Mysql-窗口函数
学习连接:https://blog.csdn.net/weixin_39010770/article/details/87862407
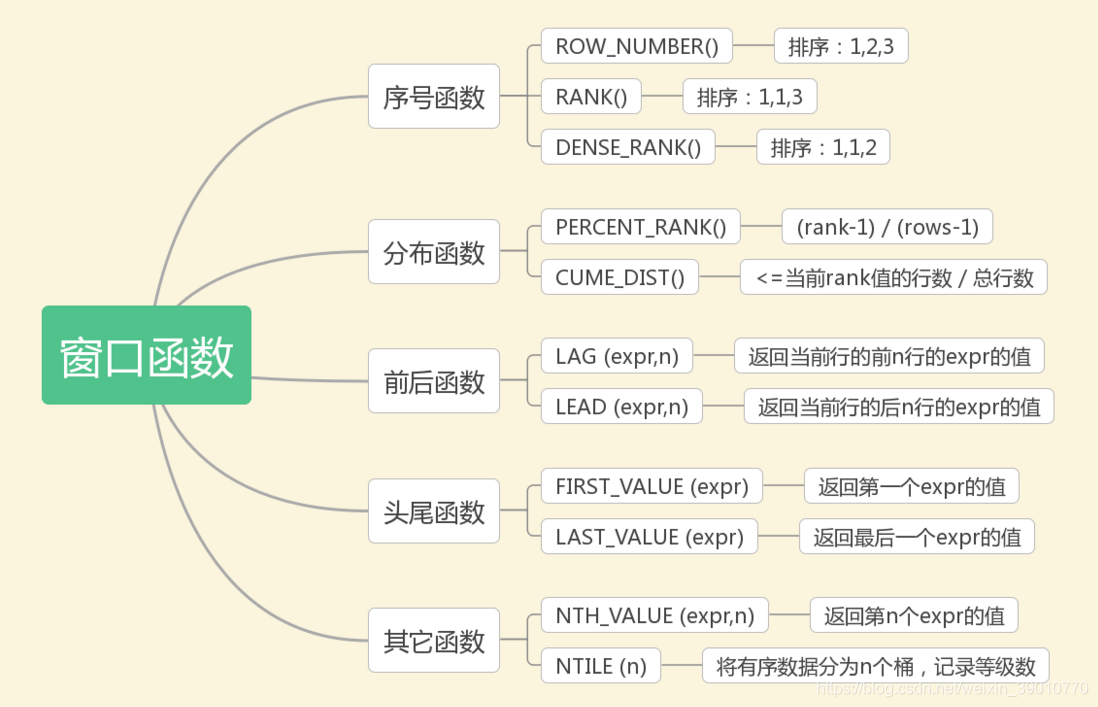
窗口:记录集合窗口函数:在满足某些条件的记录集合上执行的特殊函数,对于每条记录都要在此窗口内执行函数。有的函数随着记录的不同,窗口大小都是固定的,称为 静态窗口;有的函数则相反,不同的记录对应着不同的窗口,称为 滑动窗口。
1. 窗口函数和普通聚合函数的区别:
①聚合函数是将多条记录聚合为一条;窗口函数是每条记录都会执行,有几条记录执行完还是几条。
②聚合函数也可以用于窗口函数。
2. 窗口函数的基本用法:
函数名 OVER 子句
over关键字 用来指定函数执行的窗口范围,若后面括号中什么都不写,则意味着窗口包含满足WHERE条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下4中语法来设置窗口。
①window_name:给窗口指定一个别名。如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读;
②PARTITION BY 子句:窗口按照哪些字段进行分组,窗口函数在不同的分组上分别执行;
③ORDER BY子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号;
④FRAME子句:FRAME 是当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用。
# 先看一个例子 SELECT stu_id, score, sum(score) OVER (PARTITION BY stu_id) AS score_order FROM t_score; +--------+-------+-------------+ | stu_id | score | score_order | +--------+-------+-------------+ | 1 | 90 | 439 | | 1 | 95 | 439 | | 1 | 84 | 439 | | 1 | 75 | 439 | | 1 | 95 | 439 | | 2 | 88 | 420 | | 2 | 68 | 420 | | 2 | 98 | 420 | | 2 | 88 | 420 | | 2 | 78 | 420 | | 3 | 90 | 427 | | 3 | 68 | 427 | | 3 | 85 | 427 | | 3 | 89 | 427 | | 3 | 95 | 427 | | 4 | 68 | 420 | | 4 | 87 | 420 | | 4 | 93 | 420 | | 4 | 87 | 420 | | 4 | 85 | 420 | | 5 | 92 | 360 | | 5 | 92 | 360 | | 5 | 91 | 360 | | 5 | 85 | 360 | +--------+-------+-------------+
3. 按功能划分可将MySQL支持的窗口函数分为如下几类:
①序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
- 用途:显示分区中的当前行号
- 应用场景:查询每个学生的分数最高的前3门课程
ROW_NUMBER() OVER (PARTITION BY stu_id ORDER BY score)
SELECT * FROM ( SELECT stu_id, ROW_NUMBER() OVER (PARTITION BY stu_id ORDER BY score DESC) AS score_order, lesson_id, score FROM t_score ) t WHERE score_order <= 3; +--------+-------------+-----------+-------+ | stu_id | score_order | lesson_id | score | +--------+-------------+-----------+-------+ | 1 | 1 | L002 | 95 | | 1 | 2 | L005 | 95 | | 1 | 3 | L001 | 90 | | 2 | 1 | L003 | 98 | | 2 | 2 | L001 | 88 | | 2 | 3 | L004 | 88 | | 3 | 1 | L005 | 95 | | 3 | 2 | L001 | 90 | | 3 | 3 | L004 | 89 | | 4 | 1 | L003 | 93 | | 4 | 2 | L002 | 87 | | 4 | 3 | L004 | 87 | | 5 | 1 | L001 | 92 | | 5 | 2 | L002 | 92 | | 5 | 3 | L003 | 91 | +--------+-------------+-----------+-------+
对于 stu_id=1 的同学,有两门课程的成绩均为98,序号随机排了1和2。但很多情况下二者应该是并列第一,则他的成绩为88的这门课的序号可能是第2名,也可能为第3名。
