Runtime Data Area

下一条该执行的指令 存放在PC(程序计数器)
虚拟机的运行 类似这样的循环
while(not end){
取pc中的位置 找到对应的指令
执行该指令
pc++
}
每一个线程都有自己的PC 计数器

栈在虚拟机中有两块内容 一个是JVM stacks
jvm stacks 归线程独有的 线程里面装的是栈帧
每个线程对应的栈 每个方法对应一个栈帧

栈在虚拟机中有两块内容 一个是JVM native method stacks
调用本地c和c++的 无法调优

直接内存 NIO 为了增加IO效率
jvm 内部可以直接访问操作系统管理的内存 用户空间可以直接访问系统内存
网络传过来一个数据 这个数据首先放在内核空间里 jvm 在用的时候 需要从内核拷贝到jvm 空间 如果数据多了 那么效率较低
NIO 使用直接内存 可以直接访问JVM 就不需要拷贝 直接访问内核空间内容 zero Copy 零拷贝

方法区 里面放各种各样class 还包含了常量池中的内容

常量池 在内存运行的时候 放在 运行时常量池中

共享所有jvm 的线程
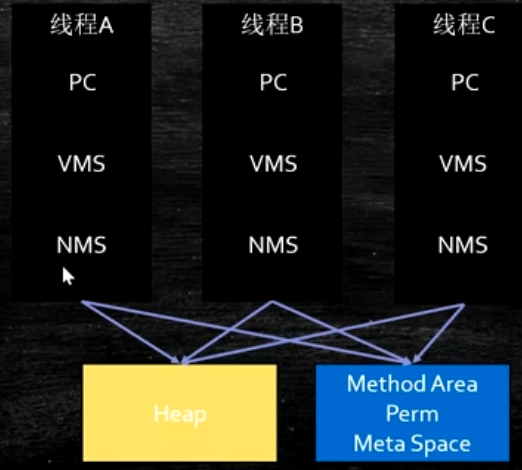
每一个线程 都有自己的PC 计数器 都有自己的jvm stacks 里面装的都是栈帧 还有自己的nativeMethods stack 但是他们共享的是堆heap 以及 Method Area 方法区 1.8之前permSpace 1,8之后叫Meta Space 1为什么要拥有自己的PC PC 不能共享吗? 为了实现线程之间的来回切换 2 jvm stacks 里面装的都是栈帧,那栈帧里面装的是什么? Frame-每个方法对应一个栈帧 包含下面4项 1 local variables 局部变量表 2 operand Stacks 操作树栈 3 dynamic Linking 动态链接 4 return address 返回值地址
