
理解检索增强生成(RAG)
理解检索增强生成(RAG)
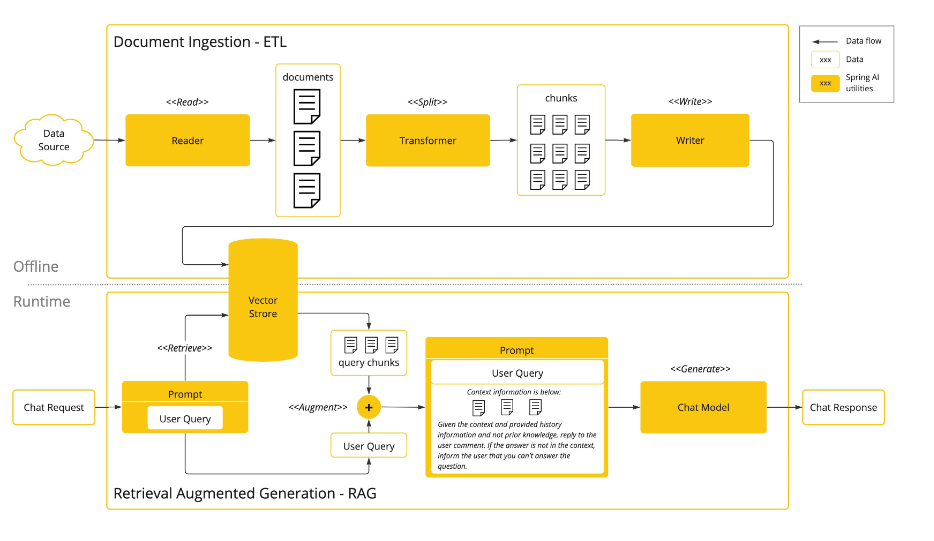
要理解这张图,我们可以将其拆分为两个核心阶段(离线文档处理 + 在线 RAG 推理),并逐一解析每个组件的功能和流程逻辑:
一、上方:Document Ingestion - ETL(离线文档摄入与处理,基于 ETL 流程)
这一阶段是 ** 为大语言模型准备 “知识底座”** 的过程,属于离线执行的环节。
-
Data Source(数据源):
指需要被处理的原始文档来源,比如企业知识库、PDF 文档、Word 文件等。
-
Reader(读取器):
负责从数据源中读取原始文档,将非结构化的文档数据加载到系统中。
-
documents(文档):
读取后的原始文档集合,此时还是完整的、未拆分的文档。
-
Transformer(转换器):
核心功能是拆分文档(<
>) —— 将完整的文档拆分成更小的 “文本块(chunks)”。拆分的目的是让后续的向量存储和检索更高效(避免因文档过长导致的信息丢失或检索不准确)。 -
chunks(文本块):
拆分后的小文本单元,是后续向量存储的基本单位。
-
Writer(写入器):
将拆分后的文本块 ** 写入向量存储(Vector Store)** 中,完成离线的文档处理流程。
二、下方:Retrieval Augmented Generation - RAG(在线检索增强生成,即 RAG 流程)
这一阶段是基于用户请求生成智能回答的在线环节,核心是 “先检索知识,再生成回答”。
-
Chat Request(用户请求):
用户发起的问题或查询,比如 “请解释 Spring AI 的文档摄入流程”。
-
Prompt - User Query(提示 - 用户查询):
对用户请求的封装,作为后续检索和生成的输入。
-
Vector Store(向量存储):
存储着离线阶段拆分好的文本块的向量表示(文本通过嵌入模型转化为高维向量,便于语义相似性检索)。
-
<
>(检索) :根据用户查询的向量,在向量存储中检索最相关的文本块(query chunks)—— 这一步是 RAG 的 “检索” 核心,确保模型基于最新 / 最相关的知识回答。
-
<
>(增强) :将检索到的相关文本块与 “用户查询” 结合,构建更丰富的提示(Prompt)。
-
Prompt(最终提示):
包含 “用户查询 + 检索到的上下文信息 + 回答规则”(如 “基于上下文且不依赖先验知识回答;若无答案则告知用户”)。
-
Chat Model(聊天模型):
大语言模型(如 GPT、开源 LLM 等),接收 “增强后的提示” 并生成回答。
-
Chat Response(聊天响应):
模型返回的最终回答,是结合了检索到的知识和模型推理能力的结果。
三、整体逻辑总结
这张图完整展示了 “离线构建知识底座 → 在线基于知识生成回答” 的 RAG 全流程:
- 离线阶段:通过 ETL 流程(读取→拆分→写入向量存储)将原始文档转化为可检索的文本块;
- 在线阶段:用户发起查询后,先从向量存储中检索相关知识,再将知识与查询结合成提示,最终由大语言模型生成精准回答。
这种架构的核心价值是让大语言模型具备 “实时调用外部知识” 的能力,既解决了模型 “知识过时” 的问题,又保证了回答的准确性和相关性,广泛应用于企业智能问答、知识库助手等场景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号