这时候,ROW_NUMBER() 就不能满足需求,需要 RANK() 和 DENSE_RANK() 出场,它们和 ROW_NUMBER() 非常类似,只是在出现重复值时处理逻辑有所不同。
ROW_NUMBER():顺序排序——1、2、3 RANK():并列排序,跳过重复序号——1、1、3 DENSE_RANK():并列排序,不跳过重复序号——1、1、2
SELECT * FROM ( SELECT ROW_NUMBER() OVER (PARTITION BY stu_id ORDER BY score DESC) AS score_order1, RANK() OVER (PARTITION BY stu_id ORDER BY score DESC) AS score_order2, DENSE_RANK() OVER (PARTITION BY stu_id ORDER BY score DESC) AS score_order3, stu_id, lesson_id, score FROM t_score ) t WHERE stu_id = 1 AND score_order1 <= 3 AND score_order2 <= 3 AND score_order3 <= 3; +--------------+--------------+--------------+--------+-----------+-------+ | score_order1 | score_order2 | score_order3 | stu_id | lesson_id | score | +--------------+--------------+--------------+--------+-----------+-------+ | 1 | 1 | 1 | 1 | L002 | 95 | | 2 | 1 | 1 | 1 | L005 | 95 | | 3 | 3 | 2 | 1 | L001 | 90 | +--------------+--------------+--------------+--------+-----------+-------+
②分布函数:PERCENT_RANK()、CUME_DIST()
PERCENT_RANK()
- 用途:每行按照公式
(rank-1) / (rows-1)进行计算。其中,rank为RANK() 函数产生的序号,rows为当前窗口的记录总行数 - 应用场景:不常用
给窗口指定别名:WINDOW w AS (PARTITION BY stu_id ORDER BY score) rows = 5
SELECT RANK() OVER w AS rk, PERCENT_RANK() OVER w AS prk, stu_id, lesson_id, score FROM t_score WHERE stu_id = 1 WINDOW w AS (PARTITION BY stu_id ORDER BY score); +----+------+--------+-----------+-------+ | rk | prk | stu_id | lesson_id | score | +----+------+--------+-----------+-------+ | 1 | 0 | 1 | L004 | 75 | | 2 | 0.25 | 1 | L003 | 84 | | 3 | 0.5 | 1 | L001 | 90 | | 4 | 0.75 | 1 | L002 | 95 | | 4 | 0.75 | 1 | L005 | 95 | +----+------+--------+-----------+-------+
CUME_DIST()
- 用途:分组内小于、等于当前rank值的行数 / 分组内总行数
- 应用场景:查询小于等于当前成绩(score)的比例
cd1:没有分区,则所有数据均为一组,总行数为8
cd2:按照 lesson_id 分成了两组,行数各为4
SELECT stu_id, lesson_id, score, CUME_DIST() OVER (ORDER BY score) AS cd1 , CUME_DIST() OVER (PARTITION BY lesson_id ORDER BY score) AS cd2 FROM t_score WHERE lesson_id IN ('L001', 'L002'); +--------+-----------+-------+-----+-----+ | stu_id | lesson_id | score | cd1 | cd2 | +--------+-----------+-------+-----+-----+ | 4 | L001 | 68 | 0.3 | 0.2 | | 2 | L001 | 88 | 0.5 | 0.4 | | 1 | L001 | 90 | 0.7 | 0.8 | | 3 | L001 | 90 | 0.7 | 0.8 | | 5 | L001 | 92 | 0.9 | 1 | | 2 | L002 | 68 | 0.3 | 0.4 | | 3 | L002 | 68 | 0.3 | 0.4 | | 4 | L002 | 87 | 0.4 | 0.6 | | 5 | L002 | 92 | 0.9 | 0.8 | | 1 | L002 | 95 | 1 | 1 | +--------+-----------+-------+-----+-----+
