

So-VITS项目解读
So-VITS项目解读
目录
1.声音编码器;
2.预训练底模;
3.HIFIGAN增强器;
4.预处理部分;
5.网络结构;
1.声音编码器:
Contentvec:经过改造的Hubert模型,用于从语音中提取说话的内容特征,同时去除说话人的信息,具备帧级的对齐功能;
Hubertsoft:一种基于Hubert模型的内容编码器,输出的是一组连续的向量,表示语义特征;
Whisper-ppg:是OpanAI的Whisper模型中提取的中间表示,能够提取语音中的语义+音素的特征表示,同时去除说话人特征;
Cnhubertlarge:针对中文语义任务专门训练的大型hubert模型变体,使用了大量的中文语音数据进行训练;
Dphubert:全称Dual-Path Hubert,是一种结合Dual-Path结构的Hubert自监督语音内容编码器;
WavLM:由微软提出的自建毒学习的语音预训练模型,同时兼容内容和说话人特征的捕捉,也是基于Hubert改进的模型
OnnxHubert:将Hubert模型导出为ONNX格式后的版本
这里的声音编码器与ASR模型的功能不同:ASR模型需要输出语音的具体内容,而这些声音编码器输出的只是表示语义和音素特征的向量,实际上都是在语音中做无监督的预训练(除了Whisper和WavLM),所以不能输出具体说了什么。而Whisper-ppg虽然是有监督的学习,但是这里只需要整个模型的一部分,所以输出的还是特征向量而不是具体内容;
注意选择声音编码器的时候要考虑自己的数据集的语言范围:
| 声音编码器名称 | 支持语言范围 |
|---|---|
| Contentvec | 主要为英文,部分版本支持多语言 |
| Hubertsoft | 主要为英文 |
| Whisper-ppg | 支持100多种多语言 |
| Cnhubertlarge | 主要为中文 |
| Dphubert | 主要为中文,也有版本支持多语言 |
| WavLM | 主要为英文 |
| OnnxHubert | 与Hubert原版一直,支持英文 |
2.预训练底模:
仓库中提到的底模有三个文件,其中G_0.pth为生成器预训练权重,D_0.pth为判别器预训练权重,model_o.pth为扩散模型预训练权重(本文没讲扩散模型),是在别人训练好的模型上进行微调,能够减少训练成本;
3.HIFIGAN增强器:
HiFi-GAN增强器是语音合成任务中常用的高保真音频生成模型,广泛用于将梅尔频谱图转换为波形音频,通常作为后处理器。这个网络的输入是梅尔频谱,基于GAN的网络结构,生成高质量的波形音频,有降噪,提升清晰度等功能。这里使用的NSF-HiFiGAN是已经预训练好的模型,直接用来提升音频质量。
