
软工作业2个人项目
作业要求
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目-论文查重算法 |
| 这个作业的目标 | 1、完成PSP表格。2、完成“论文查重算法”的设计并进行测试。3、代码签入Github中。 4、编写博客记录。 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 850 | 842 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 400 | 296 |
| · Design Spec | · 生成设计文档 | 100 | 63 |
| · Design Review | · 设计复审 | 100 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 80 | 15 |
| · Design | · 具体设计 | 200 | 48 |
| · Coding | · 具体编码 | 400 | 232 |
| · Code Review | · 代码复审 | 60 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 30 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 180 | 98 |
| · Size Measurement | · 计算工作量 | 30 | 0 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| · 合计 | 3410 | 842 |
设计报告
一、代码规范
命名规范:
-
使用有意义的变量名和函数名,名字全部由英文命名。
-
使用小写字母和下划线(snake_case)或驼峰命名法(camelCase)来命名变量和函数。
缩进和格式化:
- 由于使用的是Python编写,对缩进的要求非常严格。
注释和文档:
-
在关键部分和复杂代码块添加注释,解释代码的目的和工作原理。
-
对函数、变量等注释描述其输入、输出、用途等。
模块和包:
-
将代码分为模块和包,以提高可维护性。
-
使用命名空间来组织代码,避免全局变量和函数的滥用。
版本控制:
-
使用版本控制系统(如Git)来管理代码的版本,确保代码历史可追踪。
-
遵循版本控制的最佳实践,如提交有意义的注释和分支管理。
测试:
- 编写单元测试和集成测试,以确保代码的正确性。
二、需求
-
文本预处理
需要去掉文中的标点符号、对文本数据进行预处理,包括分词、移除停用词、标点符号、数字和特殊字符。
将文本转换为模型可以处理的数字形式,如词嵌入或BERT的输入格式。这里使用的是Word2Vec 模型将文本转换成词向量的形式。
-
构建模型并训练
我们使用深度学习中的Siamese神经网络模型进行训练。首先需要构建数据集和数据加载器,数据集我们可以在网上找到很多。然后我们搭建Siamese神经网络,计算欧几里得距离,计算损失函数,训练循环。
-
测试结果
-
模型改进
三、具体算法
(1)文件的输入和输出
使用Python中的sys模块来处理命令行参数,输入论文原版的文件和抄袭版论文论文的文件,输出答案文件的文件。
代码如下:
import sys
