Tacotron2
1.数据下载与准备:
BZNSYP(包含10000条语音,有音素,采样频率48000Hz)
2.数据预处理:
提取音频特征(fbank特征);文本处理,归一化,将拼音分成分母韵母两部分,加上停顿、起始符、终止符;(参考了athena部分代码,里面有拼音的字典文件)
3.构建数据集:
文本特征:使用padding保持序列长度一致;把音素转换成数字编码;
音频特征:要对最大帧长进行拓展,使得能够被每一步处理的帧数整除;最后一帧往后的padding都是1;
4.模型部分:
LinearNorm:线性层,使用xavier_uniform_进行初始化
ConvNorm:卷积层,初始化同上
Encoder:3个卷积层(卷积+批归一化+RELU)+1个LSTM(双向LSTM),用rnn.pack_padded_sequence和rnn.pack_packed_sequence进行压缩和填充;
Prenet:两个线性层,维度变换
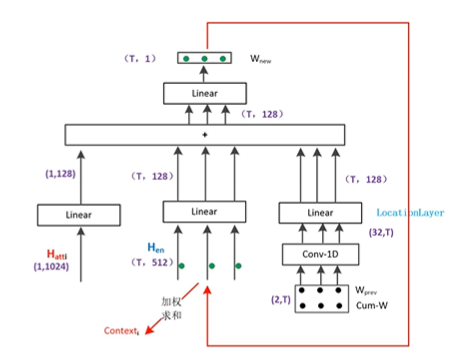
Decoder:两个RNN(attention rnn和decoder rnn),线性映射层;Attention部分:
Postnet:5层CNN,对解码器输出进行重构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号