树状数组(BIT)—— 一篇就够了
树状数组(BIT)—— 一篇就够了
前言、内容梗概
本文旨在讲解:
- 树状数组的原理(起源,原理,模板代码与需要注意的一些知识点)
- 树状数组的优势,缺点,与比较(eg:线段树)
- 树状数组的经典例题及其技巧(普通离散化,二分查找离散化)
什么是 BIT ?
起源与介绍
树状数组或二元索引树(英语:Binary Indexed Tree),又以其发明者命名为 \(\mathrm{Fenwick}\) 树。最早由 \(\mathrm{Peter\; M. Fenwick}\) 于1994年以 《A New Data Structure for Cumulative Frequency Tables[1]》为题发表在 《SOFTWARE PRACTICE AND EXPERIENCE》。其初衷是解决数据压缩里的累积频率(Cumulative Frequency)的计算问题,现多用于高效计算数列的前缀和, 区间和。它可以以 \(\mathcal{O(\log n)}\) 的时间得到任意前缀和(区间和)。
很多初学者肯定和我一样,只知晓 BIT 代码精炼,语法简明。对于原理好像了解,却又如雾里探花总感觉隔着些什么。
按照 Peter M. Fenwick 的说法,BIT 的产生源自整数与二进制的类比。
Each integer can be represented as sum of powers of two. In the same way, cumulative frequency can be represented as sum of sets of subfrequencies. In our case, each set contains some successive number of non-overlapping frequencies.
简单翻一下:每个整数可以用二进制来进行表示,在某些情况下,序列累和(这里没有翻译为频率)也可以用一组子序列累和来表示。在本例子中,每个集合都有一些连续不重叠的子序列构成。
实际上, BIT 也是采用类似的想法,将序列累和类比为整数的二进制拆分,每个前缀和拆分为多个不重叠序列和,再利用二进制的方法进行表示。这与 Integer 的位运算非常相似。
之所以命名为: Binary Indexed Tree,在论文中 Fenwick 有如下解释:
In recognition of the close relationship between the tree traversal algorithms and the binary representation of an element index,the name "binar indexed tree" is proposed for the new structure.
也就是考虑到:树的遍历方法与二值表示之间的紧密联系,因此将其命名为二元索引树。
BIT 的原理
在介绍原理之前先对于一些关键的符号做出定义:
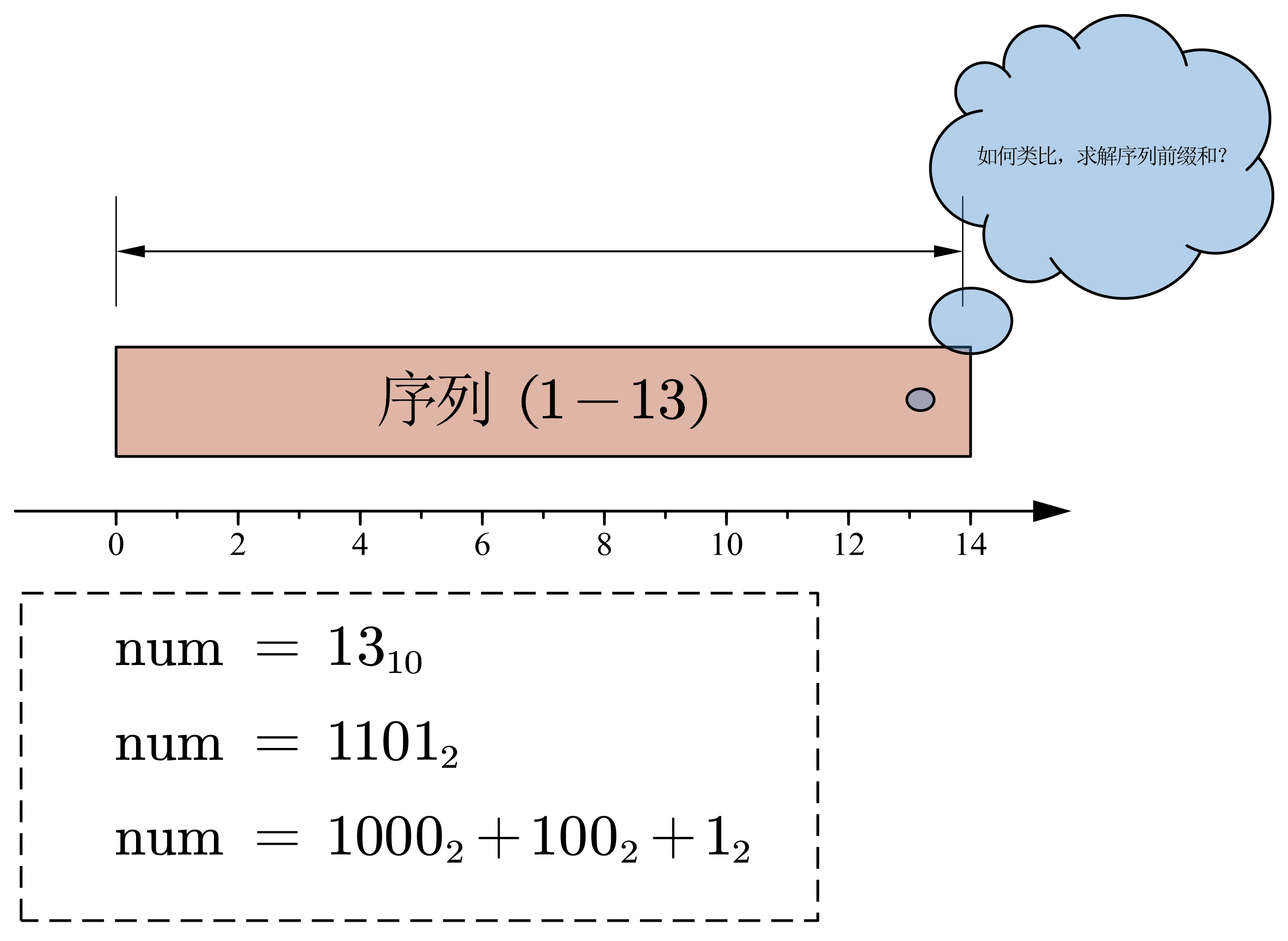
- 第一步:思考整数二进制拆分与序列前缀和的类比
在学习 BIT 时,很容易忽略 BIT 设计的思想,而仅仅停留在对于其代码简洁精炼的赞叹上,所以第一步我们将体会 BIT 是如何类比;如何设计;如何实现的。
如上图所示:我们给定一个整数: \(num = 13\)
我们尝试将 \(num\) 用二进制进行表示: \(1101_2 = 1000_2 + 100_2 + 1_2\) 。可以看到 \(num\) 可以由\(3\)个二进制数组成。且拆分的个数总是 \(\mathcal{O(\log_2n)}\) 级的,因此我猜想Fenwick便开始思考如何将一个子序列,借助二进制的特点快速的表示出来。
