
关于C语言中函数调用和参数传递机制的探讨——汇编语言分析
关于C语言中函数调用和参数传递机制的探讨
一、基本知识框架了解:
这部分主要讲一些基本的东西,主要是关于堆栈的知识。只有了解了堆栈的基础内容,才可以继续往下读。
1.概念性的知识:
所谓堆栈,其实也就是程序使用的一种内存元素;它是内存中用来存放一些数据的区域。平常经常说的堆栈,其实也是栈,而不是堆,所以这里也一样。注意这和数据结构说的栈其实还是有区别的,不要混在一起。
2.堆栈的工作方式:
平常我们所说的数据是怎么存放在内存的?是从低地址开始,然后按照数据占用字节大小往高地址逐个存放的。但堆栈就不一样了。堆栈的工作方式是数据插入堆栈区域然后从堆栈区域删除数据。这是概括的说法。具体是这样的:
在UNIX/LINUX
中,堆栈是从高地址向低地址衍生的。这里得说一个重要的东东,那就是堆栈指针ESP。堆栈指针是什么?它永远指向堆栈中的顶部(但如果按照地址值来说却是
底部),是不是对顶部这个词的理解感觉有点模糊?就是说,比如说你压栈,就压进一个4字节的数据元素,那么ESP就向下移动了4个字节,注意这里是向下移
动,所以ESP应该指向了更低的地址,所以说它是指向了底部。你可以把堆栈想象成一个杯子,倒进水了水平线是不是上升了(这里把杯子最底端假设成高地址,
把顶端设为低地址),倒出水了水平线是不是下降了?就和压栈和进栈的道理一样的。
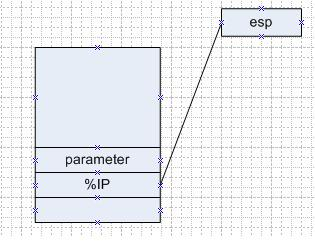 3.压栈和进栈指令简介:
3.压栈和进栈指令简介:
压栈指令 : pushx source
其中, 'x'可以是 'w'(表示字), 或者是'l'(表示长字);source可以是数值或者寄存器值或者内存地址;
出栈指令 : popx des
同样,'x'可以是 'w'(表示字), 或者是'l'(表示长字);des可以是寄存器值或内存值;
二、函数如何通过堆栈来解决问题:
这部分是对函数如何通过堆栈解决函数调用以及参数传递的理论性理解,相当重要,只有了解之后才可以进行实例的分析,这一大部分同样分成几个小部分:
1.通过堆栈操作实现参数的传递:
前面说过,堆栈的基本操作可以是压栈和出栈,而参数的传递就是通过这种方式来实现的。ESP永远指向了堆栈顶部,如果这时候压进一个int型的数据元
素,那么ESP向下移动了4个字节,这时候它还是指向了堆栈的顶部。假如把一个int型数据元素出栈,
那么ESP向上移动4个字节,这时候它还是指向了堆栈的顶部,只是现在地址是增加了4个字节。所以,如果一个函数需要传递参数过去那么就得在调用函数之前
先把参数压进栈,然后再调用。关于这点后面我会详细说一下,现在你如果没理解也没关系。

2.函数调用的一般汇编指令:
函数调用的一般汇编指令都是那么几条,下面我把他们按一般顺序罗列出来:
#Asm Code 1 function: 2 pushl %ebp 3 movl %esp, %ebp 4 subl $8, %esp 5 #... 6 movl %ebp, %esp 7 popl %ebp 8 ret
pushl %ebp
把寄存器%ebp压栈,目的是什么呢?看下一条指令。
movl %esp, %ebp
把寄存器%esp的值给了寄存器%ebp;想想前面说到的%esp寄存器是干什么的?用于指向堆栈的顶部,现在通过这条指令,%ebp都是指向 了堆栈 的顶部了;所以这两条指令就是:为了保护原来在%ebp寄存器中的内容。
那么这里为什么又要把%esp的值赋给%ebp呢?这里的巧妙就来了。在
函数的处理过程中,可能一些数据会被压进栈,那么这时候就会破坏栈里面原有的内容了,如果栈的内容被破坏了,指向栈顶的指针%esp指向的地址不准确了,那么到时候要清栈(之后会说明)就会发生更多的意外问题了。所以第二条指令是为了保证有一个寄存器永远指向了栈顶而不必担心会出现刚才所说的问题。现在是寄存器%ebp永远指向栈顶了,而%esp可以移动而不必害怕数据会被破坏了。
subl $8, %esp
看这条指令,为什么无故要把%esp的值减去8呢?也就是说%esp向下移动8个字节,而这8个字节的空间到底用来干什么呢?这8个字节空间其实是为
临时变量留出来的。注意,它会根据临时变量占用的字节大小而留出不同的空间大小,所以不一定是8个字节,可能是24或者36甚至更大的空间;不过临时变量
太多不是好事情,这点注意。
movl %ebp, %esp
这条指令把%ebp复制到%esp了,理由是什么?让%esp重新指向栈顶,这样就可以方便函数调用完毕后的清栈了。
ret
函数调用完毕的返回指令,这句指令其实同时把函数调用刚刚开始压进的IP地址弹出栈。在下面会有详细分析。
三、函数调用和参数传递机制的实例分析
这是本文的实战分析部分了,通过例子来加深一下理解。我会先列出C代码出来,然后列出反汇编的汇编代码,结合C代码来分析汇编代码。我会尽可能对各种类型的函数调用或参数类型作一个分析,可能会显得比较累赘一点,不介意吧?