# 读取文件
def textLoad(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
return text # 返回文本
except FileExistsError: # 检查目录是否已存在
print(f"文件'{file_path}'不存在。")
sys.exit(1)
except FileNotFoundError: # 检查文件是否存在
print(f"文件 '{file_path}' 不存在。")
sys.exit(1)
except Exception as e:
print(f"读取文件时出错:{e}")
sys.exit(1)
orig_path = r'D:\homework\data\orig.txt'
orig_add_path = r'D:\homework\data\orig_0.8_add.txt'
orig_del_path = r'D:\homework\data\orig_0.8_del.txt'
orig_dis1_path = r'D:\homework\data\orig_0.8_dis_1.txt'
orig_dis10_path = r'D:\homework\data\orig_0.8_dis_10.txt'
orig_dis15_path = r'D:\homework\data\orig_0.8_dis_15.txt'
orig = textLoad(orig_path)
orig_add = textLoad(orig_add_path)
orig_del = textLoad(orig_del_path)
orig_dis1 = textLoad(orig_dis1_path)
orig_dis10 = textLoad(orig_dis10_path)
orig_dis15 = textLoad(orig_dis15_path)
(2)文本预处理
调用Python中的jieba库对文本进行分词、移除标点符号、特殊字符、停用词。需要安装jieba库,可以参考这个博主的教程:Python-安装jieba库步骤及可能遇到的问题。但是运行会遇到下面这样的问题:
加一行jieba.setLogLevel(jieba.logging.INFO)就可以解决了
代码如下:
import jieba # 结巴库,用于分词
# 文本预处理
def textPreprocess(text_input):
# 分词功能
cut_res = jieba.cut(text_input, cut_all=True)
# 去除标点符号、空格和英文字符
filtered_words = [word for word in cut_res if re.match(r'^[\u4e00-\u9fa5]+$', word)]
return filtered_words
text_preprocess_orig = textPreprocess(orig)
text_preprocess_orig_add = textPreprocess(orig_add)
text_preprocess_orig_del = textPreprocess(orig_del)
text_preprocess_orig_dis1 = textPreprocess(orig_dis1)
