
OO第三次作业总结
零、写在前面
第三单元的作业题目为根据JML规格实现社交关系模拟系统,主要目的为学习并掌握JML规格的书写,学会根据已有的JML进行代码编写,熟练使用图论方法进行社交关系模拟系统的实现,并掌握容器方法的复杂度、图轮各种算法的复杂度,由此进行性能优化。
客观来说作业的难度偏简单(因为没有JML的书写,只是根据规格写代码,实验里的JML书写还是费了挺大功夫的)。第一次作业进行翻译,需要优化联通分量的算法;第二次作业添加了几个类,还是进行翻译,需要学会维护变量以提高性能,第三次作业依然是进行翻译,需要运用最短路径算法的堆优化提高性能。对于我来说,在第一次作业中就想用dfs试一试会不会TLE,不想改并查集,结果被hack了6刀;第二次作业没什么问题;第三次作业最短路径算法出了一些小问题,TLE了一个,挺不应该的。总的来说,这个unit作业的难度在于线下样例的构造和对拍,以及对CPU时间的把控。当然,这个unit的学习不应该仅限于作业,作业的高分不能证明我们这个unit学好了。因为作业只涵盖JML的翻译,剩下的如JML的书写还是需要学习的,当然,规格的设计同样重要,通过规格进行形式化验证也是我们需要学习的点。
注:为了分析方便,我将“(1)总结分析自己实现规格所采取的设计策略(3)总结分析容器选择和使用的经验(4)针对本单元容易出现的性能问题,总结分析原因如果自己作业没有出现,分析自己的设计为何可以避免(5)梳理自己的作业架构设计,特别是图模型构建与维护策略”放入“分析作业”大标题中,分作业进行分析。“(2)结合课程内容,整理基于JML规格来设计测试的方法和策略”这一方面将在之后进行分析。
一、分析作业
第一次作业
先上类图:
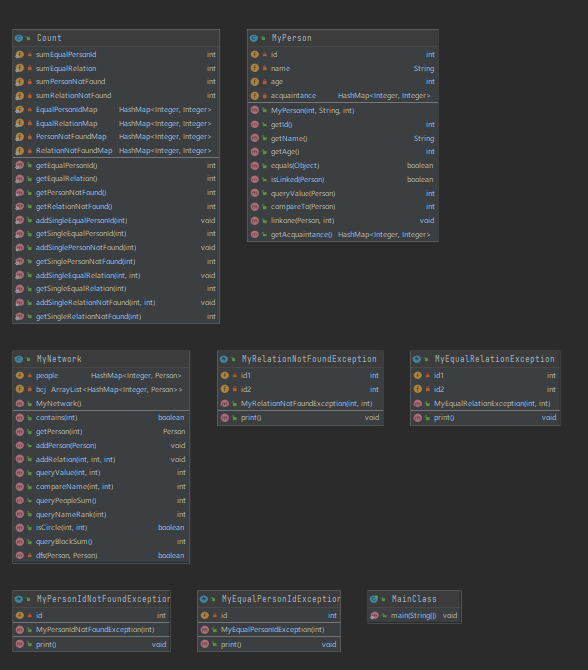
(1)设计策略:引用官方包,就建立了MyPerson、MyNetwork以及一系列异常类,为了增加计数功能,我建立了Count类,其中建立了例如sumEqualPersonId的静态属性记录每个异常的总出现次数,在getSumEqualPersonId方法中直接进行sumEqualPersonId++,之后return,相当于获得了一类异常的计数;建立了PersonNotFoundMap的HashMap,用来建立id与出现此类异常的关系,建立addSinglePersonNotFound,每次目标id出现异常就放入map中或+1,这样实现了计数功能。在MyPerson类中,增加了linkone和getAcquaintance方法,在MyNetwork的addRelation中使用。