1. 函数原型:void function(void);
1 // C code 2 void function(void){ 3 return; 4 } 5 int main(void){ 6 function(); 7 return 0; 8 }
反汇编一下看看汇编代码,下面是Linux 下的gcc反汇编后的代码(注意:是在我的机子上的反汇编代码):
1 function: 2 pushl %ebp 3 movl %esp, %ebp 4 popl %ebp 5 ret
看看,因为函数function什么也没有做,所以直接就返回了,上面的指令和第2部分的代码基本上一样,甚至更简单,参照一下前面的分析。
下面看看main函数的反汇编代码了,相对来说复杂一点,看好了:
1 main: 2 pushl %ebp 3 movl %esp, %ebp 4 subl $8, %esp 5 andl $-16, %esp 6 movl $0, %eax 7 addl $15, %eax 8 addl $15, %eax 9 shrl $4, %eax 10 sall $4, %eax 11 subl %eax, %esp 12 call function #函数调用指令 13 movl $0, %eax 14 leave 15 ret
看看函数调用指令 : call function,前面居然还有那么多据指令,那些指令到底干什么用?我一句一句分析吧。
pushl %ebp movl %esp, %ebp subl $8, %esp
这三句不分析,和前面第2部分的一样,忘记的回头看一下,其实这也反映了一件事:其实main函数也很普通,它跟其他函数其实差不多,只是地位稍微高一点而已。
andl $-16, %esp
这句可能吓倒一些人了。andl 是逻辑与指令,而-16其实补码形式是0xfffffff0。为什么要把%esp的值和-16进行逻辑与运算呢?这条指令其实是为了强制让%esp的值是16的倍数。为什么要16的倍数?这里必须懂得一个常识:Linux下的编译器GCC默认的堆栈是16字节对齐的,可能有些人要问为什么要对齐,对齐其实为了加快CPU的访问效率,这里你记住这点就可以了。
1 movl $0, %eax 2 addl $15, %eax 3 addl $15, %eax 4 shrl $4, %eax #逻辑右移,将一个寄存器或内存单元中的数据向左移位;将最后移出的一位写入CF中; 最低位用0补充 5 sall $4, %eax #逻辑左移 6 subl %eax, %esp
看到这几句,又有更多人可能被吓到了,干嘛对%eax寄存器进行那么多的操作啊?的确,我也觉得没什么多大的必要,因为仔细看看这几条指令无非就是为了让%eax的值是0而已。
1-3行: %eax = 0,经过两次addl之后,%eax的值变成30了,30其实就是0x11110。
4-5行:保证%eax最低5位的值全部为0。注意,这只是在我的机子上的反汇编指令,不同机器对此处理可能不一样,但有一点是一样的:%eax的值是0。
6行:%esp值减去%eax值后把结果送到%esp,所以经过这条指令后%esp值仍然是16的倍数,这就是保证%eax值是16的倍数的原因了。
call function movl $0, %eax
这个简单了,调用函数function,最后又把%eax寄存器的值清0,结束整个main函数了。
这就是最简单的函数调用分析了,没有涉及到参数的传递,所以非常简单,下面就要开始讲到参数的传递了,事实上有了这个例子的分析,下面就不太难了。
2.函数原型: int function(int i)
现在有了参数了,也有了返回值了,相对来说更比较复杂了。这里就得引入%esp寄存器值的变化了,不然就难以把问题分析清楚了,如果想形象一点地描述那就画图,自己画个图根据我的数据变化一起分析吧。看看一段简单的C代码:
1 // C Code 2 int function(int i){ 3 return 2 * i; 4 } 5 int main(void){ 6 int j = function(10); 7 return 0; 8 }
之所以些这么简单只是为了我们分析问题的方便,懂得个原理就算是复杂的其实稍微再分析一下也就懂了。我们从main开始分析。
1 main: 2 pushl %ebp 3 movl %esp, %ebp 4 subl $24, %esp #* 5 andl $-16, %esp 6 movl $0, %eax 7 addl $15, %eax 8 addl $15, %eax 9 shrl $4, %eax 10 sall $4, %eax 11 subl %eax, %esp #到这里其实和前面的例子基本一样,就不分析了 12 movl $10, (%esp) 13 call function 14 movl %eax, -4(%ebp) 15 movl $0, %eax 16 leave 17 ret