text_preprocess_orig_dis10 = textPreprocess(orig_dis10)
text_preprocess_orig_dis15 = textPreprocess(orig_dis15)
(3)将文本中的每个词都转换为词向量
这里我们需要先下载维基中文的词库,也就是中文 Word2Vec 模型,然后将每个词都转换为词向量。
由于这个模型太大,而且运算速度非常非常非常慢,以及后面的神经网络搭建也是十分繁琐,遂放弃这种算法。咱们的需求远大于实际情况了
四、算法改进
于是上网搜索了一下有无更好的算法,发现了一个叫做sentence_transformers包非常好用,可以帮我们一次性解决分词、转化成词向量的功能。于是具体的步骤如下:
-
文件输入
还是用我们前面提到的方法来输入文件。
-
利用
SentenceTransformer包处理文本下载这个包之前,我们需要先搭建Anaconda环境,在环境当中下载最新的pip,然后再在Anaconda Prompt中下载
sentence_transformers库。然后再去下载SentenceTransformer包,我们可以在Index of /reimers/sentence-transformers/v0.2/中下载这个包,我这里下载的是roberta-large-nli-stsb-mean-tokens.zip。或者去我的Github里面也可以下载:.gitattributes。 -
计算文本相似度(余弦相似度)
五、输出结果
| 相似度 | 文本0 | 文本1 | 文本2 | 文本3 | 文本4 | 文本5 |
|---|---|---|---|---|---|---|
| 文本0 | 1.0000 | 0.7684 | 0.8474 | 0.8623 | 0.8354 | 0.8063 |
| 文本1 | 0.7684 | 1.0000 | 0.8998 | 0.8807 | 0.8314 | 0.6399 |
| 文本2 | 0.8474 | 0.8998 | 1.0000 | 0.9664 | 0.9234 | 0.7386 |
| 文本3 | 0.8623 | 0.8807 | 0.9664 | 1.0000 | 0.9331 | 0.7494 |
| 文本4 | 0.8354 | 0.8314 | 0.9234 | 0.9331 | 1.0000 | 0.7583 |
| 文本5 | 0.8063 | 0.6399 | 0.7386 | 0.7494 | 0.7583 | 1.0000 |
六、性能分析以及覆盖率测试
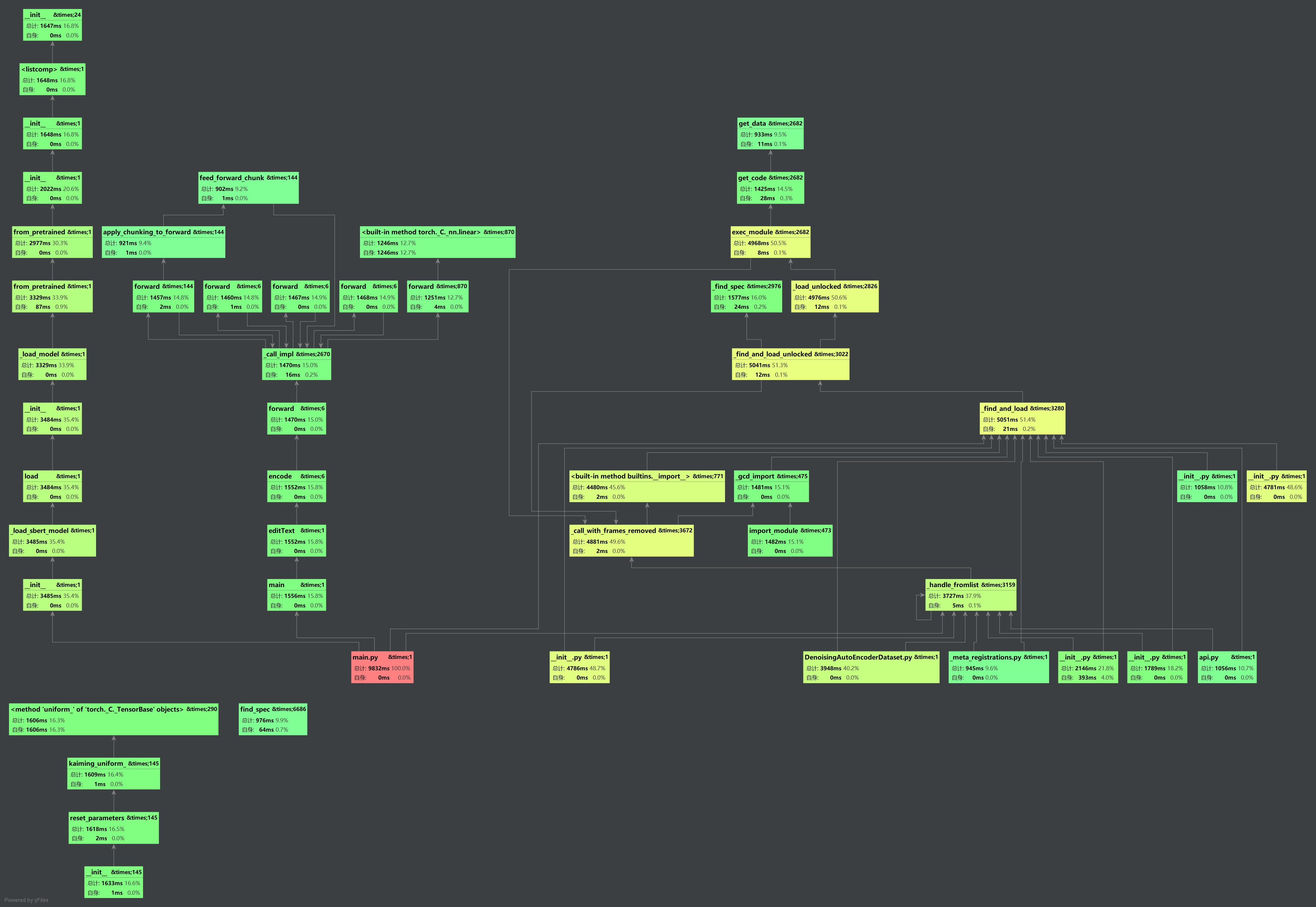
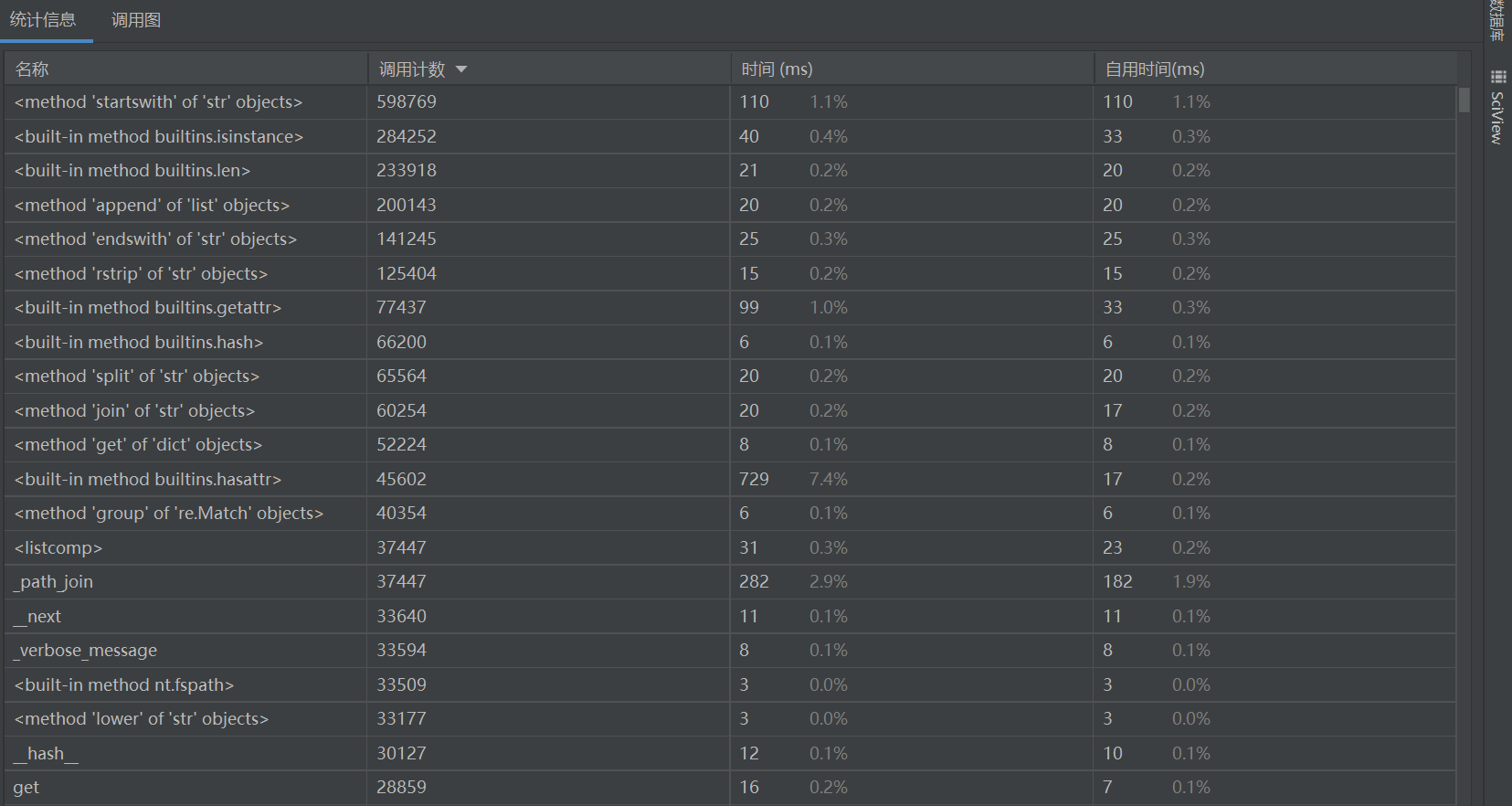

本次运行时间需要20s左右运行,可以看得出main函数是调用次数最多的,占用了9832ms的时间,100%的调用率。
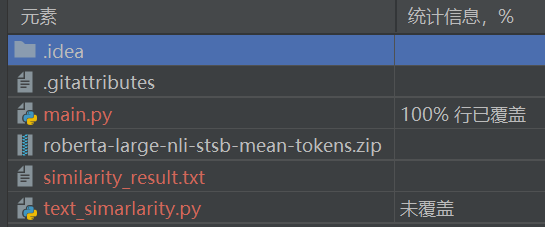
统计覆盖率信息可知,main.py的覆盖率达到100%
GitHub链接
附录:具体代码
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer(r'D:\Anaconda\Lib\site-packages\roberta-large-nli-stsb-mean-tokens')
