Java的第二次博客作业
一.前言
1.对三次题目集的总体概况:
题目集4和5都有一道难度相当大的题目,题目集6可以说是非常的简单了。三次题目集的题目量都不多,关键还是在难度上面。
2.题目集4:
第一道水文数据处理题需要考虑很多细节,各种可能出现输入错误的情况都需要在代码中去实现,很遗憾我没有考虑完全,仍然有一个测试点没有通过,在写这道题的时候最大的折磨就是反反复复去测试到底是哪些输入错误自己没要考虑到,当然这也是因为最开始的时候自己没有仔细看指导书,忽略了许多细节,后期再来调试需要更多的精力;第二道日期题是挺简单的,对照类图敲代码就可以了,但是具体在类DateUtil中有几个方法我并没有用的很好(这也是因为后面题目集5也有一道相似的题,让我看到了题目集4这道题我代码写的很烂);第三道图形继承题也是比较简单的,题目中虽然没有类图,但有很多指导文字,照着敲代码也是可以很轻松写出来的。
3.题目集5:
第一、二道题是很基础的题,也是老师让我们产生成就感的题(实际我感觉没啥用....);第三题的排序题,在此之前我一直用的冒泡排序法,对插入排序法和选择排序法只是浅入了解过,真正要写的时候发现还是有点困难的,于是CSDN,深入了解了一下这三种排序方法,每种排序方法有各自的优点和缺点(具体分析在下面‘设计与分析’中);第四题的统计关键词出现次数是这次题目集中最最最折磨人的了,第一遍写完的时候,将输入样例进行测试,完美通过!!!但是,提交了,竟然一个测试点都没有通过.....顿时我我感觉是不是PTA出问题了,但是一排排的答案错误告诉我并不是,于是开始了长达5天的测试测试测试,可惜还是有两个测试点没有通过。
4.题目集6:
题目集6真的可以算是让自己感觉很有成就感(如果不看PTA排名的话,好多好多满分的....)。虽然有六道题目,但是真的容易,唯一存在疑惑的地方就是第五道题的toString()这个方法自我感觉用的不是很好,甚至是多余了。
二.设计与分析
提示:以下所以类图和SourceMonitor的生成报表中的test类均为测试类。
1.题目集4(7-2)、题目集5(7-5)两种日期类聚合设计的优劣比较:
设计:两道题都是设计如下几个类:DateUtil、Year、Month、Day,其中年、月、日的取值范围依然为:year∈[1900,2050] ,month∈[1,12] ,day∈[1,31] ,输入格式各有不同(具体不详述),判断是否非法
应用程序的三个功能:
- 求下n天
- 求前n天
- 求两个日期相差的天数
题目集4(7-2)类图如下:
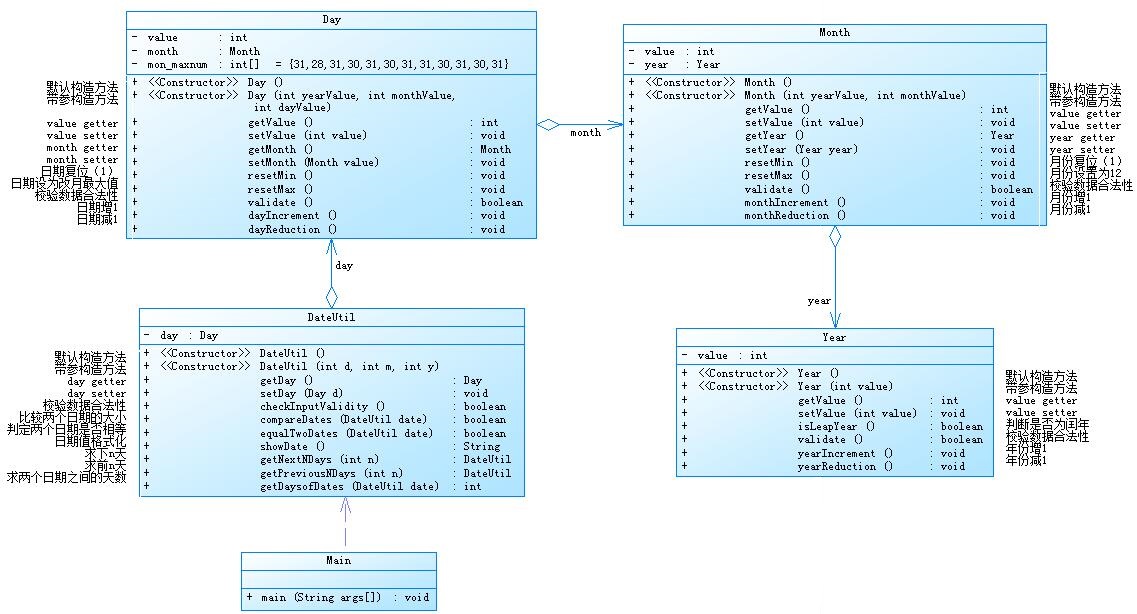
SourceMonitor的生成报表如下:
可见主类的复杂度很高,Date的复杂度也很高(test类为测试类)。
题目集5(7-5)类图如下:
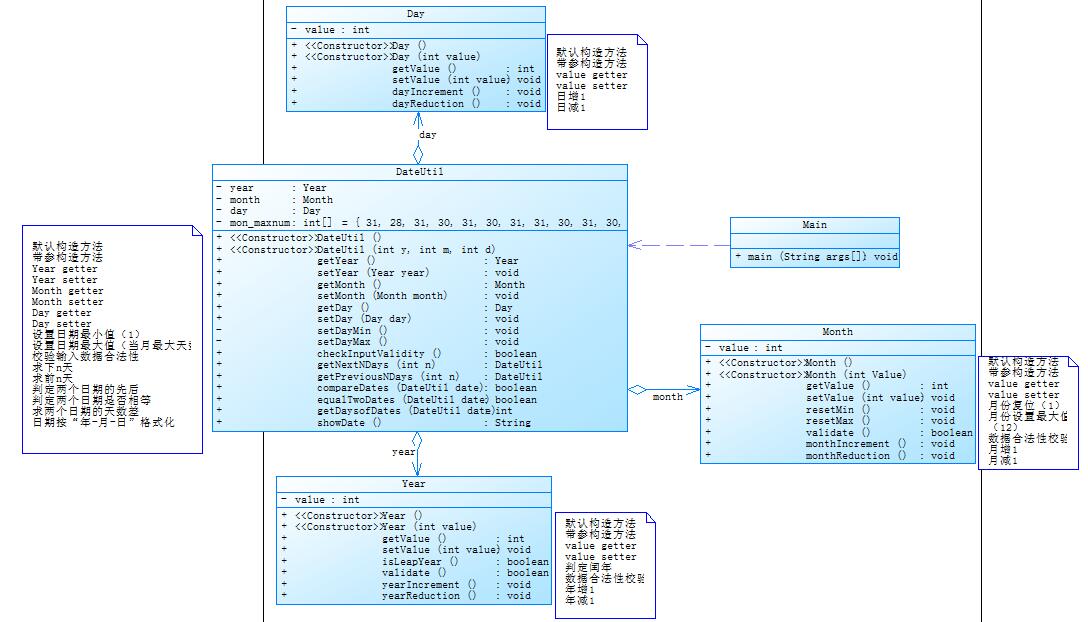
SourceMonitor的生成报表如下:

可以看出复杂度相比之前降了很多尤其是主类。
(1)自我感受和踩坑心得:
正如之前所说,在题目集4(7-2)中我所写的代码是相当糟糕的,其一,在写这道题的时候我对类图的了解也并不深入加上那段时间在看阿里巴巴编程手册,其中的有一个要求就是在写方法的时候若无需要不能写public和private等修饰关键词,我写属性的时候想当然也用这个标准去写了,所以写的代码与题目所给类图要求严重不一样;其二,写这道题的类DateUtil的时候写一半又去弄其他的东西,时间间隔又太长,导致写的方法有几个完全没有用到。这在题目集5(7-5)深深体会到了,之前写的代码啥都不是,题目所给类图里面的方法一定有其作用的,如果没有用到,一定是设计不够完美。
(2)优劣比较:
第一道题中日期类,年类,月类,日类都息息相关,耦合度太高,这不太符合面向对象的原则,第二道题就好很多,但是第一道题目很考察对于类和对象的知识的掌握;就个人而已我觉得第一道题中对数据合法性校验的处理更好一些,尤其是在闰年二月最大天数的改变上,第二道题因为这个我纠结了挺久,也还是没有找到非常好的处理方式,只能采用蠢办法,没判断一次就加一次改变.....;复杂度的话,我第一题写的代码很混乱,复杂度大了很多,如果重新写一遍,相比两者复杂度相差不会很大。
(3)一些小设计:
第一道题求二者相差的天数,写的时候因为上面说的原因我忘记用已经写过的几个方法,完全是重新写了一个求二者相差天数的方法,我用到了Math.max和Math.min来获得日期大的和日期小的(这个自我感觉还可以,但是可以用上面写过的比较日期大小的方法),然后我再把年份,月份,日子相差的天数分别求出来并相加得到相差的天数(这点完全是可以用从一个日子加n天或者减n天到另一个日子,再返回n的);第二道题有个测试点是关于整型数最大值的,

我尝试了在求前n天的方法中用long型和biginteger但都还是运行超时(我判断是循环次数过多导致超时),最后我通过了一个先判断n是否大于400年的天数(),然后在减掉a个400年的天数在进入循环,最后返回的年数再加a*400。部分代码如下:
DateUtil getNextNDays(int n) { //求下n天 int a = n / 146097; int n1 = n; if(n > 146097) { n1 = n - 146097*a; } for(int i = 0;i < n1;i++) { if(year.isLeapYear()) { mon_maxnum[1] = 29; } else { mon_maxnum[1] = 28; } day.dayIncrement(); if(day.getValue() > mon_maxnum[month.getValue() - 1]) { setDayMin(); month.monthIncermenrt(); if(month.validate() == false) { month.resetMin(); year.yearIncrement(); } } } DateUtil data = new DateUtil(year.getValue() + a*400,month.getValue(),day.getValue()); return data; }
2.题目集4(7-3)、题目集6(7-5、7-6)三种渐进式图形继承设计的思路与技术运用(封装、继承、多态、接口等)
题目集4(7-3):
