HashMap原理结构
package com.msb.map; import java.util.Collection; import java.util.HashMap; import java.util.Map; import java.util.Set; /** * @author lcc * @version V1.0 * @Package com.msb.map * @date 2022/4/24 13:16 */ public class HashMapTest { public static void main(String[] args) { HashMap<String, String> hashMap = new HashMap<>(); System.out.println(hashMap.put("name", "张三")); System.out.println(hashMap.put("name", "lisi")); hashMap.put("name", "wangwu"); hashMap.put("name", "zhaoliu"); hashMap.put("age", "13"); hashMap.put("sex", "男"); hashMap.put("height", "168"); //hashMap.remove("name"); System.out.println(hashMap.containsKey("name")); System.out.println(hashMap);//hashmap 无序唯一 System.out.println(hashMap.size());//因为key相同 所以最后添加的覆盖了前面的 //hashset 是只要对象属性不同 就能插入 无序唯一 //treeset 实现比较器才能去重 System.out.println("---------------------"); HashMap<String, String> hashMap2= new HashMap<>(); hashMap2.put("name", "wangwu"); hashMap2.put("name", "zhaoliu"); hashMap2.put("age", "13"); hashMap2.put("sex", "男"); hashMap2.put("height", "168"); System.out.println(hashMap==hashMap2); System.out.println(hashMap.equals(hashMap2)); System.out.println(hashMap2.isEmpty()); System.out.println(hashMap2.get("age")); System.out.println(hashMap2.keySet());//获得所有的key Set<String> strings = hashMap2.keySet(); for (String string : strings) { System.out.print(string+" "); } System.out.println("-------------"); Collection<String> values = hashMap2.values(); for (String value : values) { System.out.println(value+" "); } System.out.println("-------------"); System.out.println(hashMap2.keySet());//获得所有的key Set<String> strings2 = hashMap2.keySet(); for (String string : strings2) { System.out.print(hashMap2.get(string)+" "); } System.out.println("--------------------------"); Set<Map.Entry<String, String>> entries = hashMap2.entrySet(); System.out.println(entries); for (Map.Entry<String, String> entry : entries) { System.out.println(entry.getKey()+":"+entry.getValue()); } } }
public class HashMapTest01 { public static void main(String[] args) { HashMap<Integer, String> hashMap = new HashMap<>(); System.out.println(hashMap.put(12, "丽丽")); hashMap.put(11, "露露"); hashMap.put(10, "菲菲"); System.out.println(hashMap.put(12, "明明"));//这里为什么会输出丽丽? hashMap.put(14, "莹莹"); System.out.println(hashMap); System.out.println(hashMap.size()); } }
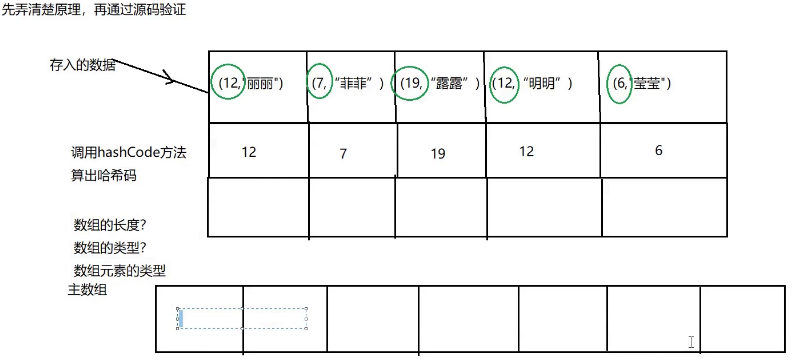
hashMap 会将自己的key 作为依据 计算hashcode 值
这里注意 如果说key 为基本数据类型 直接可以调用默认的hashcode 计算方法
但是引用数据类型 那么引用数据类型必须要重写hashcode 方法和equals方法
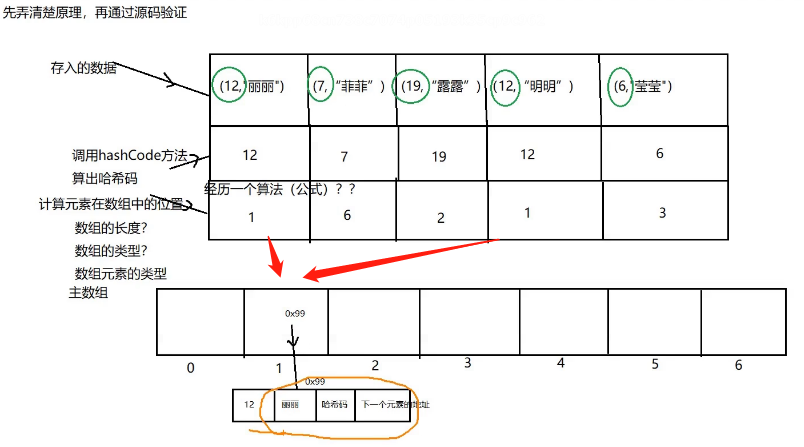
根据integer 的hash code 算出hash码 然后根据底层公式计算出所在 的底层数组的位置
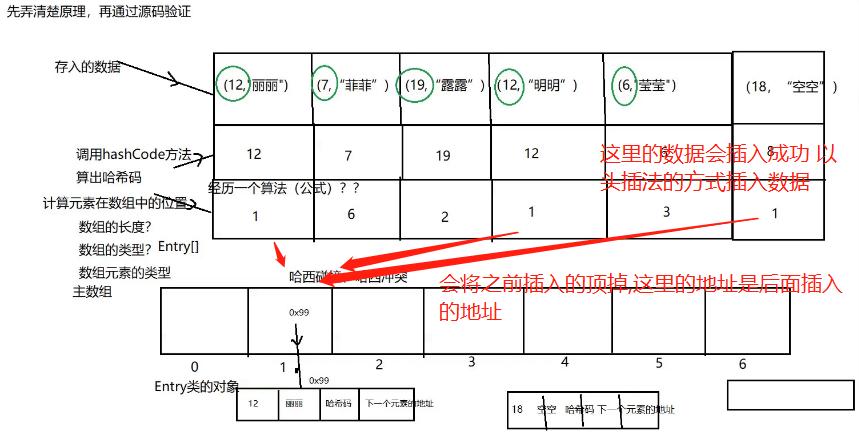
这里需要注意 要是key的值一样 那么必定放到底层数组下标的位置也一样
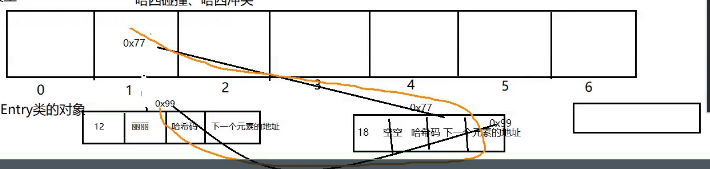
jdk 1.7 是以头插法插入元素 但是Jdk 1.8 之后是尾插法
hashMap 底层原理是 数组+链表=哈希表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号