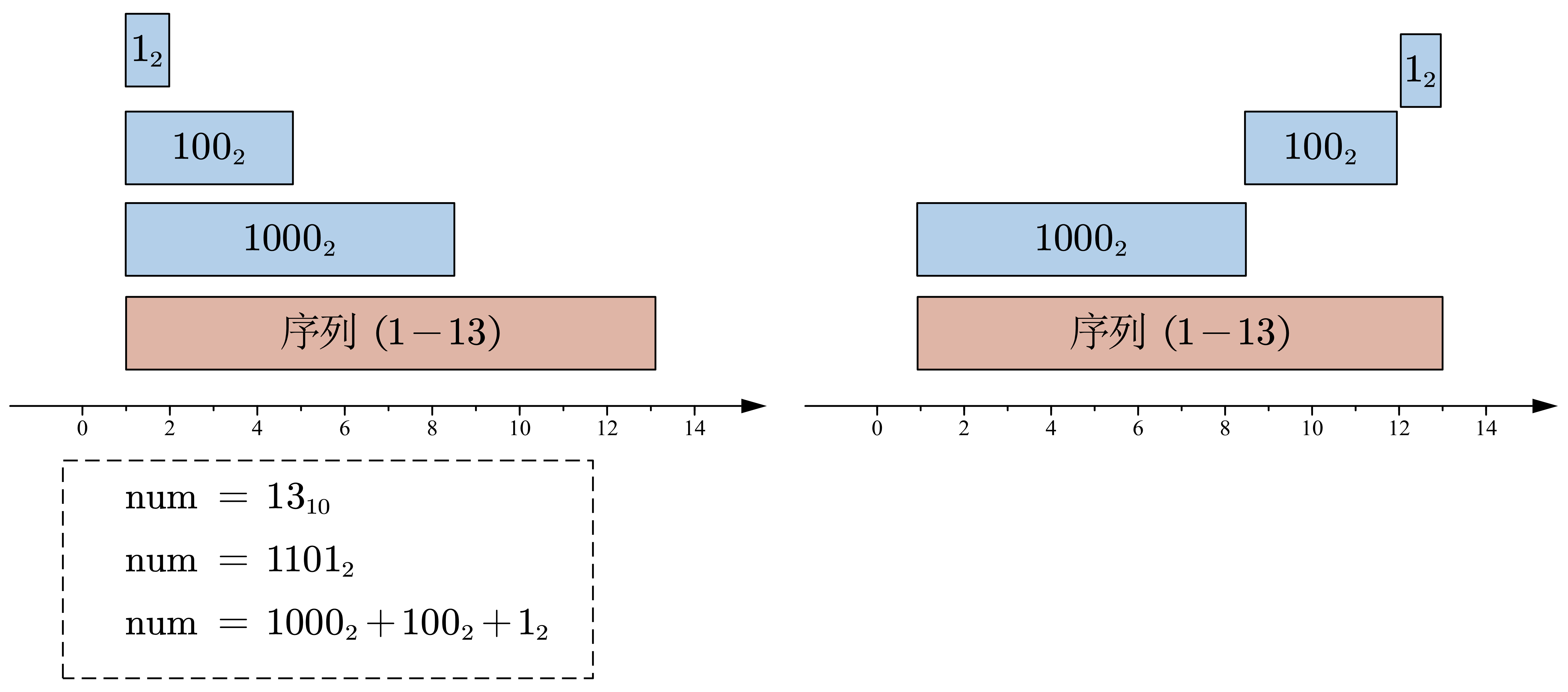
首先,依据最简单的拆分方法(即与二进制拆分相同)如图左示。显然这个方法具有缺陷,某些序列会被重复计算,而有些序列则没有被包含在内,因此解决问题的关键,同时也是 BIT 的核心思想便是如何基于编号,构件一个不重叠的子序列集合。
如右图所示,该拆分方案能很好的实现不重叠的子序列集合,我们尝试将其列出以发现其中的规律:
经过观察:
- \(子序列_1\) 表示的范围在 \([0001_1, 1000_2] \rightarrow [0000_2 + 1, 0000_2 + 1000_2]\)。
- \(子序列_2\) 的表示范围在 \([1001_2, 1100_2] \rightarrow [1000_2 + 1, 1000_2 + 0100_2]\)。
- \(子序列_3\) 的表示范围在 \([1101_2, 1101_2] \rightarrow [1100_2 + 1, 1100_2 + 0001_2]\)。
设某编号的二进制为 \(\mathrm{XXX}bit\mathrm{XXX}_2\) ,设 \(bit\) 为当前需要考虑的位\((bit=1)\),\(\mathrm{X}\) 为\(0 \;or\; 1\) ,则其表示的范围是:
\([XXX0000_2 + 1, XXX0000_2 + bit000_2]\) ,换一句话说:假如序列编号在 \(bit\) 位为1,则其代表的子序列具有如下性质:
- 子序列的基准量为:\(base = 将二进制编号中bit及其之后所有位置0代表的值\quad eg: num=1101_2,bit=第3位(1-index), 则base = 1000_2\)
- 子序列的偏移量:\(offset=1<<(bit-1)\)
- 子序列的下界为:\(lower = base + 1\)
- 子序列的上界为:\(upper=base+offset\)
- 子序列包含的元素位:\(tot = offset\)
假如我们逆序的看待之前\(num=13=1101_2\)的例子:
首先处理\(bit=1\)这一位,其代表的范围是:\([1100_2 + 0001_2, 1100_2 + 0001_2]\)。然后在\(num\)上减去他:\(num -= (1 << (bit-1)) = 1100_2\)
然后,我们处理\(bit=3\)这一位:其代表的范围是:\([1000_2 + 0001_2, 1000_2 + 0100_2]\)。同样,我们在\(num\)上减去它。
最后我们处理\(bit=4\)这一位:其代表的范围是:\([0000_2 + 0001_2, 0000_2 + 1000_2]\)。至此,处理结束。
我们回顾整个处理流程,可以惊讶的发现,如果我们按照逆序处理,我们每次处理的\(bit\)都是当前编号的最后的为1位。我们将每次处理的\(bit\)定义为 \(\mathrm{lowbit}\) (note:这是 BIT 中重要的概念)
用通俗的语言:每个 \(\mathrm{lowbit}\) 都代表其管辖的某一段子序列,又因为 \(\mathrm{lowbit}\) 的值会随着处理不断增大,其控制的范围也会不断增大。其控制范围为:\([cur - lowbit(cur) + 1, cur]\)
如:\(c[13] = tree[13] + tree[12] + tree[8]\)
- \(tree[13] = f[13] \quad \mathrm{lowbit(13) = 1}\)
- \(tree[12] = f[9] + f[10] + f[11] + f[12] \quad \mathrm{lowbit}(12) = 4\)