(2)容器选择和使用的经验:在Person类中,Person[] acquaintance和int[] value互相关联,一个person有一个value,因此使用hashmap进行存储更符合逻辑,当然containskey、put、get操作是o(1)复杂度的,性能可以优化。同理,MyNetwork中的Person[] people也可以用HashMap<Integer, Person>来优化性能。在并查集的实现上,使用ArrayList<HashMap<Integer, Person>>进行存储,每个连通图存储id和person,比两个arraylist性能好。
(3)性能问题:1.contain、get、put时使用hashmap优化,将o(n)复杂度优化为o(1);2.在判断连通分量和连通图时如果使用dfs和给的双重循环,复杂度至少是o(n3),样例构造成例如ap许多次、ar许多次、之后都是qbs的形式就可以让cpu超时,如
ap 1 Po3ejwiG 65
ap 2 tKF9rvl 91
ap 3 DyQHPluiZP3E 13
...(97条ap指令)
ar 52 93 -93
ar 59 92 67
ar 30 59 -10
...(300条ar指令)
qbs
qbs
qbs
...(600条qbs指令)
我就是这么被hack掉了。因此修改为并查集,将ap、ar、qci变为o(n)复杂度,qbs为o(1)复杂度,这样指令的堆叠就变成了o(an)的复杂度,大幅提高了性能。3.经过互测,有的人用的cache机制防止一直qbs的样例,但是可以使用ap、ar、qci循环的样例hack掉,如
ap 1 Po3ejwiG 65
ar 52 93 -93
qbs
...(这样ap、ar、qbs形式的332条指令)
证明了cache不能解决性能问题(cache相当于面向样例解决问题了,没解决本质),在后面的作业中就不用cache了。
(4)图模型构建与维护策略:改成并查集之前并未有任何策略,也不需要;改了之后增加了ArrayList<HashMap<Integer, Person>>,在ap、ar时进行改变,这样qci、qbs就不需要计算了,只是观察操作。ap时相当于加入了一个新的连通图(单点),ar时相当于对两个连通图进行合并,这样qci只需要判断两个person在不在同一个hashmap中即可,qbs只需要返回hashmap的个数即可。
第二次作业
先上类图:
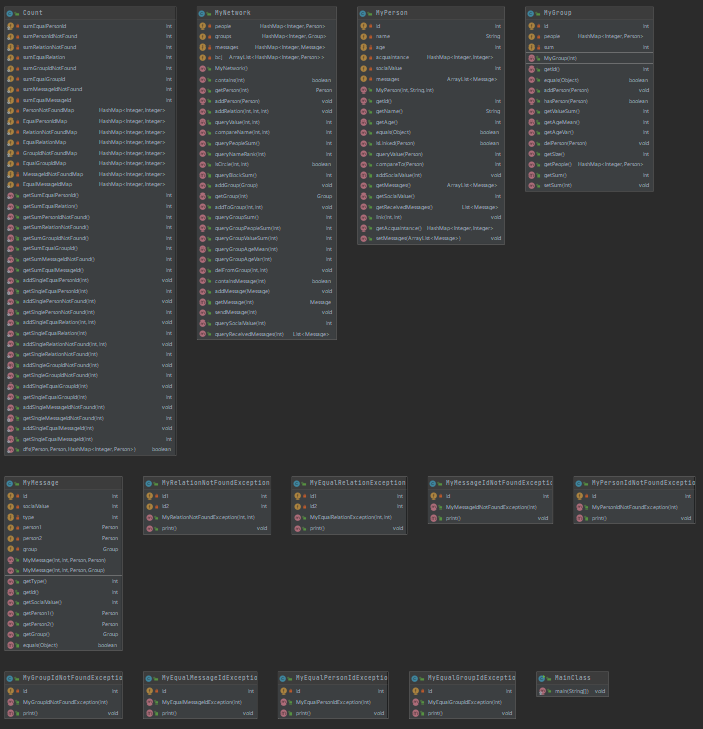
(1)设计策略:引用官方包,就建立了MyPerson、MyNetwork、MyGroup、MyMessage以及一系列异常类,在Count类里增加新增的异常。在MyPerson类中,增加了setMessages方法,在MyNetwork的sendMessage中使用;在MyGroup类中,增加了getPeople、getSum、setSum方法,在MyNetwork的addRelation中使用,维护了sum变量,用来提高queryGroupValueSum性能