看看上面的汇编代码,和前面一样的不分析。但是其中有句不一样:subl $24, %esp ; 因为主函数里有两个临时变量i, j;这里为了有足够的空间留给临时变量所以干脆在堆栈里腾出24个字节空间。在看看下面的代码:
movl $10, (%esp)
%esp = 800, (800) = 10 ,其中800是我们假设的地址值,(800)表示地址800的内容这里的(%esp)指的是%esp地址里的内容, 刚才我们假设这时候%esp的值是800, 那么地址为800里的内容就是10了。
call function
在调用函数前其实是先把函数调用指令call之后的地址压栈,也就是call之后那条指令的IP值压栈,所以这时候 %esp = 796;这里要弄明白为什么要把下条指令地址压栈,假设如果不把IP值压栈,那么当函数调用完毕后怎么能找到函数调用时的地址呢?也就是说如果没把IP压 栈,那么函数调用完之后就回不到原来的执行地址了,就会造成程序执行顺序的错误!
下面列出函数function的汇编代码:
1 function: 2 pushl %ebp 3 movl %esp, %ebp 4 movl 8(%ebp), %eax 5 addl %eax, %eax 6 popl %ebp 7 ret
pushl %ebp
经过这条指令后 %esp值减4,所以这时候%esp值是792。
movl %esp, %ebp
%ebp = 792, %esp = 792, (792) = %ebp ;其中(792)表示地址792中的内容
movl 8(%ebp), %eax #%eax = 10
上面这句很多人可能不明白了,8(%ebp)指的是什么?8(%ebp)等于 : (%ebp + 8) ,这里注意,%ebp + 8
是表示一个地址值,加上括号表示存储在该地址上的内容。
所以8(%ebp)其实就是地址为800的值,看前面地址800的值刚好是10!所以这句其实是把10复制给%eax寄存器.
addl %eax, %eax # %eax = 20
相当于2 * %eax, %eax这时候等于20了,刚好是实现了C代码中的 (2 * i);
popl %ebp
恢复%ebp寄存器的值, %esp这时候等于796
ret
函数调用完毕返回,这句其实是把刚才压栈的IP值弹出栈,执行这条指令后 %esp = 800,我们在调用函数的时候%esp也是800啊!这就是实现了“清栈”了,就是把调用函数所在的栈清除了!
好了,函数 function的汇编代码分析完了,现在回头继续看看main函数里的下一条指令了。接下来是这句:
movl %eax, -4(%ebp)
%eax寄存器存放的是什么?看function函数的代码,可以知道其实就是(2 * i)的值,所以返回值其实是通过%eax来传递的!传递到-4(%ebp)里去了,-4(%ebp) = (%ebp - 4); -4(%ebp)到底是什么呢?看看C代码,返回值传给变量j,那么-4(%ebp)会不会就是j呢?答案是肯定的!我们先看看%ebp的值是什么。看看 main函数的汇编代码,可以得出,%ebp其实指向了main函数的栈底部,但记不记得前面说的subl $24, %esp是为临时变量而留出的空间?没错,-4(%ebp) 就是存储在临时变量区域!也就是变量 j 了。
3. 函数原型:int function(int i, int j)
现在参数是两个,不是一个了,两个到底该怎么处理呢?同样看C程序和相应的汇编代码:
1 // C code 2 int function(int i, int j){ 3 return (i + j); 4 } 5 int main(void){ 6 function(1, 2); 7 }
下面列出主要的汇编代码,没有全部列出来,因为一些和前面一样的代码已经分析过,不再罗嗦了。
1 main: 2 # ... ... 3 movl $2, 4(%esp) 4 movl $1, (%esp) 5 call function
看到没有?先把2送进栈里,再把1压栈,我们看看函数调用的C代码:function(1, 2); 2在右边,而1在左边,所以,当存在多参数的时候参数压栈其实是按从右向左的顺序压栈的。当参数都压栈后,就调用函数了。
1 function: 2 pushl %ebp 3 movl %esp, %ebp 4 movl 12(%ebp), %eax 5 addl 8(%ebp), %eax 6 popl %ebp 7 ret
看函数的汇编代码:movl 12(%ebp), %eax ; 知道12是哪里来的吗?自己画图看看,结合前面的分析!一调用函数先压IP进栈,再压%ebp进栈,那么%esp值就被减去8了,再把%esp值复制到%ebp,就是这样而已!