类图如下:
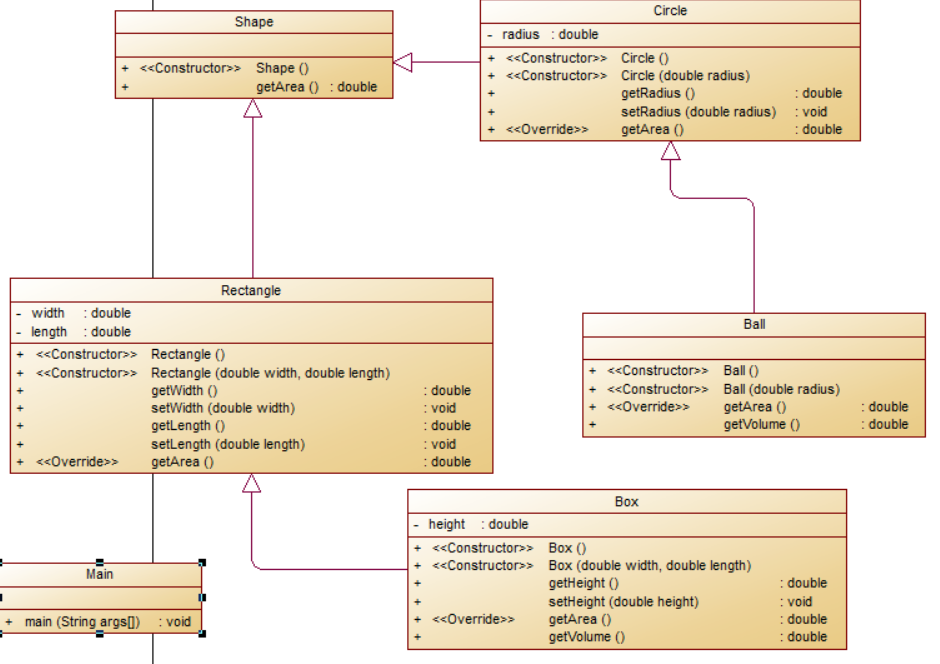
由类图可以看出类Circle和Rectangle都是继承类Shape的,而类Ball和Box又是分别继承类Circle和Rectangle的,这几个类的所有属性都是私有的封装起来了调用均使用get和set,而每个类对象每个图形的getArea方法也是重写各自父类的getArea方法,每个类的构造方法中也是按题目要求“每个类均有构造方法,且构造方法内必须输出如下内容:Constructing 类名”比如以下部分代码
public Circle(double radius) { super(); this.radius = radius; System.out.println("Constructing" + " Circle"); }
其中“System....”语句一定要写在super()的后面,只有这样super()才是调用父类的构造方法,每个类大体都是这样的思路,而主类中是用正则来判断合法性,若合法再进入下一步的判断图形并输出相应值,正则的具体用法将在“二.设计与分析 3.”中具体分析。
踩坑心得:子类构造方法的super()一定要写在方法下面的第一句
题目集6(7-5)
类图如下:
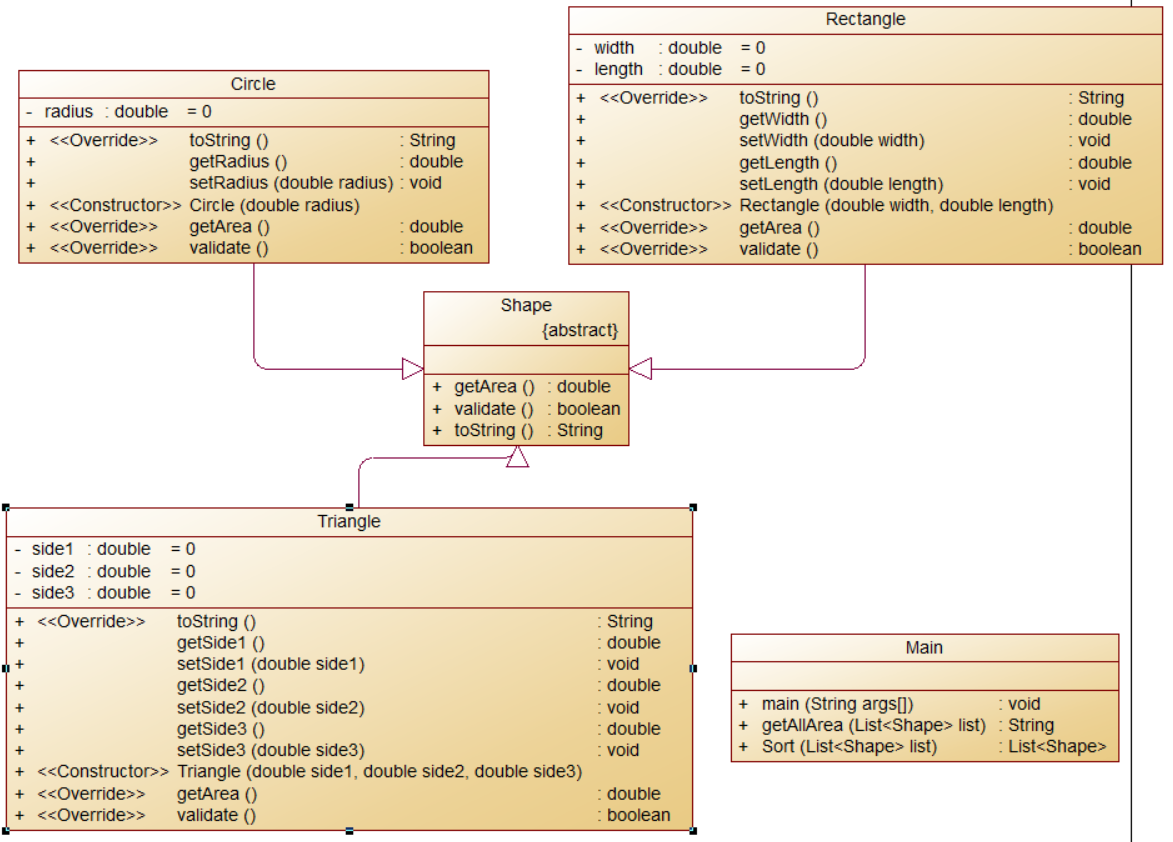
由类图可以看出类Shape是一个抽象类,Circle,Rectangle,Triangle都是其实例化的子类,所以后三者的方法toString,getArea和validate都是重写于Shape,说实话我并不明白toString的作用是什么(在这里我只有保留两位小数这个功能),感觉toString我是为了用而用,因为指导书里面有这个,实际上我感觉不用更方便;指导书上黑体字排序要求“根据图形的面积大小进行升序排序,要求必须对 list 中的图形对象在 list 中进行排序,而不 是对求得的面积进行排序,排序后再次求出各图形的面积并输出。”和红色字“此处建议大家考虑该排序方法以及求得所有图形面积总和的方法应该设计在哪个类中?”
