
数据采集与融合技术实验报告一
数据采集与融合技术-实验报告一
姓名:刘心怡 学号:031904134 班级:2019级大数据一班
作业①
1) 实验内容及结果
实验要求: 使用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的指定数据。
代码链接:https://gitee.com/lyinkoy/crawl_project/blob/master/%E4%BD%9C%E4%B8%9A1/1.py
运行结果:

2) 心得体会
在实验一的作业一中,我原本使用了urllib.request库,但发现使用该库爬取数据后即使使用"utf-8", "gbk"去解码输出结果仍旧乱码,因此我最终还是使用我更为熟悉的requests库完成的该作业,而在选取目标数据时,我也适当的使用正则表达式来选取所需数据,最后为了使排版整齐,使用tplt,format(,chr(12288))方式,在这个作业的实践中,我对网页结构有了更深的了解,并且对爬虫设计也有了更进一步的了解。
作业②
1) 实验内容及结果
实验要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
代码链接:https://gitee.com/lyinkoy/crawl_project/blob/master/%E4%BD%9C%E4%B8%9A1/2.py
运行结果:


2) 心得体会
本次实验要求使用用requests和Beautiful Soup库方法设计爬取网站数据,而在最开始我就点开了错误的网站(内容只有一张gif图像),耽误了很多时间,最后还是询问助教老师才找到正确网页地址并且开始爬取,这个网站比上一个结构更加清晰,所以设计结构也会简单许多,但是在最后还是因为将数据类型弄混而导致出现‘NavigableString‘ object has no attribute ‘select’错误,最后还是经过同学提醒发现那些爬取下来的数据并非全部能.Strip()强制转换类型,最后才让数据完整而正确无误的输出,在这次实验中我注意到了许多之前我未曾注意的东西,收益颇丰。
作业③
1)实验内容及结果
实验要求:使用urllib和requests爬取(https://news.fzu.edu.cn/),并爬取该网站下的所有图片
代码链接: https://gitee.com/lyinkoy/crawl_project/blob/master/%E4%BD%9C%E4%B8%9A1/3.py
运行结果:
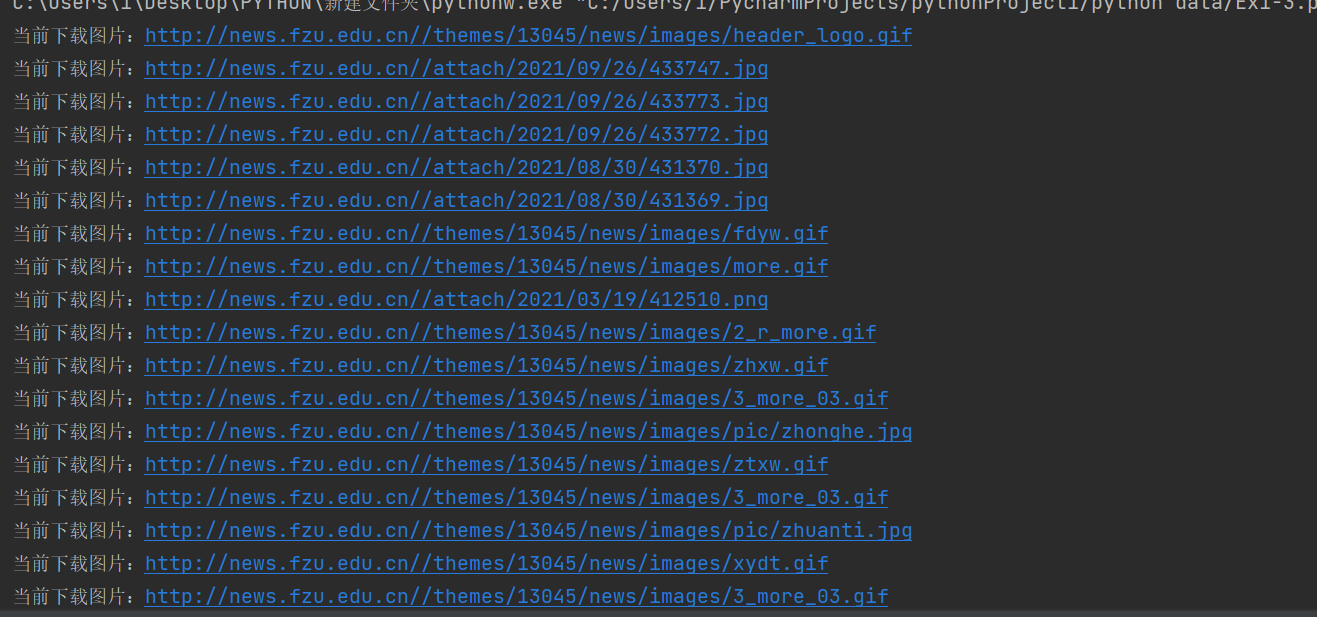
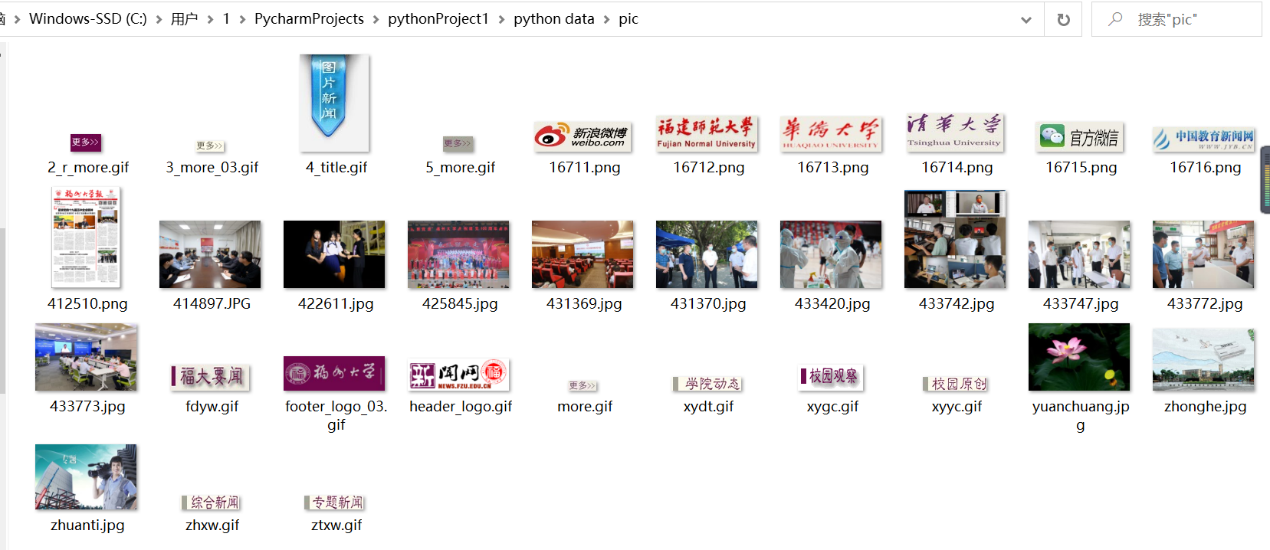
2)心得体会
本次实验涉及图片爬取,而在最开始通过查阅网页文档内容后就发现,该网页全部图片内容均在img中,且格式均为”<img src=/……>”,便由此依据设计了正则表达式r'<img src="(.*?)"',使用其我能正确的爬出全部的图片url,但在爬取图片过程中我因为忘记在爬出的图片url前补上完整的网址导致之前无法爬出内容,而在加上之后才能,而在某一版作业中还出现过筛选jpg格式图片的内容,由此我也认识到字符匹配的结果boolean值不可直接作为if判断内容,而因为爬取的内容为图片,图片大小不好控制,而为保证下载的质量,结合最近学过的线程内容,我加上了‘time.sleep(3) #设置线程休眠时间’语句以控制其运行,获益颇丰。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号