4.函数原型:char *function(char *s);
作为字符串函数其实道理也差不多,而且我觉得反而更简单,怎么个简单法,看代码吧:
// C code char *function(char *s){ return s; } int main(void){ char *p = function("abcd"); }
列出并简单分析一下汇编代码:
1 main: 2 # ... ... 3 movl $.LC0, (%esp) #.LC0:.string "abcd" 4 call function
.LC0只是一个标志,就是字符串"abcd";所以说白了其实非常简单。movl $.LC0, (%esp) ;就是把字符串送到地址为%esp的空间里。
下面看调用的函数的汇编代码了:
1 function: 2 #... ... 3 movl 8(%ebp), %eax 4 #.. ...
8(%ebp)其实就是字符串了,依然建议你们自己画图看看,只要图一画,自然变得十分清晰。
5.函数原型:struct text function(int n);
现在函数返回值类型换成是结构体了,差别就来了,不过其实道理还是那个样,本质的东西还是一样的。
1 //C code 2 struct text { 3 int a; 4 }; 5 struct text function(int n){ 6 struct text s; 7 s.a = n; 8 return s; 9 } 10 int main(void){ 11 struct text t = function(10); 12 return 0; 13 }
这里举的例子都非常简单,我们的目的只是为了分析不同函数调用和参数传递方式是怎样进行的。看汇编代码:
1 main: 2 # ... ... 3 leal -20(%ebp), %eax 4 movl $10, 4(%esp) 5 movl %eax, (%esp) 6 call function
到这个例子就只分析最重要的指令了,其他的大家可以尝试分析看看。在main函数开头,我的机子上GCC居然留出了40个字节给临时结构体变量!
开头有这句:subl $40, %esp;我也不知道为什么留这么大的空间。但这些数据我们先不管了,毕竟不是最重要的。
leal -20(%ebp), %eax
看看上面这句,这条指令非常重要。把(%ebp - 20)的地址复制给%eax,%eax 的值其实是结构体中成员的地址。
下面是function函数的汇编代码:
1 function: 2 pushl %ebp 3 movl %esp, %ebp 4 subl $16, %esp 5 movl 8(%ebp), %eax 6 movl 12(%ebp), %edx 7 movl %edx, -4(%ebp) 8 movl -4(%ebp), %edx 9 movl %edx, (%eax)
subl $16, %esp
为函数中临时结构体变量保留空间。
5. 其他说明
其实还有很多的类型都没讲,其中就有返回值为浮点数或者参数是浮点数,浮点数不讲了,因为这就比较复杂了,为了支持浮点数以及其他
功能(比如说数学运算功能)就需要附加的指令和寄存器了,这些东西全部结合就称作“浮点单元”(Floating-point unit ---> FPU)。浮点数以及运算有自己的指令和寄存器,这些东西说起来就得一篇文章了。
递归就不也用讲了,道理和前面一样,只是重复调用自己而已,就按照栈的顺序衍生过去而已,然后最后一层层清栈了。
另外还有可变参数函数,其实有了上面的基础来分析可变参数函数挺简单的,入栈顺序还是那样从右向左,只是你需要了解一下可变参数函数的内部到底怎么实现的,这里存在很强的技巧性,有兴趣的朋友可以去看看在头文件<stdarg.h>里面关于可变参数的几个宏,技巧性超强!
四、参考文献:
《Professional Assembly Language》 Author:Richard Blum(US)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号