1 local variables 局部变量表
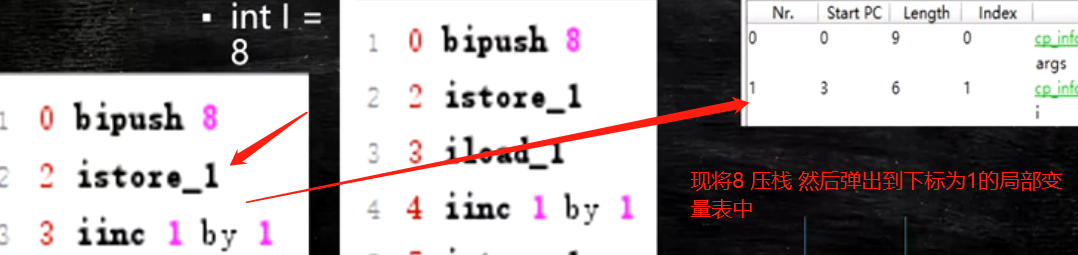
根据bipush_8 的描述会将8 byte 类型扩展为 ing 类型 将8放入栈中 压栈 int i=8
istore_1 出栈 将这个值存储到局部变量表下标为1里面
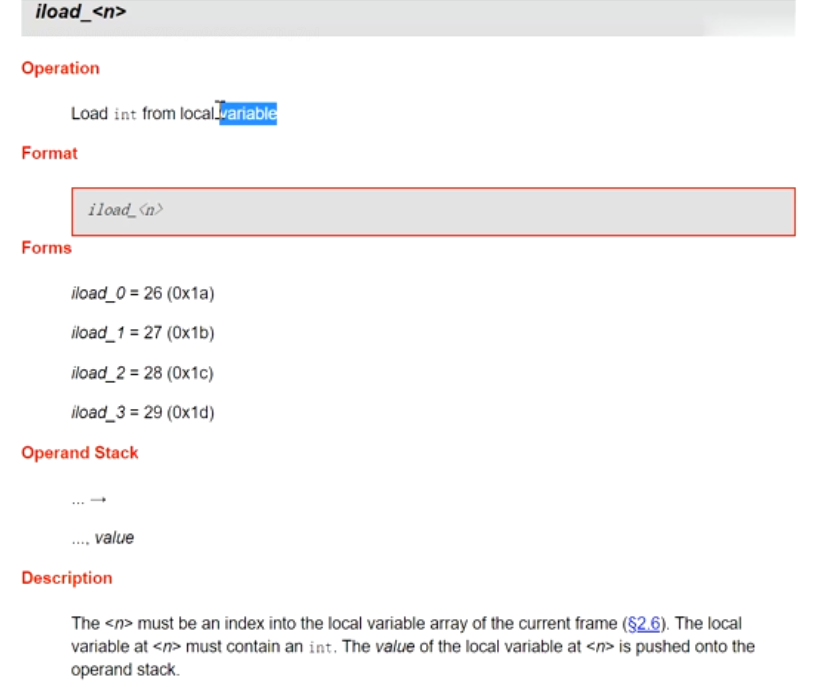
iload_1 从局部变量表中拿出来 压到栈中 i++
iinc 1 by 1 将局部变量表中的8 加1 变成9 但是栈中还是8
istore 出栈 将栈中的值赋值给局部变量表 由9 变成 8
return 8
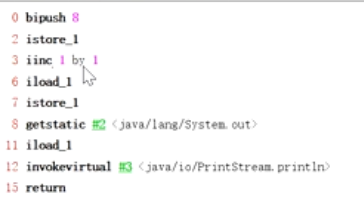
根据bipush_8 的描述会将8 byte 类型扩展为 ing 类型 将8放入栈中 压栈 int i=8
istore_1 出栈 将8存入局部变量表中
iinc 1 by 1 将局部变量表中的8 加1 变成9
iload_1 从局部变量表中拿出来 压到栈中 栈中i=9
istor_1 出栈 将9 放到局部变量表中
return 9
2 operand Stacks 操作树栈
3 dynamic Linking 动态链接 一个线程有自己的线程栈 每个线程栈里面装的是一个一个栈帧 每个栈帧里面有一个操作树栈 还有一个叫 动态链接 动态链接 指到我们运行时常量池 里面的符号链接(编译字节码的时候 有该符号链接 那时只是字节码 )
看符号链接是否有解析 如果没有解析 就进行动态解析 如果解析了就直接拿过来直接使用
4 return address 返回值地址 a 方法调用b 方法 b方法执行完了之后 如果有返回值,返回值放哪里以及b 方法 执行结束了 应该回到那个位置上去继续运行 这就叫 retrun address

