

redis
1.redis基础
数据结构 操作 持久化
1.1 数据结构:
**string
字符串可以保存三种数据类型:字符串,整数,浮点数
自增自减命令:
incr key 自增1
decr key 自减1
incrby key 要增加的数字 增加指定的数字
decrby key 要减去的数字 减去指定的数字
append key-name value 追加value
getrange key-name start end 相当于对原值没有影响
**list
一个列表可以存储有序的多个字符串
指令:
LPUSH/RPUSH 将给定的值推入列表的左右端
LRANGE 获取列表给定范围的所有值,0-1可以查看所有
LINDEX 获取给定位置的单个元素
**set
和java的set相同,唯一无序
一些简单命令
【SADD 集合名 添加的元素】添加元素
【SREM 集合名 移除的元素】 移除元素
【SISMEMBER 集合名 查找元素】 查找元素
【SMEMBERS 集合名】 查找所有元素,数据量多可能会慢
**hashmap
可以存储多个键值对之间的映射
散列存储的值既可以是字符串也可以是数字
用户同样可以对散装存储的数字执行自增或者自减
指令:
hset 集合名 键 值
hget 集合名 键
hdel 集合名 键
hgetall 集合名
**Zset
特点:
散列一样,存储键值对
键称为成员
值称为 分值,必须为浮点数
唯一一个既可以根据成员访问元素没有可以根据分值以及分值的排序顺序
命令:
ZADD
ZRANGE
ZRANGEBYSCORE
XREM
WITHSCORES 末尾追击这个命令,按照分值进行排序
##1.2 操作
*事务
通过watch,multi和exec可以制作一个事务流水线,减少应用和redis的交互,提高性能。watch会监控键,在执行exec之前表新增修改删除的话,那么exec的事后后悔返回错误

exec原子事务的结束点
不支持回滚
*流水线
使用conn.pipelined()
如果有true这个参数就是使用事务,不写或者false参数就是单纯的流水线,性能会提升
1.3 ## 发布订阅
* 数据会丢失
数据传输的可靠性,如果客户端在执行订阅操作的过程中短线,短线期间发送的消息会丢失
如果能承担一部分数据的丢失可以使用
1.4 ## 持久化方式
*快照 rdb
保存某一时间点的所有信息
适用场景:快照没照完,系统就崩溃了,丢失最后一次成功快照后的信息
不适用场景:很大的数据占用很大的内存,创建子进程会造成很长时间的停顿,有些应用语法接受
灵活:可在dbfilename文件配置输出文件名,还可以匹配输出目录
相关指令;
bgsave redis 创建一个子进程后台保存快照
save 拒绝接受请求,专一的执行快照,所以这个不常用
配置文件设置 save 60 10000 表示60秒内有10000个写操作,保存数据
** 只追加文件
将修改数据库的命令写入 只追加(appead-only)文件里面,追加写入设置可以设置为 从不同步, 每秒同步,没写入一次就同步一次
Redis提供主从复制功能
append only file 持久化的数据追加到文件的末尾
三个同步指令:
appendfsync always 同步每一个,频繁写指令系统会崩溃
appendfsync everysec 最大丢一秒
appendfsync no 丢失不可控数据 过多的存储降低储存数据
缺点: 持久化文件太大了
可对文件进行压缩:
需要使用子进程,redis过大创建子进程的时间会更多,问题和之前相同。可以灵活设置压缩文件的大小,超过某大小或超过上一次压缩的大小的几倍
1.5 ### 性能测试 redis-benchmark -c -l -q
-c -l 使用单机测试 -q 简化测试
实际生产环境只有测试效果的50-60,因为测试不会处理返回结果
#2.高级
##2.1
*主从复制
从服务器帮助分担写的压力
对传输文件进行压缩,减少传输量
*挑选正确的数据结构
*存入前压缩
*存入后压缩
*使用流
## 2.2扩展写性能和内存容量
使用redis集群扩展写性能和内存容量 下面是具体集群介绍
#3. redis--cluster
redis集群的特点,配置和实战
##3.1特点
**分片
redis集群中有16384个散列槽
集群至少拥有三个节点:
A节点包含从0到5500的散列槽
B节点包含从5501到11000的散列槽
C节点包含从11001到16383的散列槽
新增节点,从三个节点分出一部分数据给D
删除节点把节点数据平均移动给其他节点
** 主从复制
每一个主节点,必须要有一个从节点,保证数据高可用,主节点崩溃,从节点替换,从节点上升为主节点,主节点恢复后变为从节点
**弱一致性
需要在性能和一致性之间进行权衡 为性能牺牲一致性
## 3.2 配置端口
**服务端口
**集群总线端口
故障检测
配置更新
故障转移授权
## 3.3 实战
** 同一个客户端,不同的配置文件
使用相同的内存
** 手动故障转移
Redis Cluster使用 CLUSTER FAILOVER 命令支持手动故障转移,该命令必须要在故障转移的 主站的一个从站执行
** 副本迁移
在redis集群中,需要使用以下命令,就可以随时使用不同的主服务器重新配置从属服务器进行复制: CLUSTER REPLICATE
* 增加/删除节点
新增节点:
redis-cli--cluster add-node 127.0.0.1:7006 127.0.0.1:7000
准确指定要使用新副本定位的主控制器:
redis-cli--cluster add-node 127.0.0.1:7006 127.0.0.1:7000 --cluster -slava --cluster-master-id xxxxx
删除从节点,只需要使用del-noderedis-cli 命令:
redis-cli--cluster reshard 127.0.0.1:7000
写上所有插槽的数量
写上自己的id
done
redis-cli--cluster del-node 127.0.0.1:7000
* 无法使用multi