(2)容器选择和使用的经验:在MyNetwork类中,和Person[] people一样,Group[] groups、Message[] messages也可以用HashMap<Integer, Group>、HashMap<Integer, Message>来优化性能,MyGroup中Person[] people同理。由于MyPerson中的Message[] messages需要考虑顺序,因此不能使用Hashmap进行性能优化。
(3)性能问题:1.getAgeVar是计算方差的函数,首先应该计算平均值(也就是期望),如果在循环中计算平均值就相当于o(n2)的复杂度,因此应该先计算好平均值再计算方差,这样就是o(2n)的复杂度了;2.getValueSum相当于将组内所有边的权值相加乘2(一条边的两个点各算一次),因此需要循环两次,这就是o(n2)的复杂度。经过测试,CPU2秒是无法承受这样的复杂度的,因此需要优化,不然样例构造成例如ap、ar、qgvs循环的形式就可以让cpu超时。因此选择了每个组维护一个sum变量,在group的addPerson、delPerson,network的addRelation中需要对sum进行修改(这三条指令加入了一个o(n)操作),qgvs返回sum就可以。
(4)图模型构建与维护策略:对于维护sum变量,sum初值为0,group的addPerson相当于加入了一个人,需要sum加上这个人和已有人的所有边的权值的二倍,delPerson相当于减少了一个人,需要sum减去这个人和已有人的所有边的权值的二倍,addRelation相当于增加了一条边,需要判断这两个人是否在一个组里,如果在,就需要使这个组的sum加上二倍的权值。这样qgvs返回相应组的sum即可。
第三次作业
先上类图:
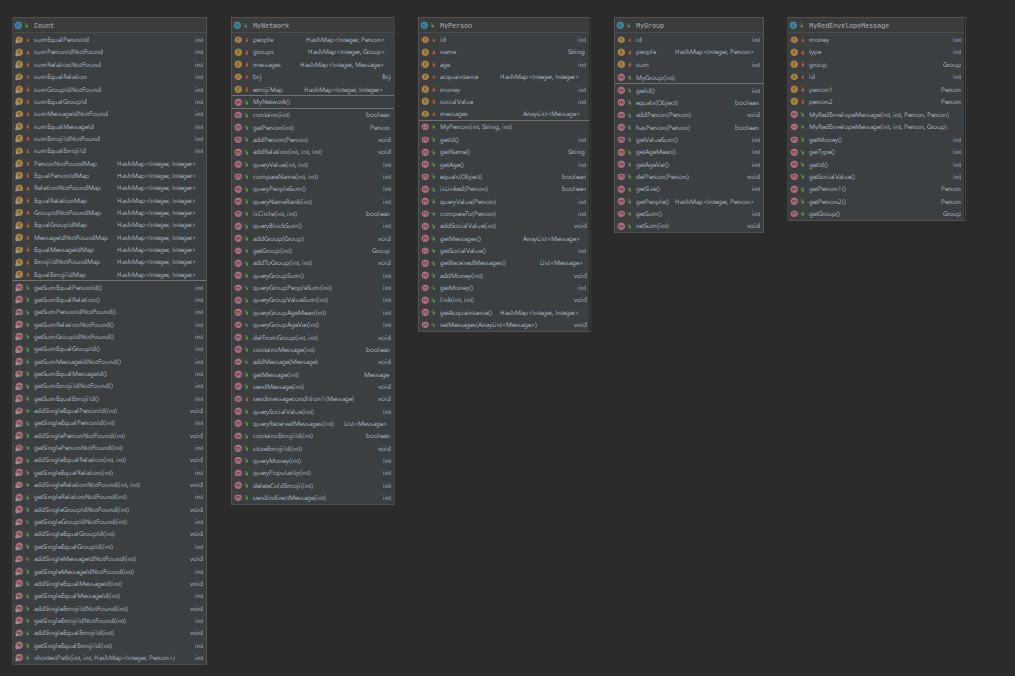
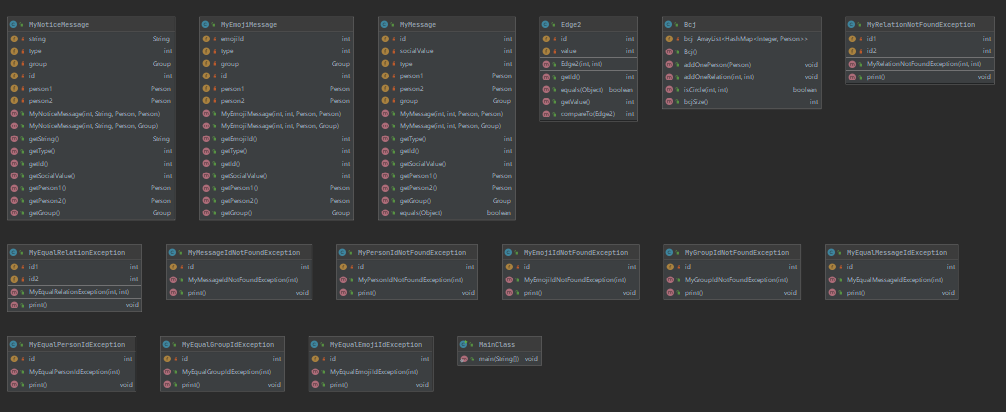
1)设计策略:引用官方包,就建立了MyPerson、MyNetwork、MyGroup、MyMessage、MyEmojiMessage、MyNoticeMessage、MyRedEnvelopeMessage以及一系列异常类,在Count类里增加新增的异常。将MyNetwork中的并查集提取出来,单列成一个类bcj,将方法也抽象出来,作为并查集类的方法,并查集的ArrayList也成为了一个属性(原因:checkstyle超过500行了,得缩),增加了扩展性。建立了新的Edge2类,用于最短路径Dijkstra中储存点和权值的数据结构。
