)
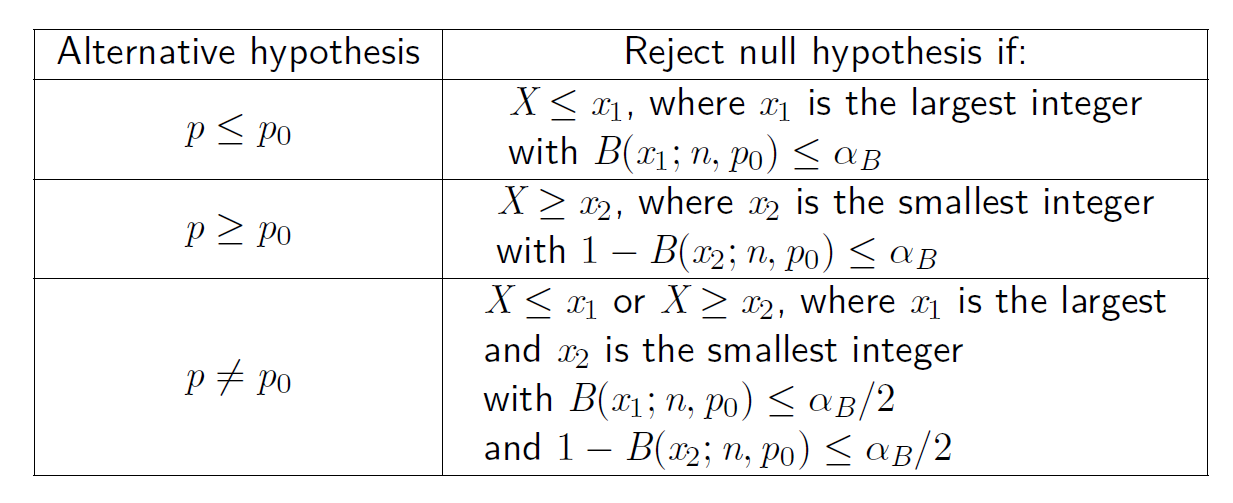
Chapter 11 回归问题
附:公式汇总
后面的例题,用表格查一遍重做一下,不要依赖 excel
期望与方差
注意,“方差”不等于“样本方差”
全概率公式
贝叶斯公式
泊松分布
可近似二项分布
\(\mu=\sigma^2=\lambda\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号