

ElasticSearch
视频学习地址:https://www.bilibili.com/video/BV1LF411j7rm/?p=8&spm_id_from=pageDriver&vd_source=12d06e602c3462c026d1a4781241f2d4

倒排表:有存储 就会有数据量大的问题,怎么去解决数据量大的问题:1.压缩大数据变成小数据(压缩算法) 2.如何存数据让查询更快(数据结构)
如图 posting LIst 匹配到了100w条的数据

倒排表算法_Frame Of Referenct压缩算法 :适用稠密数组
倒排表存储结构为有序数组 所以现在有了100w的int, 1个int类型占用4个字节 100W就是3.8MB的数据 这还只是匹配一个 如果100w的原始文本 每个文本差不多相同 所以拆分出来的词项匹配都相同
每一个原始数据都会被拆分成词项 如果原始数据为100Wt条 因为拆分里面的词 可能会导致 倒排表的数据比原始表还多
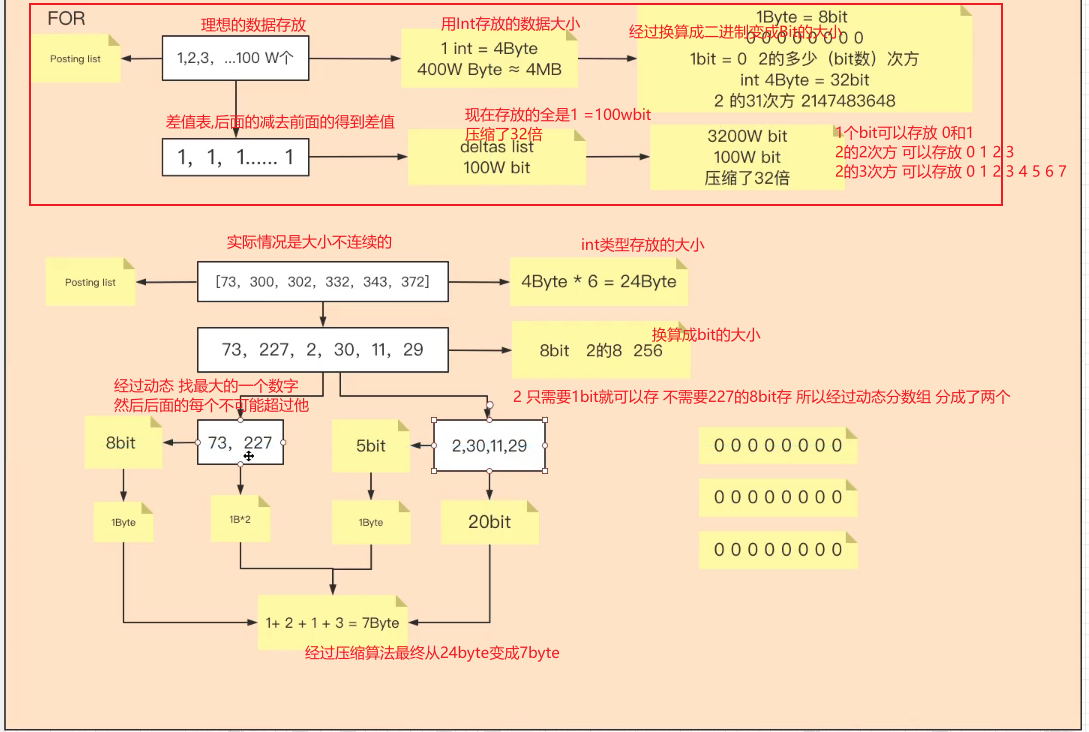
倒排表算法_RoaringBitmap压缩算法:适用稀疏数组 数组的差值比较大

如图得到的倒排表 词典数组是这样的 就用RBM算法
一个int类型 32位整形 32bit =2的16次方*2的16次方相乘 int的最大值 不会超过2的32次方

FST的构建过程:https://www.bilibili.com/video/BV1LF411j7rm?p=11&spm_id_from=pageDriver&vd_source=12d06e602c3462c026d1a4781241f2d4
理解数据结构:前缀树和 FST有限状态转换机

Lucene字典原理:FST在Lucene的构建原理,:https://www.cnblogs.com/LBSer/p/4119841.html
本文来自博客园,作者:12不懂3,转载请注明原文链接:https://www.cnblogs.com/LZXX/p/16893043.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号