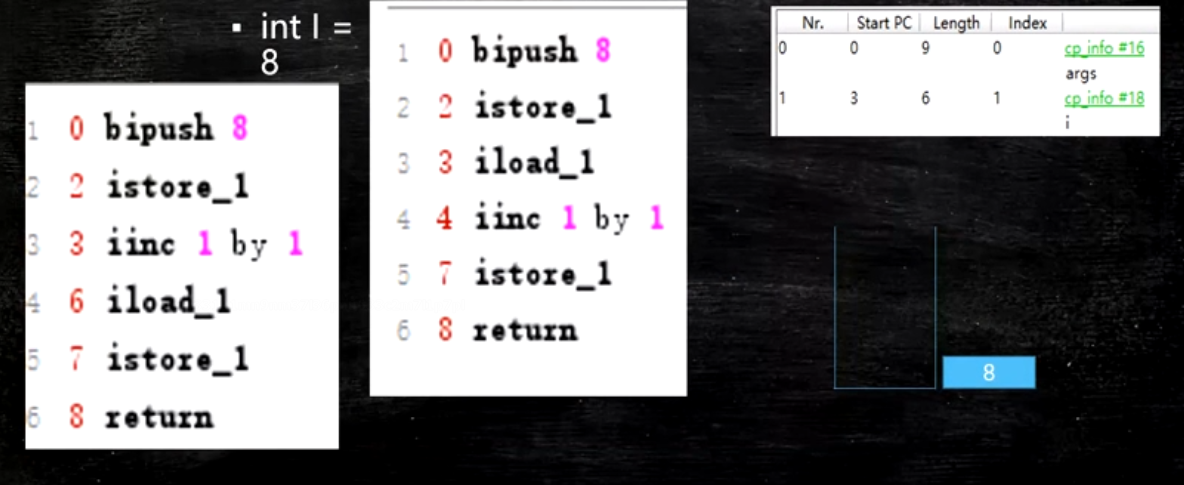
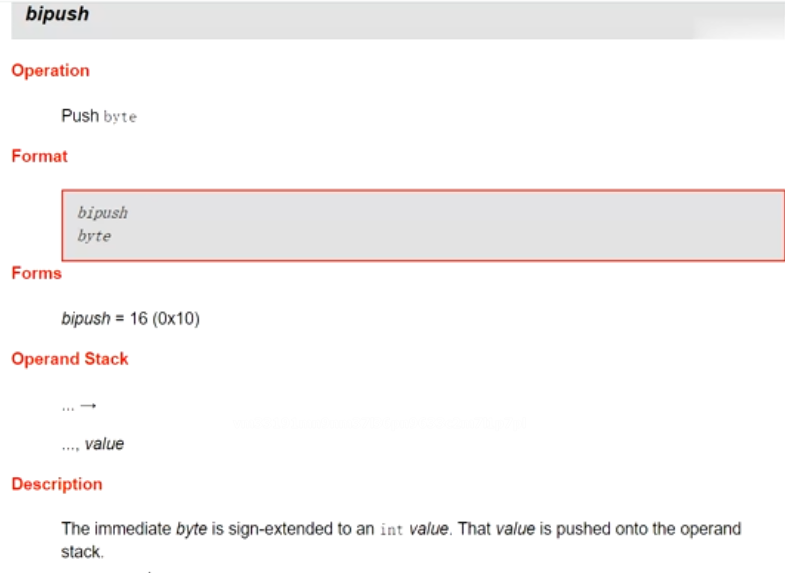
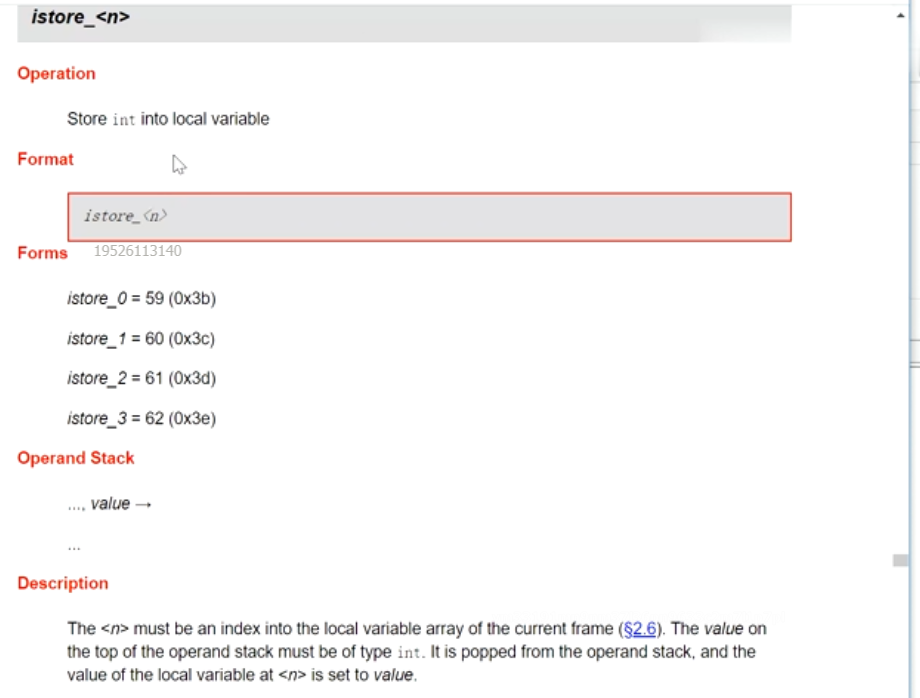