我的理解是排序是根据图形的面积进行对象与对象的排序然后在输出,排序方法以及求得所有图形面积总和的方法我是放在主类中,使用排序方法中我是先传入原图形集合(list),然后进行排序后返回一个排好序的图形集合并赋值给一个新的图形集合(newlist),然后安装newlist在进行输出。
主类代码如下:
public class Main { public static void main(String[] args) { Scanner in = new Scanner(System.in); int a = in.nextInt(); int b = in.nextInt(); int c = in.nextInt(); double sumarea = 0; List<Shape> list = new ArrayList<Shape>(); List<Double> areas = new ArrayList<Double>(); boolean flag1 = true; boolean flag2 = true; boolean flag3 = true; for(int i = 0;i < a;i++) { Shape aa = new Circle(in.nextDouble()); flag1 = aa.validate(); list.add(aa); } for(int i = 0;i < b;i++) { Shape bb = new Rectangle(in.nextDouble(),in.nextDouble()); flag2 = bb.validate(); list.add(bb); } for(int i = 0;i < c;i++) { Shape cc = new Triangle(in.nextDouble(),in.nextDouble(),in.nextDouble()); flag3 = cc.validate(); list.add(cc); } if(a < 0 || b < 0 || c < 0 || flag1 == false || flag2 == false || flag3 == false) { System.out.println("Wrong Format"); System.exit(0); } System.out.println("Original area:"); for(int i = 0;i < list.size();i++) { System.out.print(list.get(i).toString()); } System.out.println("\nSum of area:" + getAllArea(list)); System.out.println("Sorted area:"); List<Shape> newlist = Sort(list); for(int i = 0;i < newlist.size();i++) { System.out.print(newlist.get(i).toString()); } System.out.println("\nSum of area:" + getAllArea(newlist)); } public static String getAllArea(List<Shape> list) { //求总面积 double sumarea = 0; for(int i = 0;i < list.size();i++) { sumarea += list.get(i).getArea(); } return String.format("%.2f", sumarea); } public static List<Shape> Sort(List<Shape> list){ //排序 for(int i = 0;i < list.size();i++) { for(int j = 0;j < list.size() - i - 1;j++) { if(list.get(j).getArea() > list.get(j+1).getArea()) { Collections.swap(list, j, j+1); } } } return list; } }
踩坑心得:本题中我对数据的校验一开始只有一个flag,导致我第一个数据非法flag为false,但是第二个合法,flag又变成的true,造成判断错误。
改进:要深入理解toString的在本题的作用,应该可以让代码简洁很多。
题目集6_7-6
类图如下:
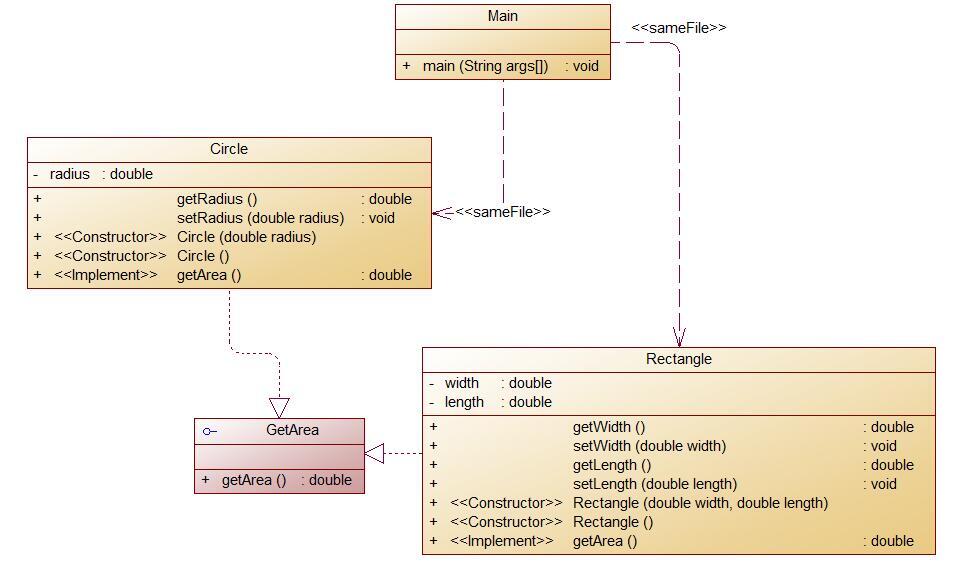