- \(tree[8] = f[1] + f[2] + \cdots +f[8] \quad \mathrm{lowbit}(8) = 8\)
因此,我们可以做出如下总结:
-
BIT 的原理类比自 Integer 的二进制表示。
-
BIT 对应的数组 \(tree[i] := 子序列 i 的值\) ,每个 \(tree[i]\) 控制 \([i - \mathrm{lowbit(i)}+1, i]\) 范围内的\(f[i]\)值。
-
利用BIT计算 \(c[i]\) 时,通过类似整数的二进制拆分,将 \(c[i]\) 拆分为 \(\mathcal{O(\log_2 n)}\) 个 \(tree[j]\) 进行求解。求解的流程为不断累加 \(tree[i]\) 并置 $ i \leftarrow i - \mathrm{lowbit(i)}$
计算流程的伪代码:
let ans <- 0
while i > 0:
sub_sum <- tree[i] // 获取子序列累和
i <- i - lowbit(i) // 更新 i
ans <- ans + sub_sum
return ans

上图是树状数组非常经典的展示图,通过此图可以快速的了解:\(tree[i] := \sum \limits_{i - \mathrm{lowbit}(i)+1}^{i}f[i]\) 对应的含义。
到这里还是不禁感叹一句:“文章本天成,妙手偶得之”,BIT 这个数据结构实在是精巧。
BIT 的询问,更新操作及其代码实现
query
定义 bitcnt(x) := x二进制中 1 的个数,则根据前文的分析,计算 \(c[i]\) 时类比整数的二进制拆分,我们只需要计算 \(bitcnt(i)\) 个子序列的和。每个子序列通过不断进行 \(\mathrm{lowbit}\) 运算进行获取。
\(\mathrm{lowbit}\) 运算为取数 \(x\) 的最低位的 1 ,最常用的方法为:\(\mathrm{lowbit(x)= (x \& (-x))}\)
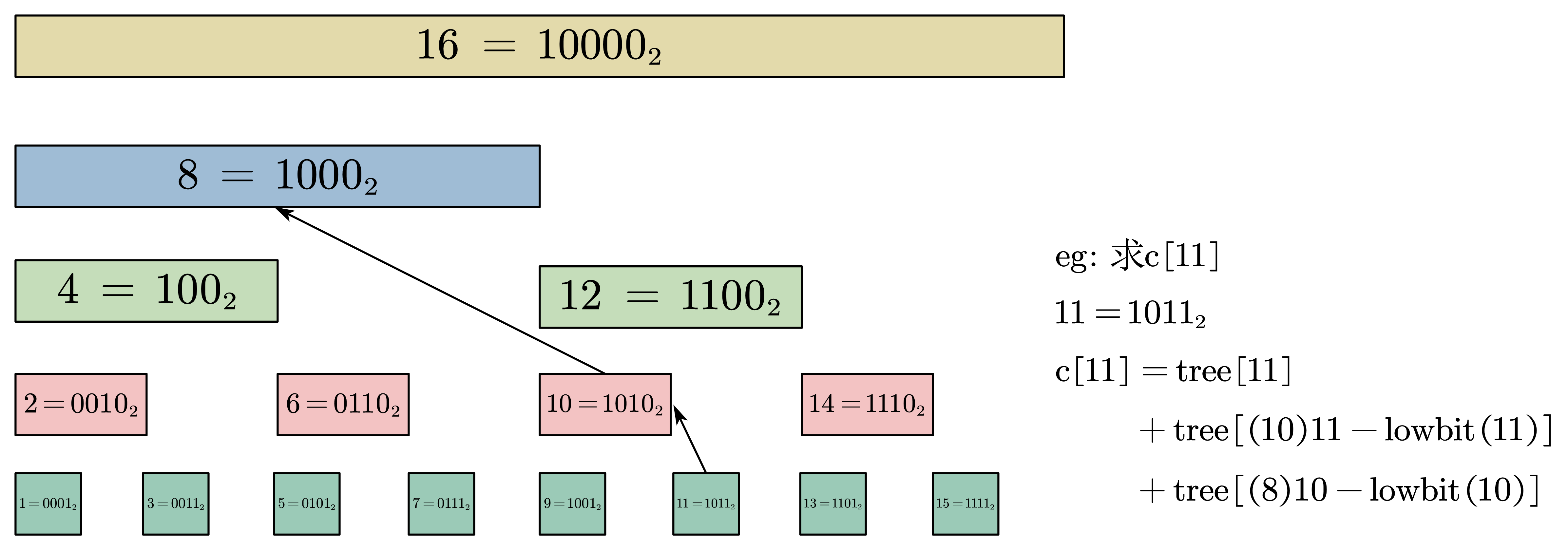
上图展示了一个大小为 \(16\) 的 BIT,可以通过图示清楚的理解 BIT query 的原理:即不断询问当前 \(i\) 指示的子序列和(\(tree[i]\)),并通过 \(\mathrm{lowbit}\) 运算指向下一个子序列和。
其 C++ 代码如下:
T tree[maxn];
template <typename T>
T query(int i){
T res = 0;
while (i > 0){
res += tree[i];
i -= lowbit(i);
}
return res;
}
update
update 实际上可以看成 query 的逆过程,简单来说即是:若要将 \(f[i] += x\),则从 \(tree[i]\) 开始不断向上更新直到达到 BIT 的上界。
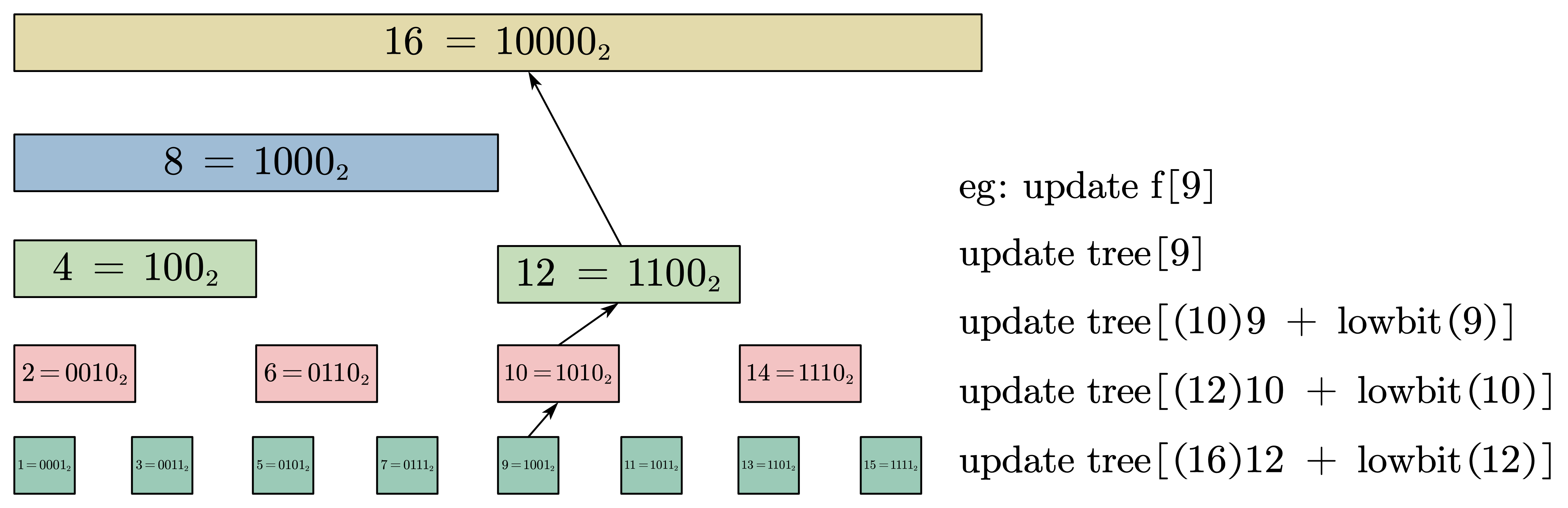
上图展示了 BIT 更新的流程,这里主要说明其中一个需要注意的点:为什么我们首先需要更新 \(tree[i]\) 而不是其他的,如何保证这就是起始点?(可以自己思考一下)
这是我曾在学习 BIT 的过程中比较困惑的一个点:答案在于 \(tree[i]\) 所管辖的子序列范围,我们知道 \(tree[i] 管辖 [i - lowbit(i) + 1, i]\) 这个范围,因此 \(tree[i]\) 是第一个管辖 \(f[i]\) 的元素,所以我们只需要从这个位置不断向上更新即可。
其 C++ 代码如下:
int n; // BIT 的大小, BIT index 从 1 开始
T tree[maxn];
template <typename T>
void add(int i, T x){
