zk选举leader 详解
zookeeper分布式协调
可扩展 可靠性 时序性 快速
1扩展性 leader flower observer
读写分离 所有的增删改可以触发给leader 查询可以在flower身上
只有flower才能选举 observer 的级别比flower更优的级别 不会参与投票 当leader 宕机后 observer会等flower投票出leader 后同步数据
那么选举就是由flower的数量决定 选举的速度
例 假如一个公司30台机器 选出奇数台21 当flower 其他是observer 来放大查询的能力
zoo.cfg
server.1=192.168.1.100
server.1=192.168.1.101 server.1=192.168.1.102 server.1=192.168.1.103:observer
2 可靠性 分布式 leader挂了可以快速恢复 数据的可靠 可用 一致性
最终一致性
过程中 节点是否对外提供服务
paxos 是基于消息传递的一致性算法
是zkServer 最基础的东西






ZAB
原子广播协议 原子 要么成功要么失败 广播 不代表全部知道
队列 FIFO 顺序性
作用在可用状态 有leader的时候
zk 的数据存在内存
用磁盘保存日志
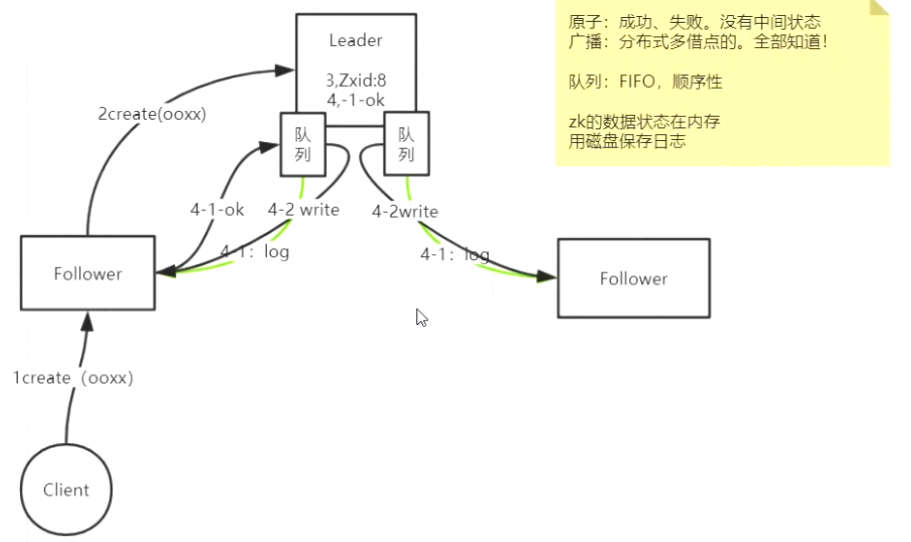
leader中会有队列来发送接受消息
当client 在一个flower上创建一个ooxx文件时 会向leader发送请求
当leader同意发送 写日志 返回时经过队列 ,flower会回送一个ok消息
如果另一个flower因为网络或其他原有无法正常发送响应信息,
但是leader 和发起的flower 已经过半 所以leader 也会向没有做出响应的flower
发送 写日志 的消息
只要 最终flower能将队列中的消息消费完 就能保证最终一致性
---------------------------------------------------------------------------------------------------------------------------
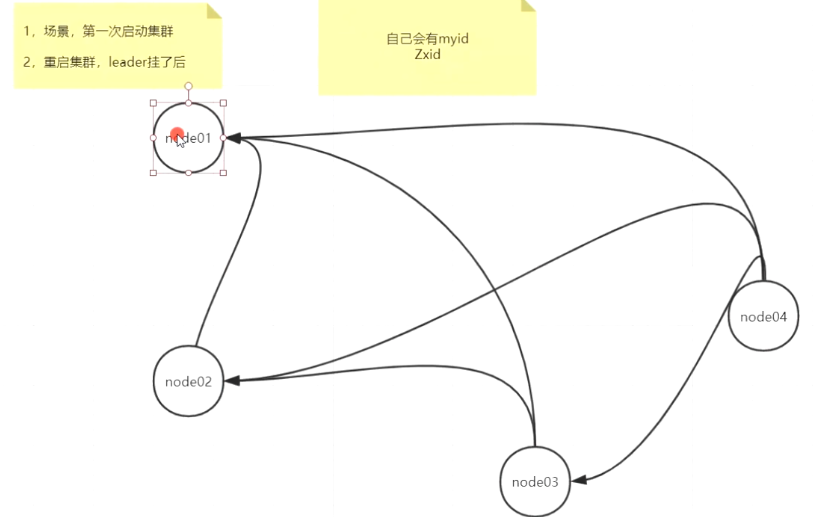
新的leader(会拥有zxid 最新的事物id,如果都一样多,看谁的myid 最大) 你见到的可用的数据都是过半通过的数据 第一次启动集群 只要达到过半的时候,第一台启动的就是leader 因为他们的事物id 相同 但是myid 最大的那一台且超过半的那一台就会成为leader 假如leader 宕机时 还有一个node3没有消化玩队列中的数据时,那么那个node03的事物id 会比其他的节点事物id 低 ,但是node03 本应当时替代leader的 但是数据是不全的, 此时node03 会将自己的数据发送给其他两个节点,并让他们参与投票, 当node02和node01 收到数据时 发现node03传过来的事物id 小于当前事物id 于是 拒绝 并发送正确的 事物id 过去给node03, 在node01和node02 发送数据时, 他们也会给自己投票 于是node01和node02 的事物id +1 node01和node02 之间 会相互比较 发现node02的myid 大于自己node01的myid 于是node01会投票给node02 node02和node03比较 发现 虽然myid 大于node02 但是数据不是最新的 会投票个node02 和node01 最终node02 会成为leader
zk 选举过程 1 3888 造成两两通信 2 任何人投票 都会触发那个准leader发起自己的投票 3 推选制 先比较zxid 事物id 如果zxid 相同 比较myid

 浙公网安备 33010602011771号
浙公网安备 33010602011771号