由类图可以看出GetArea是一个接口,该接口只有一个抽象方法getArea,而Circle和Rectangle是实现接口的类(一定要把接口中的抽象方法具体化,也就是重写)和接口是继承关系,这两个类中的属性也全部都是私有的。
3.对三次题目集中用到的正则表达式技术的分析总结
(1)用于检查数据合法性的常用macher()方法或find()方法,代码如下:
String str = in.next(); String pattern = "[0-9]{1,10}['.'][0-9]{1,10}"; Pattern r = Pattern.compile(pattern2); Matcher m = r.matcher(getData()[3]); if(m.maches()) //判断字符串字符是否与正则表达式匹配 if(m.find()) //判断字符串中是否含有匹配正则表达式的
(2)也有时候会用split()方法来分割字符串比如那道水文题,其中部分代码如下:
//分割一行水文数据的每个信息
public String[] getData() { String[] str = data.split(" *\\| *"); return str; }
(3)从字符串中获取自己想要的部分字符串,可以用group(),其中部分代码如下:
String str = "45/646/dg"; List<String> list = new ArrayList<String>(); Pattern r = Pattern.compile("\\d+"); Matcher m = r.matcher(str); while(m.find()) { list.add(m.group()); }
(4)踩坑心得
- 有一个正则表达式运行起来会一直超时,经查阅各种资料也不知道为啥,代码如下:
newinput = newinput.replaceAll("(/\\*)(\n*.*?)*(\\*/)", " "); //newinput = newinput.replaceAll("(/\\*)(\n*.*)(\\*/)", " ");后续改成下面那行就不会超时了,本人推测是在下划线那部分持续判断出不来导致的
- 有时候find()和maches()会用混淆
- 慎用正则表达式的" () "和" | "
4.题目集5(7-4)中Java集合框架应用的分析总结
(1)分析:本题我用的是Map,其中集合的元素为<String,Integer>,前者为关键词的字符串形式,后者为关键处出现的次数,用put()方法来讲元素存到map中,Map中第一个元素为key值,第二个元素为value值,key值唯一,而value值可以不唯一,然后可以通过get()方法有key值返回value值。具体使用的代码如下:
for(int i = 0;i < 53;i++) { int n = 0; Pattern r = Pattern.compile("[^a-zA-Z\\d]" + keyword[i] + "[^a-zA-Z\\d]"); Matcher m = r.matcher(newinput); while(m.find()) { n++; } map.put(keyword[i],n); if(n > 0) { System.out.println(map.get(keyword[i]) + "\t" + keyword[i]); } }
keyword为关键词字符串数组,n为输入的源代码中关键词出现的次数,在for循环中先使用正则匹配输入源代码中第一个关键词的次数(由while循环来确定n的值),然后在将keyword[i]和n存到map中,其次判断关键词次数是否大于0,若大于0则输出相应的语句(其中"map.get(keyword[i])"就是map中通过key值返回value值的使用),一共for循环53次,得到所有关键词出现的次数。
(2)踩坑心得:key值和value值的使用很容易搞反一定要细心!
三.总结
1.做题总结:
(1)做题尽量一次性做完,尤其是写代码比较多的题目,不然很容易忘记一些自己写过的方法,对之前设计的结构也会印象较浅,导致前后思路不一样;
(2)题目的信息要看完全,题目所给信息几乎没有用不上的,如果有,可能就是设计不到位,走了弯路,要反思自己;
(3)做有类图的题目时,可以先尝试不看类图,自己思考一下自己认为的类图应该是怎么样的,然后与题目所给类图对比,看看自己的想法和题目类图的差异并思考题目的类图为何那么设计,自己又在哪方面缺少了这种思想。
2.建议
(老师中午多吃点饭,上课声音大一点点)?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号