while (i <= n){
tree[i] += x;
i += lowbit(i);
}
}
模板
template<typename T>
struct BIT{
#ifndef lowbit
#define lowbit(x) (x & (-x));
#endif
static const int maxn = 1e3+50;
int n;
T t[maxn];
BIT<T> () {}
BIT<T> (int _n): n(_n) { memset(t, 0, sizeof(t)); }
BIT<T> (int _n, T *a): n(_n) {
memset(t, 0, sizeof(t));
/* 从 1 开始 */
for (int i = 1; i <= n; ++ i){
t[i] += a[i];
int j = i + lowbit(i);
if (j <= n) t[j] += t[i];
}
}
void add(int i, T x){
while (i <= n){
t[i] += x;
i += lowbit(i);
}
}
/* 1-index */
T sum(int i){
T ans = 0;
while (i > 0){
ans += t[i];
i -= lowbit(i);
}
return ans;
}
/* 1-index [l, r] */
T sum(int i, int j){
return sum(j) - sum(i - 1);
}
/*
href: https://mingshan.fun/2019/11/29/binary-indexed-tree/
note:
C[i] --> [i - lowbit(i) + 1, i]
father of i --> i + lowbit(i)
node number of i --> lowbit(i)
*/
};
BIT 的优缺点,比较与应用场景
优缺点
树状数组(BIT)的主要优势在于:
- 代码精炼,实现轻松。
query与update操作时间复杂度都只需要 \(\mathcal{O(\log n)}\) 。- 算法常数小,相比于线段树更快(
lazy tag也存在影响)。
而缺点在于:
- 应用场景有限:较为复杂的区间操作无法实现,只能使用线段树(稍后会讲为什么不能实现)
应用场景与比较
树状数组一般用于解决大部分基于区间上的更新以及求和问题。
下面来谈一谈线段树和树状数组在使用上的不同:
线段树与树状数组的区别 线段树和树状数组的基本功能都是在某一满足结合律的操作(比如加法,乘法,最大值,最小值)下,\(\mathcal{O}(\log n)\)的时间复杂度内修改单个元素并且维护区间信息。
不同的是,树状数组只能维护前缀“操作和”(前缀和,前缀积,前缀最大最小),而线段树可以维护区间操作和。但是某些操作是存在逆元的(即:可以用一个操作抵消部分影响,减之于加,除之于乘),这样就给人一种树状数组可以维护区间信息的错觉:维护区间和,模质数意义下的区间乘积,区间 \(\mathrm{xor}\) 和。能这样做的本质是取右端点的前缀结果,然后对左端点左边的前缀结果的逆元做一次操作,所以树状数组的区间询问其实是在两次前缀和询问。
所以我们能看到树状数组能维护一些操作的区间信息但维护不了另一些的:最大/最小值,模非质数意义下的乘法,原因在于这些操作不存在逆元,所以就没法用两个前缀和做。
总结来说:线段树只需要保证区间操作的可结合性,可加性(即一个大区间的结果可以由较小区间的结果计算得到);而树状数组除了需要满足上述条件,还需要满足可抵消性,也就是可以通过一个操作抵消掉不需要区间的贡献(因为 BIT 只能维护前缀结果)。仅为个人见解
树状数组的经典例题及其技巧
模板题:单点修改,区间查询
思路:
非常简单,只需要套模板即可。
代码:
// 上述模板部分省略
using ll = long long;
const int maxn = 1e6+50;
ll f[maxn];
int main(){
ios::sync_with_stdio(0);
cin.tie(0);
int n; cin >> n;
int q; cin >> q;
for (int i = 1; i <= n; ++ i) cin >> f[i];
BIT<ll> bit(f, n);
for (int i = 0; i < q; ++ i){
int type; cin >> type;
if (type == 1){
int i, x;
cin >> i >> x;
bit.add(i, (ll) x);
}else {
int l, r;
cin >> l >> r;
cout << bit.sum(l, r) << '\n';
}
}
return 0;
}
模板题:区间修改,区间查询
思路:
该模板题则难上许多,需要对问题分析建模。
我们需要考虑如何建模表示 \(tree\) 数组。
首先,设更新操作为:在 \([l, r]\) 上增加 \(x\)。我们考虑如何建模维护新的区间前缀和 \(c^{\prime}[i]\)。
下面分情况讨论:
- \(i < l\)
这种情况下,不需要任何处理, \(c^{\prime}[i] = c[i]\)
- \(l <= i <= r\)
这种情况下,\(c^{\prime}[i] = c[i] + (i - l + 1) \cdot x\)
- \(i > r\)
这种情况下,\(c^{\prime}[i]=c[i] + (r-l+1)\cdot x\)
因此如下图所示,我们可以设两个 BIT,那么\(c^{\prime}[i] = \mathrm{sum(bit_1,i)+sum(bit_2,i) \cdot i}\),对于区间修改等价于:
- 在 \(bit_1\) 的 \(l\) 位置加上 \(-x(l-1)\),在 \(bit_1\) 的 \(r\) 位置加上 \(rx\)。
- 在 \(bit_2\) 的 \(l\) 位置加上 \(x\) 的 \(r\) 位置加上 \(-x\)。
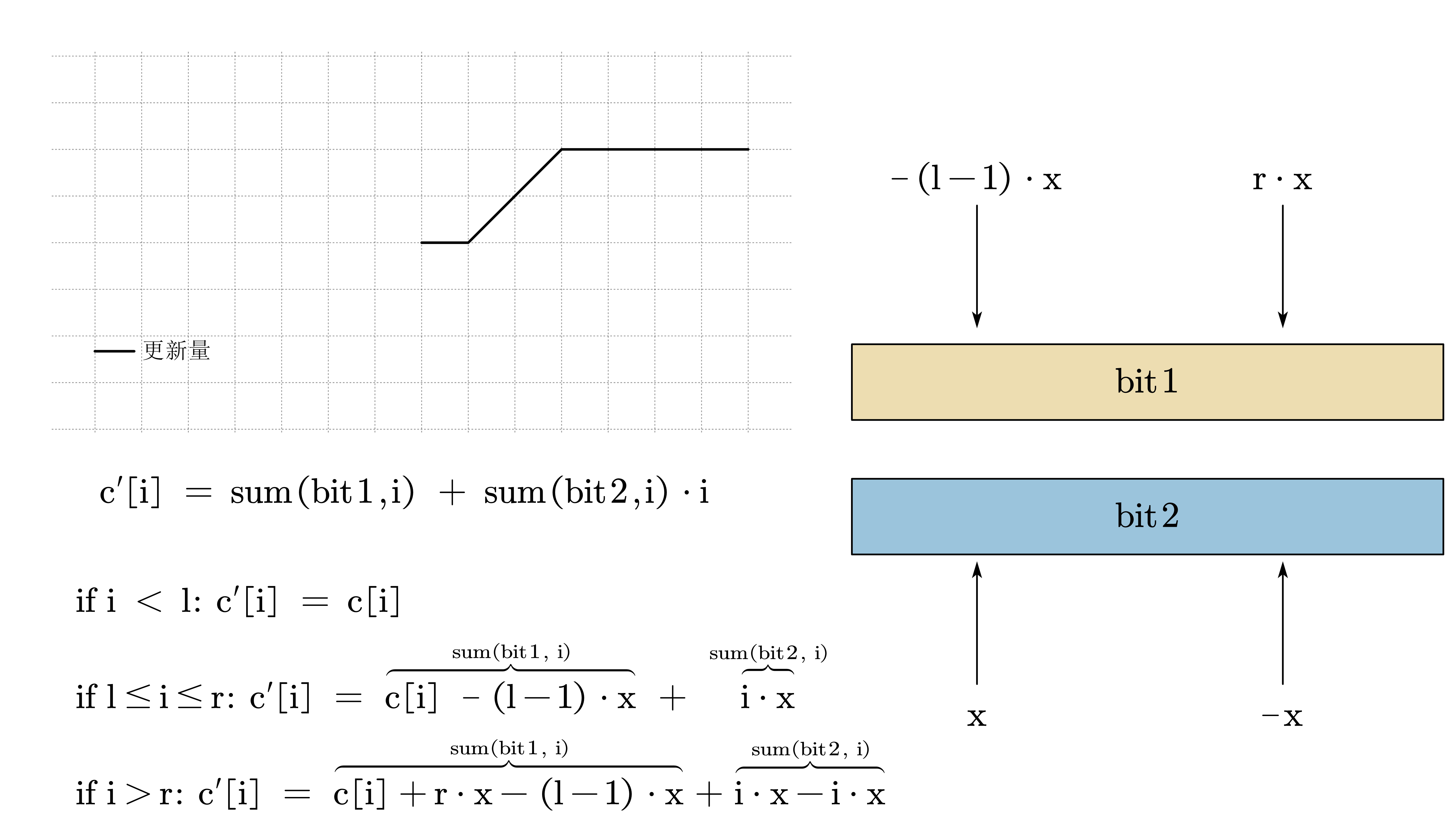
代码
#include <bits/stdc++.h>
using namespace std;
// 模板代码省略
// 这里做的是单点查询,但是实现的为区间查询
using ll = long long;
ll get_sum(BIT<ll> &a, BIT<ll> &b, int l, int r){
auto sum1 = a.sum(r) * r + b.sum(r);
auto sum2 = a.sum(l - 1) * (l - 1) + b.sum(l - 1);
return sum1 - sum2;
}
int n, q;
const int maxn = 1e6 + 50;
ll f[maxn];
int main(){
// ios::sync_with_stdio(0);
// cin.tie(0);
cin >> n >> q;
BIT<ll> bit1, bit2;
for (int i = 1; i <= n; ++ i) cin >> f[i];
bit1.init(n), bit2.init(f, n);
for (int i = 0; i < q; ++ i){
int type; cin >> type;
if (type == 1){
int l, r, x;
cin >> l >> r >> x;
bit2.add(l, (ll) -1 * (l - 1) * x), bit2.add(r + 1, (ll) r * x);