# 准备要比较的文本
def readTextPath():
list_path = []
list_path.append(r'D:\homework\data\orig.txt')
list_path.append(r'D:\homework\data\orig_0.8_add.txt')
list_path.append(r'D:\homework\data\orig_0.8_del.txt')
list_path.append(r'D:\homework\data\orig_0.8_dis_1.txt')
list_path.append(r'D:\homework\data\orig_0.8_dis_10.txt')
list_path.append(r'D:\homework\data\orig_dis15_path.txt')
return list_path
# 使用模型编码文本
def editText(list_path):
list = []
for path in list_path:
list.append(model.encode(path, convert_to_tensor=True))
return list
# 计算文本相似度(余弦相似度)
def calSimilarity(list):
cos_similarity = []
for i in range(len(list)):
similarity_scores = [] # 创建一个空的子列表来存储相似度分数
for j in range(len(list)):
similarity_scores.append(util.pytorch_cos_sim(list[i], list[j]))
cos_similarity.append(similarity_scores) # 将子列表附加到cos_similarity列表中
return cos_similarity
# 输出相似度分数
def writeResult(cos_similarity):
with open(r'D:\ruangong\similarity_result.txt', 'a', encoding='utf-8') as file:
file.write(f"文本相似度如下表所示:\n")
file.write(f" \t")
for i in range(len(cos_similarity)):
file.write(f" {i} \t")
file.write(f" \n")
for i in range(len(cos_similarity)):
file.write(f"{i} \t")
for j in range(len(cos_similarity[0])):
file.write(f"{cos_similarity[i][j][0][0]:.4f}\t")
file.write(f" \n")
file.close()
def main():
list_path = readTextPath()
list = editText(list_path)
cos_similarity = calSimilarity(list)
writeResult(cos_similarity)
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号