③前后函数:LAG(expr,n)、LEAD(expr,n)
- 用途:返回位于当前行的前n行(
LAG(expr,n))或后n行(LEAD(expr,n))的expr的值 - 应用场景:查询前1名同学的成绩和当前同学成绩的差值
内层SQL先通过 LAG()函数 得到前1名同学的成绩,外层SQL再将当前同学和前1名同学的成绩做差得到成绩差值 diff。
SELECT stu_id, lesson_id, score, pre_score , score - pre_score AS diff FROM ( SELECT stu_id, lesson_id, score , LAG(score, 1) OVER w AS pre_score FROM t_score WHERE lesson_id IN ('L001', 'L002') WINDOW w AS (PARTITION BY lesson_id ORDER BY score) ) t; +--------+-----------+-------+-----------+------+ | stu_id | lesson_id | score | pre_score | diff | +--------+-----------+-------+-----------+------+ | 4 | L001 | 68 | NULL | NULL | | 2 | L001 | 88 | 68 | 20 | | 1 | L001 | 90 | 88 | 2 | | 3 | L001 | 90 | 90 | 0 | | 5 | L001 | 92 | 90 | 2 | | 2 | L002 | 68 | NULL | NULL | | 3 | L002 | 68 | 68 | 0 | | 4 | L002 | 87 | 68 | 19 | | 5 | L002 | 92 | 87 | 5 | | 1 | L002 | 95 | 92 | 3 | +--------+-----------+-------+-----------+------+
④头尾函数:FIRST_VALUE(expr)、LAST_VALUE(expr)
- 用途:返回第一个(
FIRST_VALUE(expr))或最后一个(LAST_VALUE(expr))expr的值 - 应用场景:截止到当前成绩,按照日期排序查询第1个和最后1个同学的分数
添加新列:
mysql> ALTER TABLE t_score ADD create_time DATE;
SELECT stu_id, lesson_id, score, create_time , FIRST_VALUE(score) OVER w AS first_score, LAST_VALUE(score) OVER w AS last_score FROM t_score WHERE lesson_id IN ('L001', 'L002') WINDOW w AS (PARTITION BY lesson_id ORDER BY create_time); +--------+-----------+-------+-------------+-------------+------------+ | stu_id | lesson_id | score | create_time | first_score | last_score | +--------+-----------+-------+-------------+-------------+------------+ | 3 | L001 | 100 | 2018-08-07 | 100 | 100 | | 1 | L001 | 98 | 2018-08-08 | 100 | 98 | | 2 | L001 | 84 | 2018-08-09 | 100 | 99 | | 4 | L001 | 99 | 2018-08-09 | 100 | 99 | | 3 | L002 | 91 | 2018-08-07 | 91 | 91 | | 1 | L002 | 86 | 2018-08-08 | 91 | 86 | | 2 | L002 | 90 | 2018-08-09 | 91 | 90 | | 4 | L002 | 88 | 2018-08-10 | 91 | 88 | +--------+-----------+-------+-------------+-------------+------------+
⑤其它函数:NTH_VALUE(expr, n)、NTILE(n)
NTH_VALUE(expr,n)
- 用途:返回窗口中第n个
expr的值。expr可以是表达式,也可以是列名 - 应用场景:截止到当前成绩,显示每个同学的成绩中排名第2和第3的成绩的分数