bit1.add(l, (ll) x), bit1.add(r + 1, (ll) -1 * x);
}else {
int i; cin >> i;
cout << get_sum(bit1, bit2, i, i) << '\n';
}
}
return 0;
}
逆序对 简单版
思路
BIT 求解逆序对是非常方便的,在初学时我没有想到过 BIT 还能用于求解逆序对。在这里我借逆序对来引出一个小技巧:离散化
BIT 求逆序对的方法非常简单,逆序对指:i < j and a[i] > a[j],统计逆序对实际上就是统计在该元素 a[i] 之前有多少元素大于他。
我们可以初始化一个大小为 \(maxn\) 的空 BIT(全为0)。随后:
- 我们顺序访问数组中的每个元素
a[i],计算区间[1, a[i]]的和,更新答案ans = i - sum([1, a[i]]) - 然后,我们更新 BIT 中坐标
a[i]的值,tree[a[i]] <- tree[a[i]] + 1
举个例子:
eg: [2,1,3,4]
BIT: 0, 0, 0, 0
>2, sum(2) = 0, ans += 0 - sum(2) -> ans = 0
BIT: 0, 1, 0, 0
>1, sum(1) = 0, ans += 1 - sum(1) -> ans = 1
BIT: 1, 1, 0, 0
>3, sum(3) = 2, ans += 2 - sum(3) -> ans = 1
BIT: 1, 1, 1, 0
>4, sum(4) = 3, ans += 3 - sum(4) -> ans = 1
实际上,便是借助 BIT 高效计算前缀和的性质实现了快速打标记,先统计在我之前有多少个标记(这些都是合法对),再将自己所在位置的标记加 \(1\)。
因此,很容易写出这段代码:
代码一
// 仅保留核心代码
int reversePairs(vector<int>& nums) {
int n = nums.size();
if (n == 0) return 0;
int mx = *max_element(nums.begin(), nums.end());
BIT<int> bit(mx); // 因为最大只到最大值的位置
int ans(0);
for (int i = 0; i < n; ++ i){
ans += (i - bit.sum(nums[i]));
bit.add(nums[i], 1);
}
return ans;
}
但是这个代码有非常严重的问题,首先假如 mx = 1e9 就会出现段错误;或者假如 nums[i] < 0 则会出现访问越界的问题,但是实际上题目中说明了:数组最多只有 50000个元素,也就是我们需要想办法将坐标离散化,保留其大小顺序即可。
代码二
#define lb lower_bound
#define all(x) x.begin(), x.end()
const int maxn = 5e4 + 50;
struct node{
int v, id;
}f[maxn]; // 离散化结构体
int arr[maxn];
bool cmp(const node&a, const node &b){
return a.v < b.v;
}
class Solution {
public:
int reversePairs(vector<int>& nums) {
int n = nums.size();
if (n == 0) return 0;
BIT<int> bit(n);
for (int i = 1; i <= n; ++ i){
f[i].v = nums[i - 1], f[i].id = i; // 赋值用于排序
}