这里以原始的HiFi论文为例讲解一下原理,地址为:https://arxiv.org/abs/2010.05646.
HiFi-GAN包含了一个生成器和两个判别器:多尺度判别器和多周期判别器。同时还引入了两个额外的损失函数以提升模型的稳定性和性能。
生成器是一个卷积神经网络,以Mel频谱图为输入,通过转置卷积进行上采样,知道输出序列的长度和原始波形的时间分辨率能够匹配,然后在每一个转置卷积后面接一个多感受野融合模块(MRF),MRF就是返回多个残差块的总和,每个残差快使用不同的卷积核大小和膨胀率,从而能够融合多样的感受野。这个生成器不会接受额外的噪声作为输入。
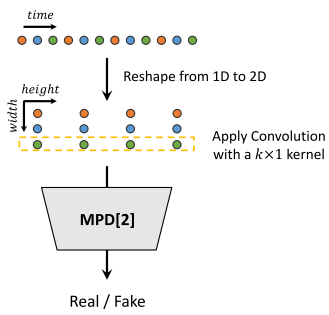
多周期判别器(MPD)是由多个子判别器组成的混合体,每个子判别器只接受输入音频里面等间隔的采样信号,每个间隔对应一个子判别器。这里根据周期把原来的一维数据重塑成二维数据,例如,长度为T的一维波形,被重塑成了(T/p)*p的二维数组,可以相当于从前p个起点开始都采样一次,然后得到的序列拼接成二维数组。之后再对这个二维数组进行二维卷积,在这里的卷积层中,我们限制卷积核的宽度为1,以便独立处理周期性的采样点。这里的子判别器接收不同的二维音频数据,输出若干个判别特征图,也就是在不同时间步的置信度,最终将所有置信度的结果结合起来形成最终的判别结果。
这里可以直接给出原文的可视化图来便于理解:
多尺度判别器(MSD)是用来评估连续音频序列的,这里借鉴了MelGAN,由三个子判别器组成,分别作用于不同尺度的输入:原始音频、经过2倍平均池化的音频和经过4倍平均池化的音频。这里的每个子判别器都是由带步幅和分组卷积层堆叠而成,激活函数为Leaky ReLU。
这里的判别器损失函数基本和GAN的目标一样。在GAN目标之外,还引入了Mel频谱损失作为生成器的损失函数,通过计算生成音频的Mel频谱和目标音频的Mel频谱之间的L1距离来稳定对抗训练的过程。
这里对生成器还引入了特征匹配损失,从判别器中提取每一层的中间表示,计算真实样本和条件生成样本在每一层的特征表示的L1距离,然后加权求和,形成特征匹配损失。这里的权重就是当前层的通道数的倒数。
在So-VITS-svc的官方仓库中,给出的是NSF-HiFiGAN声码器。这个模型引入了“源-滤波”的机制来模拟人类发声的连各个组成部分:1.声源:由一个振荡器模块生成周期信号;2.声道滤波器:利用神经网络对声源信号进行调制和增强。这里不仅仅用了Mel频谱,还引入了F0特征。这里添加的两个模块都是对生成器的改进,判别器还是和原来的一样。本文主要是对svc模型的网络结构讲解,这里先不讲HiFIGAN的网络结构。(之后会讲解最新的提高音质的网络)
4.预处理部分:
So-VITS-svc中,数据预处理分为:音频切片,重采样,划分训练、验证集和生成Hubert和F0这几步。
1.音频切片:将长时间的音频切割成合适的短片段,因为太长的训练音频可能会导致显存爆炸和学习困难,这里要求先用切片工具把音频切成几秒钟的子片段。如果音频里面可能存在几秒钟的停顿,可以利用能够检测静音区的切片工具。
2.重采样:这里要求重采样到44100Hz单声道,用于统一输入结构。
3.划分训练、验证集:这里要注意划分的时候要根据语言选择编码器,默认为vec768l12,支持的英语。
4.生成Hubert和F0:Hubert为语音内容特征,F0为音高\基频信息。
5.网络结构:
这里会先列出完整的网络结构,然后在详细讲解各个子模块的具体网络结构;
5.1 生成器:
这里先给出生成器的网络架构:
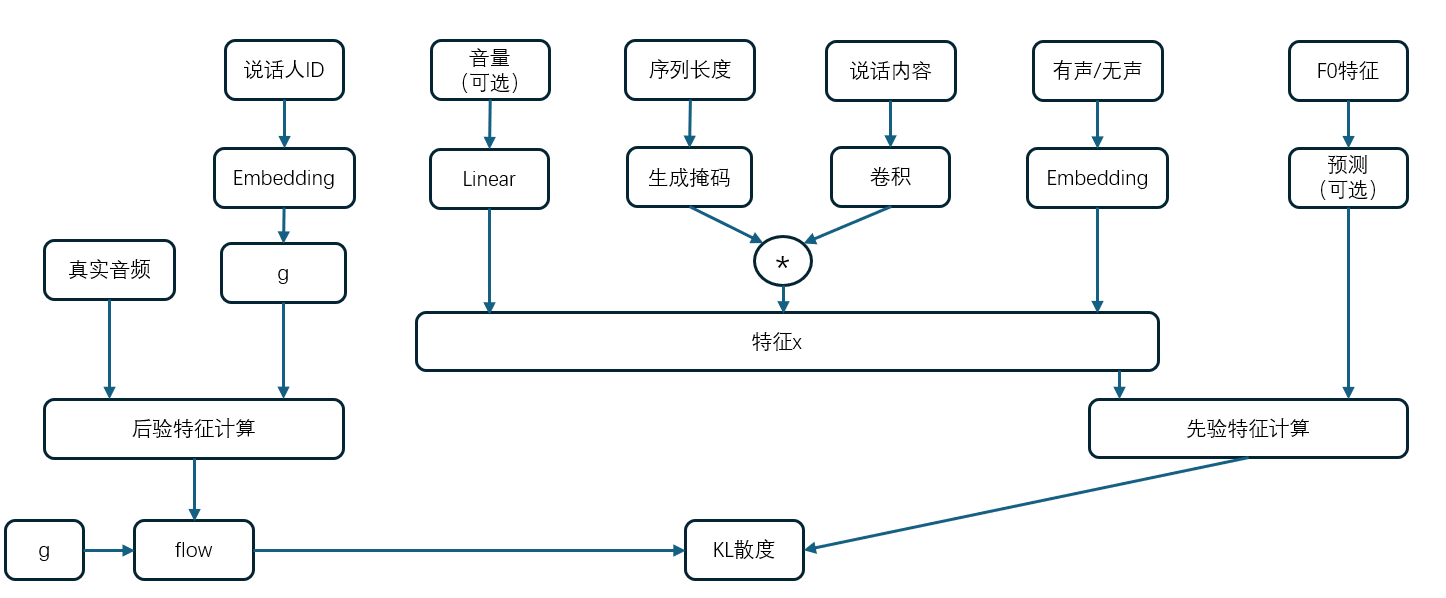
其中,先验数据是目的是通过文本来输出语音特征,训练的目标就是训练先验编码器通过说话内容输出对应的音频。同时,训练的时候解码器是接受后验特征进行输出音频的,这里用了teacher forcing的思想,目的是让编码器能够学到准确的生成音频的方法。
在推理的时候禁用了后验编码器,直接用先验编码器的输出作为解码器的输入。这里将详细介绍先验编码器、后验编码器和最终的解码器。
先验编码器的模型为:

其中z是根据预测的均值和方差的高斯分布采样得到的。
后验编码器的模型为:
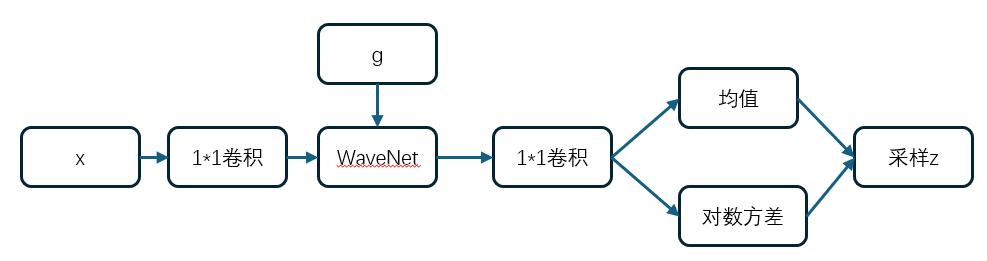
这里面的WN的WaveNet风格的残差卷积堆叠,并且支持了条件输入。
在这里,直接把NSF-HiFiGAN作为解码器,这里的输入就不再是Mel频谱图,而是后验产生的z的随机采样,用来生成对应的音频,也就是用了teacher forcing的方法。
5.2 判别器:
这里是判别器就是一个标准的判别器和一个多周期判别器。其中,标准的判别器使用1D的卷积提取特征,多周期判别器与HiFIGAN的多周期判别器一样,这里就不多做解释。
5.3 损失函数:
这里的判别器损失使用的是LSGAN风格的判别器损失函数,使用最小二乘误差来衡量距离,使得真实样本输出越接近1越好,生成样本输出越接近0越好。
生成器的损失函数包括多项,这里一一解释:
1.loss_gan:判别器反馈的损失,用来鼓励生成器骗过判别器;
2.loss_fm:特征匹配损失,让生成器中间特征更加接近真实图片;
3.loss_mel:生成音频和真实音频的Mel频谱L1损失
4.loss_kl:后验经过flow和先验得到的隐变量的KL散度损失
5.loss_lf0:预测基频lf0和真实lf0的损失(可选是否启用)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号