

VITS
1.三种生成模型(GAN、VAE、FLOW)
生成模型:图像、文本、语音等数据,都可以看做是从一个复杂分布中采样得到的。从简单分布中随机采样一个z,经过生成器Generator后生成一个复杂样本X,这个过程就叫做生成。
Gan(生成竞争网络):从简单分布中经过生成器G生成一个假的样本,再通过鉴别器D检测生成样本和真实样本的区别,直到鉴别器D无法区分生成样本和真实样本。
VAE(变分自编码器):先从简单分布中采样z,再利用z生成x,人为设计一个从z到x的分布。用KL距离去拟合两个分布的相似度。
FLOW:直接构建两个分布之间直接的映射函数,从简单分布z到复杂分布x
2.模型整体架构:接近VAE模型
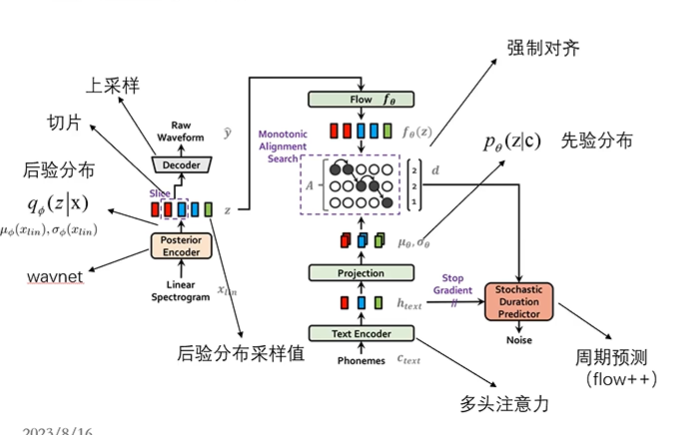
由语音得到的后验分布和由文字得到的先验分布的维度可能会不同,需要用Monotonic Alignment Search强制对齐,能够将文本序列的分布拓展到和语音序列分布的长度;
输入:短时傅里叶变换
损失:KL损失,输入和左侧输出的梅尔频谱损失(重构损失)
3.config文件解释
segment_size:对语音进行采样时的采样点数目
c_mel:重构损失权重
c_kl:KL损失权重
filter_length/hop_length/win_length:短时傅里叶变换数据
add_blank:加上停顿
model:包含Textencoder
4.文本编码器(TEXTEncoder):
对文本序列进行编码
text[B,T]->embedding{B,T,192]->transpose[B,192,T]->attention[B,192,T]->projection[B,192*2,T]->split[B,192.T]*2(一个均值一个方差的log)
Attention为多头注意力层,由六个多头注意力层组成,每层两个头,每层的输入输出都是[B,192,T]
5.相对位置编码:
早期的位置编码采用一个固定的公式计算(sin/cos)
只加入到K,V中,可选窗口,只关注周围的token