sort(f + 1, f + 1 + n, cmp);
int cnt = 1, i = 1;
while (i <= n){
/* 用于去重,当有相同元素时其对应的 cnt 应该相同 */
if (f[i].v == f[i - 1].v || i == 1) arr[f[i].id] = cnt;
else arr[f[i].id] = ++cnt;
++ i;
}
int ans = 0;
for (int i = 0; i < n; ++ i){
int pos = arr[i + 1];
ans += i - bit.sum(pos);
bit.add(pos, 1);
}
return ans;
}
};
上面的方法是离散化操作的一种方式,有一点复杂,需要注意的细节比较多。
实际上,该方法便是通过保留每个元素的所在位置,并将其排序,排序后自己在第 \(i\) 个则将其值 arr[id] = i 离散化为 \(i\) 。这样既可以避免负数,过大的数造成的访问或者内存错误,也充分的保留了各元素之间的大小关系。
离散化的复杂度为 \(\mathcal{O(\log n)}\) ,实际上也就是排序的复杂度。
总结:离散化--结构体方法
通用性:★★
- 设置结构体
node,包含属性val与id,初始化结构体数组f和离散化数组arr。- 排序
f,并从1开始遍历,arr[f[i].id] = i,将val值更新为k-th min也就是其在元素中按大小排列的编号。
可以发现,结构体方法对于空间要求较大,且在去重方面需要下功夫,稍后我们会讲解另一种离散化方法,你也可以试试用后文的离散化方法再次解决这题。
逆序对加强版: 翻转对
思路
可以看到这题与逆序对的区别在于,翻转对的定义是:i < j 且 a[i] > 2*a[j] 。其大小关系发生了变化,不再是原来单纯的大小关系,而存在值的变化。
我们可以思考下能否用结构体进行离散化,简单思考后发现:假如第 i 个元素离散化之后的编号为 id1 ,则我们无法确定编号为 2 * id1 所对应元素的 val 值之间的关系。可能出现如下情况:
id1 = 1, val = 2
2 * id1 = 2, val' = 3
所以,我们需要思考一个新的方法来进行离散化。需要注意的是,我们的关键点在于:如何快速的询问一个元素在一个数组中是第几大的元素。比如,在数组中快速询问某个值的两倍是第几大的。
实际上,稍微有基础的话答案便非常清晰:二分查找,我们可以首先将数组进行排序,利用 \(lower_{bound}\) 快速找到第一个大于等于该元素所对应的位置,用代码来说的话:pos = lower_bound(nums.begin(), nums.end(), x) - nums.begin() + 1 。
eg: nums = [3, 2, 4, 7]
farr = sort(nums) -> farr = [2, 3, 4, 7]
pos(4) = lower_bound(..., 4) - farr.begin() + 1 = 3
便可以快速找到 4 的编号为 3 (1-index)
但是,有一个问题需要注意:
eg: nums = [3, 2, 5, 7]
farr = sort(nums) -> farr = [2, 3, 5, 7]
pos(4) = lower_bound(...,4) - farr.beign() + 1 = 3
但实际上,5 > 4,这次询问错误了!!!
为什么会出现询问错误的情况呢?(因此我们需要找到的是最后一个小于等于元素 x 的对应位置,而二分查找是大于等于 x 的第一个元素,当原数组中不存在 x 时,便会出现询问出错的情况。)
有多种方法可以解决这个问题,但是最为方便的还是直接将需要查询的元素全部加进去,也就是 2 * x 全部添加到数组中,从而保证一定存在该元素,又因为 lower_bound 的性质,我们无需去重。