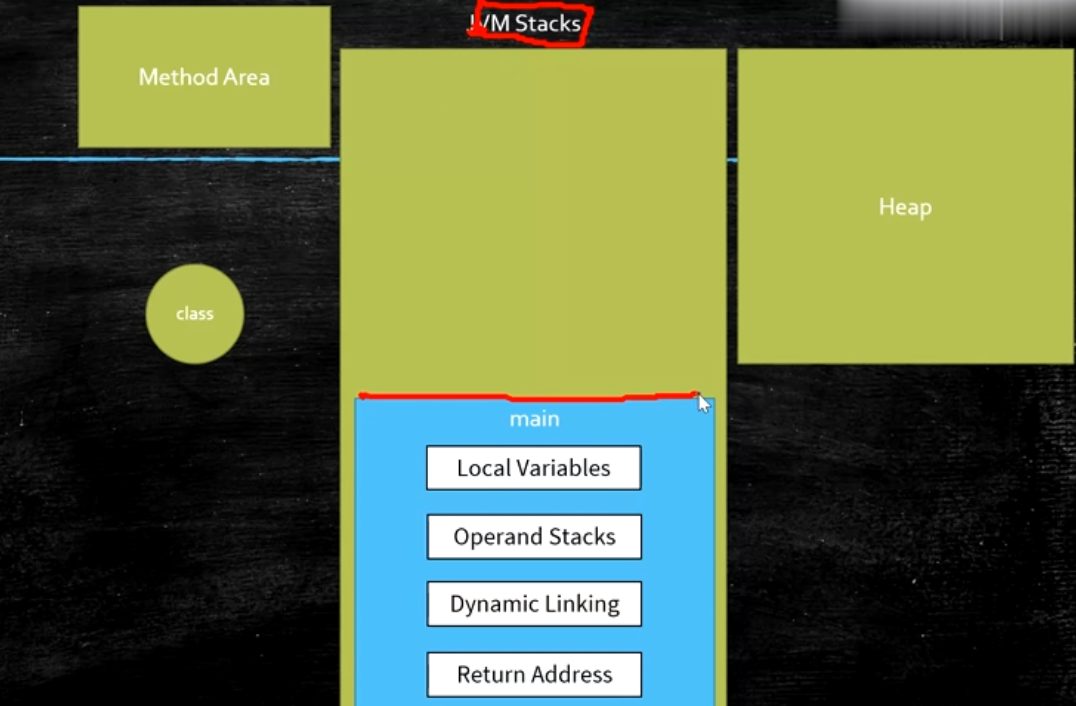
JVM Stack 你面有一个一个栈帧 一个方法对应一个栈帧 每个栈帧都有自己的局部变量表 操作树栈 动态链接 return address


 浙公网安备 33010602011771号
浙公网安备 33010602011771号