6.音频编码后验编码器
将输入音频转换成后验分布
输入:频谱特征;说话人id
对频谱特征做一维卷积,加入说话人特征进行waveNet,再进行一维卷积,split之后得到后验分布的均值和方差;
waveNet有多个空洞卷积组成:在卷积核中加上0(10101);kernel长度为kd-d+1;为了保证卷积前后长度不变,Padding=(kd-d)/2;增大感受野
7.flow部分的实现
从后验分布到先验分布的转换函数;四层ResidualCouplingLayer +Flip;每层都会加入说话人信息;
8.音频解码Decoder:
训练时对长度固定的切片进行解码;测试时对全部的采样值进行解码;relu+ConvTransposed1d+reblocks;
9.随机时长预测:
单独训练,输入文本每个符号持续的帧数d(强制对齐结果),设计一个去量化随机变量u,对连续变量d-u进行建模,u为(0,1)的随机分布;d-u的分布通过一个flow来进行映射(flow++):
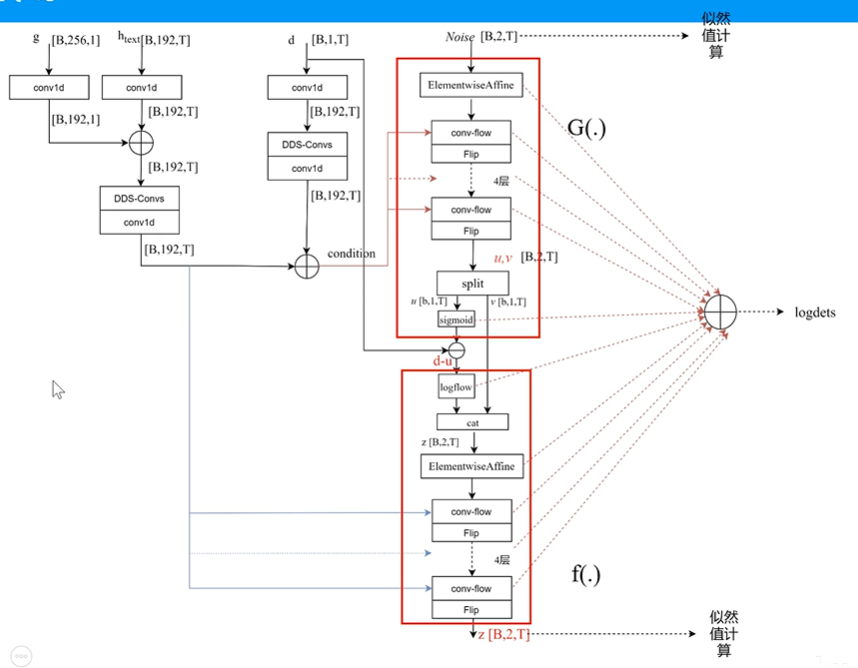
d为预测的周期(文本持续时间);
conv-flow:
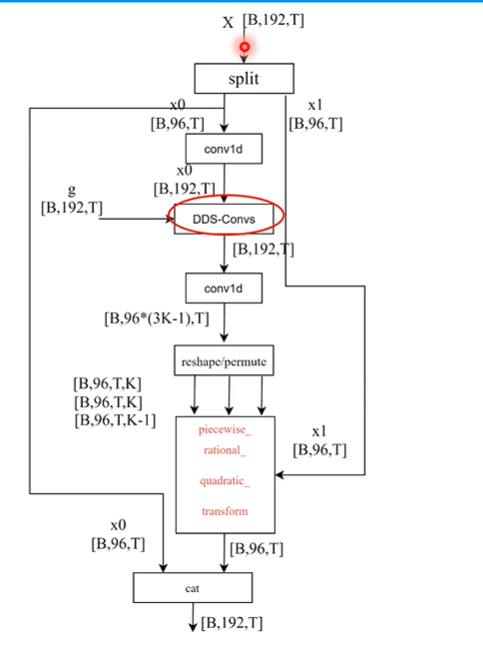
coupling transforms基本流程:
(1):将输入数据X分割成X0,X1两个部分
(2):利用神经网络从X0中学习一组参数theta=NN(X0)
(3):是用以theta参数的函数G对X1处理得到Y1
(4):Y0=X0,将Y0,Y1进行拼接得到Y
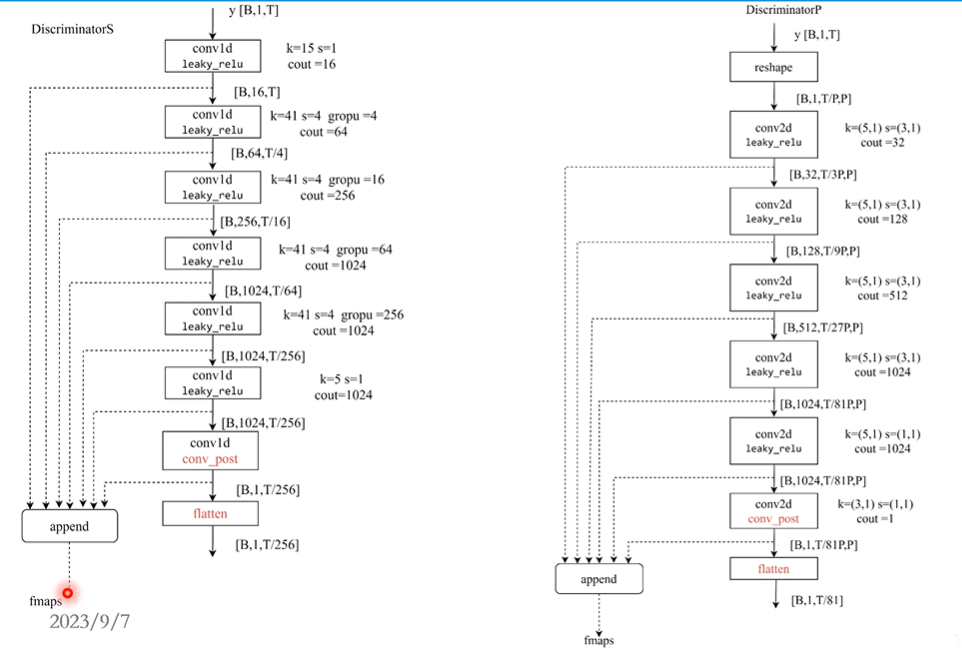
10.鉴别器:
在训练过程中是用多尺度鉴别器(类似GEN),由多组鉴别器拼接得到;
鉴别器内部为多个conv1d,或是reshape之后变成二维信号,使用多个Conv2d;
11.生成器工作流程:
SynthesizeTrn;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号