代码
using vi = vector<int>;
using vl = vector<ll>;
#define complete_unique(x) (x.erase(unique(x.begin(), x.end()), x.end()))
#define lb lower_bound
class Solution {
public:
int reversePairs(vector<int>& nums) {
vl tarr;
for (auto &e: nums){
tarr.push_back(e);
tarr.push_back(2ll * e); // 直接把需要离散化的对应元素加入
}
sort(tarr.begin(), tarr.end());
int n = nums.size();
BIT<int> bit(2 * n); // 注意,因为加入了两倍的元素,所以对应也要开大一点
int res = 0;
for (int i = 0; i < n; ++ i){
res += i - bit.sum(lb(tarr.begin(), tarr.end(), 2ll * nums[i]) - tarr.begin() + 1);
bit.add(lb(tarr.begin(), tarr.end(), nums[i]) - tarr.begin() + 1, 1);
}
return res;
}
};
总结:离散化--二分查找方法
通用性:★★★★★
- 初始化数组
farr,将元素以及需要寻找的元素都加入其中- 二分查找即可。
二维BIT:区间查询,单点修改
思路
二维 BIT 实际上就是套娃,一层层套即可。
其复杂度为 \(\mathcal{O(\log n \times \log m)}\) ,\(n,m\)分别为每个维度 BIT 的个数,这里不再赘述。
代码
#include <bits/stdc++.h>
using namespace std;
// 模板代码省略
using ll = long long;
int n, m, q;
const int maxn = 5e3 + 50;
BIT<ll> f[maxn]; // 二维BIT
void add(int i, int j, ll x){
while (i <= n){
f[i].add(j, x);
i += lowbit(i);
}
}
ll sum(int i, int j){
ll res(0);
while (i > 0){
res += f[i].sum(j);
i -= lowbit(i);
}
return res;
}
signed main(){
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n >> m;
for (int i = 1; i <= n; ++ i) f[i] = BIT<ll>(m);
int type;
while (cin >> type){
if (type == 1){
int x, y, k; cin >> x >> y >> k;
add(x, y, (ll) k);
}else {
int a, b, c, d; cin >> a >> b >> c >> d;
cout << sum(c, d) - sum(c, b - 1) - sum(a - 1, d) + sum(a - 1, b - 1) << '\n';
}
}
return 0;
}
后记
这是我耗时最长的一篇博客,也是我花费心血最多的一次,也希望自己能好好掌握 BIT
附上参考链接:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号