


初识Parallel Extensions之TPL
初识Parallel Extensions之TPL
LazyBee
上一篇我们介绍了Parallel Extensions中的PLINQ(具体请参考:初识Parallel Extensions之PLINQ),今天我们来看看Parallel Extensions的另外一个组成部分—任务并行库TPL(Task Parallel Library),TPL也是Parallel FX的关键组件之一。TPL的设计的目的是为了开发人员能够非常简单的使用TPL来编写可自动使用多处理器的托管代码,以提高程序运行的速度。PLINQ实现了以声明的方式(使用AsParallel)对数据源进行并行化的查询,而TPL是通过命令的方式将面向数据的操作(如for,foreach循环)以及轻量级的任务自动的运行在并行硬件上。
如果我们希望在我们程序中使用TPL的话,和PLINQ一样,首先我们需要引用System.Threading.dll文件,由于TPL的类主要是放在System.Threading和System.Threading.Tasks命名空间中,所以需要在我们的类文件中用using关键字将这两个命名空间添加进去。下面我们就将我们的关注点放在这两个命名空间。
结构化并行性
最普通的面向数据的操作就是循环,将循环并行化是并行程序的关键点之一。TPL提供了For, ForEach和Do三个命令来将循环并行化。这三个命令都是System.Threading.Parallel类的静态方法。下面我们就来详细看一下这三个静态方法:
For
矩阵相乘,大家在学校的《线性代数》课上肯定都学过,不过到现在肯定都忘的光光的了,我也是现上网去搜了搜(呵呵,寒…)。也就是说一个MXN的矩阵去乘以一个NXP的矩阵,就可以得到一个MXP的矩阵。其公式是:![]()
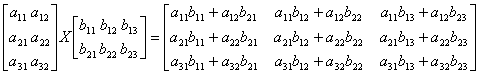
下面我们就看看使用C#实现的矩阵相乘:
 class Matrix<T>
class Matrix<T> {
{

 private T[,] _values; public Matrix(int rows, int columns)
private T[,] _values; public Matrix(int rows, int columns) {
{ if (rows < 1) throw new ArgumentOutOfRangeException("rows"); if (columns < 1) throw new ArgumentOutOfRangeException("columns"); Rows = rows; Columns = columns; _values = new T[rows, columns];
if (rows < 1) throw new ArgumentOutOfRangeException("rows"); if (columns < 1) throw new ArgumentOutOfRangeException("columns"); Rows = rows; Columns = columns; _values = new T[rows, columns]; } public T this[int row, int column] { get { return _values[row, column]; } set { _values[row, column] = value; } } public int Rows { get; private set; } public int Columns { get; private set; }
} public T this[int row, int column] { get { return _values[row, column]; } set { _values[row, column] = value; } } public int Rows { get; private set; } public int Columns { get; private set; } }public static Matrix<double> MultiplySequential(Matrix<double> m1, Matrix<double> m2){Matrix<double> result = new Matrix<double>(m1.Rows, m2.Columns); for (int i = 0; i < m1.Rows; i++) { for (int j = 0; j < m2.Columns; j++) { result[i, j] = 0; for (int k = 0; k < m1.Columns; k++) { result[i, j] += m1[i, k] * m2[k, j]; } } } return result; }
}public static Matrix<double> MultiplySequential(Matrix<double> m1, Matrix<double> m2){Matrix<double> result = new Matrix<double>(m1.Rows, m2.Columns); for (int i = 0; i < m1.Rows; i++) { for (int j = 0; j < m2.Columns; j++) { result[i, j] = 0; for (int k = 0; k < m1.Columns; k++) { result[i, j] += m1[i, k] * m2[k, j]; } } } return result; }有可能要进行相乘矩阵可能非常大(比如说500X500),我们可以利用TPL为我们提供Parallel.For来加快我们的计算速度,其定义为:
public static void For(int fromInclusive,int toExclusive, Action<int> body)
其中:fromInclusive是循环的起始值
toExclusive:循环的结束值
Action<int>:每一次循环要执行的操作,该操作有一个int的输入参数,也就是循环
的索引,没有返回值。
将循环并行化的矩阵相乘的代码如下:
public static Matrix<double> MultiplyParallel(Matrix<double> m1, Matrix<double> m2){Matrix<double> result = new Matrix<double>(m1.Rows, m2.Columns); Parallel.For(0, m1.Rows, i => { for (int j = 0; j < m2.Columns; j++) { result[i, j] = 0; for (int k = 0; k < m1.Columns; k++) { result[i, j] += m1[i, k] * m2[k, j]; } } }); return result;}在我的机器上两个随机产生的500X500的double的矩阵相乘,非并行化版本与并行化版本运行的时间比平均为1.98.效果还是比较明显的,大家也可以在自己的机器上试试。
同时,针对不同的情况Parallel.For也提供了重载版本。比如说我们需要在一个非常大的数据列表中查找指定的数据,在找到第一个数据之后就退出查找循环,这时候我们就可以使用下面这个重载版本:
public static void For(int fromInclusive,int toExclusive,Action<int, ParallelState> body)
前面两个参数也是循环的起始值和结束值。不同的就是每次循环要执行的操作,该操作多了一个ParallelState类型的输入参数,ParallelState有一个Stop方法,用于终止循环。
如果我们需要计算指定范围内的所有素数之和,这是我们可以利用Parallel.For的另外一个重载:
public static void For<TLocal>(int fromInclusive,int toExclusive,
Func<TLocal> threadLocalSelector,
Action<int, ParallelState<TLocal>> body,
Action<TLocal> threadLocalCleanup)
前面两个参数同样是循环的起始值和结束值,threadLocalSelector是产生本地状态的函数,body是每次循环(迭代)要进行的处理操作,threadLocalCleanup是用于清理线程本地状态的操作。这时我们计算素数之和的代码片段如下:
int sum = 0;Parallel.For(0, 10000, () => 0, (i,state)=>{ if (isPrime(i)) state.ThreadLocalState += i;},partialSum => Interlocked.Add(ref sum, partialSum));()=>0就是告诉编译器state.ThreadLocalState中存放的数据类型是int型,并且将其初始化为0,在执行完循环之后,将所有线程中的ThreadLocalState的值相加来得到最终的素数之和。例子中partialSum就是表示ThreadLocalState的参数。
你也可以使用这个重载来取出所有的素数(当然你也可以使用PLINQ来做):
List<int> results = new List<int>();Parallel.For(0, 10000, () => new List<int>(),(i, state) => { if (isPrime(i)) state.ThreadLocalState.Add(i); }, partialResults => { lock (results) { results.AddRange(partialResults); } });
 浙公网安备 33010602011771号
浙公网安备 33010602011771号