SELECT stu_id, lesson_id, score , NTH_VALUE(score, 2) OVER w AS second_score , NTH_VALUE(score, 3) OVER w AS third_score FROM t_score WHERE stu_id IN (1, 2) WINDOW w AS (PARTITION BY stu_id ORDER BY score); +--------+-----------+-------+--------------+-------------+ | stu_id | lesson_id | score | second_score | third_score | +--------+-----------+-------+--------------+-------------+ | 1 | L004 | 75 | NULL | NULL | | 1 | L003 | 84 | 84 | NULL | | 1 | L001 | 90 | 84 | 90 | | 1 | L002 | 95 | 84 | 90 | | 1 | L005 | 95 | 84 | 90 | | 2 | L002 | 68 | NULL | NULL | | 2 | L005 | 78 | 78 | NULL | | 2 | L001 | 88 | 78 | 88 | | 2 | L004 | 88 | 78 | 88 | | 2 | L003 | 98 | 78 | 88 | +--------+-----------+-------+--------------+-------------+
NTILE(n)
- 用途:将分区中的有序数据分为n个等级,记录等级数
- 应用场景:将每门课程按照成绩分成3组
SELECT NTILE(3) OVER w AS nf, stu_id, lesson_id, score FROM t_score WHERE lesson_id IN ('L001', 'L002') WINDOW w AS (PARTITION BY lesson_id ORDER BY score); +------+--------+-----------+-------+ | nf | stu_id | lesson_id | score | +------+--------+-----------+-------+ | 1 | 4 | L001 | 68 | | 1 | 2 | L001 | 88 | | 2 | 1 | L001 | 90 | | 2 | 3 | L001 | 90 | | 3 | 5 | L001 | 92 | | 1 | 2 | L002 | 68 | | 1 | 3 | L002 | 68 | | 2 | 4 | L002 | 87 | | 2 | 5 | L002 | 92 | | 3 | 1 | L002 | 95 | +------+--------+-----------+-------+
NTILE(n) 函数在数据分析中应用较多,比如由于数据量大,需要将数据平均分配到n个并行的进程分别计算,此时就可以用NTILE(n)对数据进行分组(由于记录数不一定被n整除,所以数据不一定完全平均),然后将不同桶号的数据再分配。
4. 聚合函数作为窗口函数:
- 用途:在窗口中每条记录动态地应用聚合函数(
SUM()、AVG()、MAX()、MIN()、COUNT()),可以动态计算在指定的窗口内的各种聚合函数值 - 应用场景:截止到当前时间,查询
stu_id=1的学生的累计分数、分数最高的科目、分数最低的科目
SELECT stu_id, lesson_id, score, create_time , FIRST_VALUE(score) OVER w AS first_score
, LAST_VALUE(score) OVER w AS last_score FROM t_score WHERE lesson_id IN ('L001', 'L002') WINDOW w AS (PARTITION BY lesson_id ORDER BY create_time); +--------+-----------+-------+-------------+-----------+-----------+-----------+ | stu_id | lesson_id | score | create_time | score_sum | score_max | score_min | +--------+-----------+-------+-------------+-----------+-----------+-----------+ | 1 | L001 | 98 | 2018-08-08 | 184 | 98 | 86 | | 1 | L002 | 86 | 2018-08-08 | 184 | 98 | 86 | | 1 | L003 | 79 | 2018-08-09 | 263 | 98 | 79 | | 1 | L004 | 88 | 2018-08-10 | 449 | 98 | 79 | | 1 | L005 | 98 | 2018-08-10 | 449 | 98 | 79 | +--------+-----------+-------+-------------+-----------+-----------+-----------+
请你一定不要停下来 成为你想成为的人
感谢您的阅读,我是LXL

 浙公网安备 33010602011771号
浙公网安备 33010602011771号