(2)容器选择和使用的经验:在MyNetwork类中,和MyPerson类中的acquaintance和value一样,也可以用HashMap<Integer, Integer>来将int[] emojiIdList、int[] emojiHeatList组合起来,优化性能,并且使逻辑更加清晰。在Dijkstra堆优化算法中需要实现一个小根堆,因此选择了java自带的优先队列PriorityQueue(由于优先队列需要比大小,因此需要将其中的元素按需求重写compare方法)。
(3)性能问题:1.在sim求最短路径使用了Dijkstra堆优化策略,依然超时了,因为在遍历所有边的时候我真的遍历的所有边,即people对应的所有人之间的所有边,这样大幅增加了内层循环的量,导致我TLE了一个点。在自己测试的时候我测试的是5000条指令,为了防互测,结果强测是10000条(这。。),就T了。bug修复就非常简单了,不需要获得全部的边,person类里自己有acquaintance,存储着人和权值呢,直接用就可以了。
(4)图模型构建与维护策略:由于Dijkstra中需要一个储存点和权值的数据结构,我建立了Edge2类,属性为id和value,由于需要使用java自带的优先队列, 所以需要重写compare和equal方法,即比较value出大小。
二、基于JML规格来设计测试的方法和策略
测试方法:
(1)Junit:可以使用Junit进行功能验证,但我并未使用这种方法,原因为首先Junit需要标准输入和标准输出,我可以随机生成大量标准输入,但是标准输出的绝对正确性只能靠人来验证,因此只能构造少量、简短、覆盖边界的样例进行Junit测试,这样效率很低;其次是Junit没法进行CPU时间即性能的测试,就无法查出TLE,因此我只是尝试了Junit,学习了一下使用方法,没有实际应用于作业中。
(2)由于有JML规格,可以进行数学上的证明,证明程序的正确性。但是这过于麻烦,效率巨低,因此不能选用。
(3)进行黑盒测试,即对拍。我与几个同学组成了对拍小组,进行数据的生成和对拍。我们设计了全功能测试,异常类测试和性能测试。全功能测试即随机生成大量指令,指令条数超过范围,对每个指令设一定的权值,防止出现大量异常而无法完成功能的检验;异常类测试即先ap、ar等构造型指令,构造好一个网络,之后加入一组没用过的id进行指令测试,这样保证了必然出现异常,并且可以对相同的id出现的异常进行计数,完成对异常的检验;性能测试即对我们挑选出来的JML规格指令复杂度超过o(n)的指令进行性能测试, 例如指令为m,则ap许多次,ar许多次,剩下都是指令m;还可以构造ap、ar、m的循环指令,用来hack实际大于o(n),但是使用cache机制的人。
三、心得体会
(1)这次作业只是关于JML的翻译,要想领会JML还是需要从ppt、实验、training下手,任重而道远。
(2)性能很重要,细致很重要,必须考虑到所有东西,不然会被hack。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号