#4.redis-sentlnel
redis sentinel是redis官方的高可用解决方案。总结了sentinel的一些功能和使用方式
##4.1 功能
*监控
Sentinel会不断检查主实例和从属实例是否按预期工作
*通知
Sentinel可以通过API通知系统管理员,另一台计算机程序,其中一个受监控的reids实例出现问题
*自动故障转移
如果主服务器未按照预期工作,sentinel可以故障转移,其中从服务器升级为主服务器,其他redis服务器应用程序通知有关新服务器的地址连接
*配置提供
sentinel 充当客户端服务发现的权限来源:客户端连接到sentinels,以便于负责给定服务的当前redis主服务器的地址,如果发生故障转移,sentinels将报告新地址
## 4.2 实战使用多个 sentinels优势
减少误报 高可用
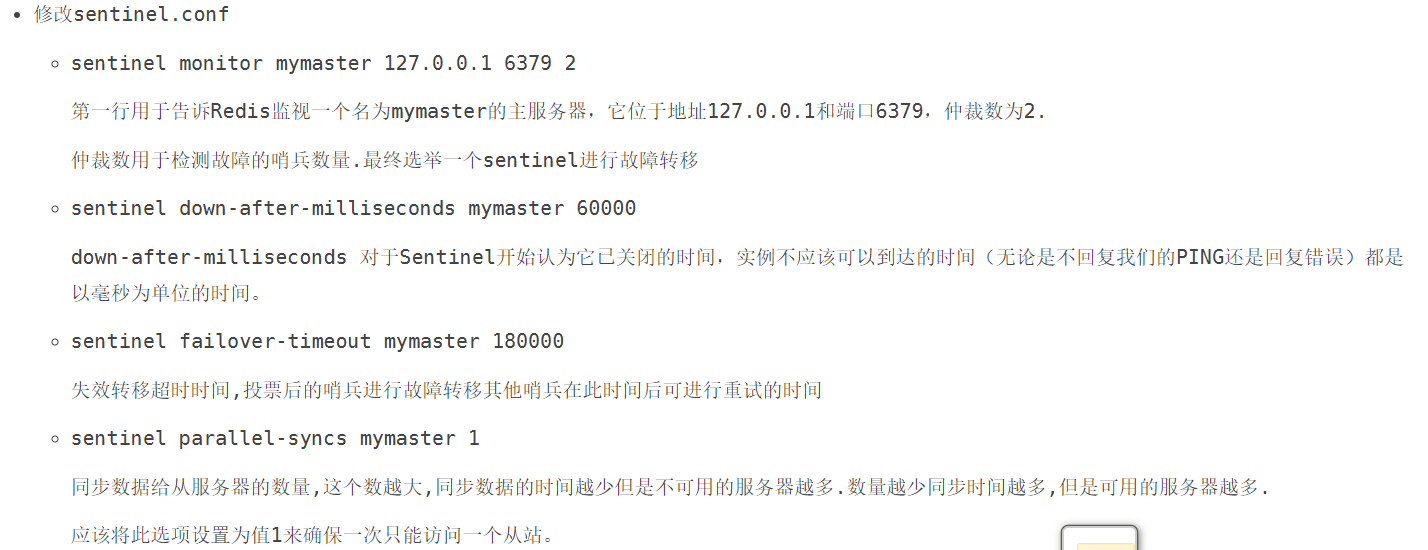
## 4.3 使用
*

#5. Redisson
Redisson是一个Redis的java客户端,Redisson提供了使用Redis的最简单和最便捷的方法。redission是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中的放在处理业务逻辑上。
##5.1 分布式锁
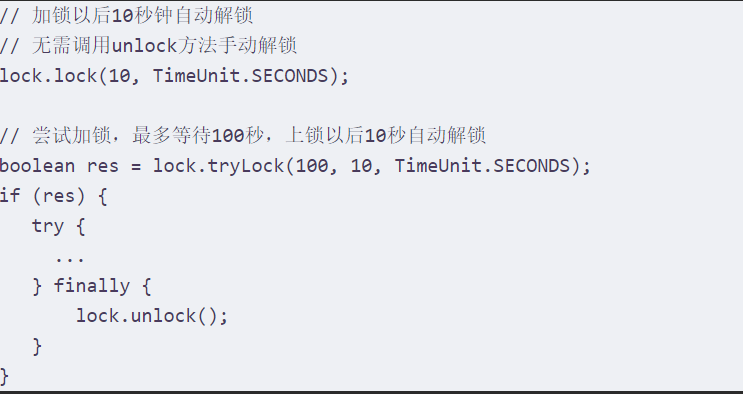
*可重入锁
基于redis的reission分布式可重入锁 RLock JAVA 对象实现了Java.util.concurrent.locks.LOCK接口。同时提供异步,反射式和RxJava2便准的接口

自动解锁的方式:
**公平锁
基于Redis的Redisson分布式可重入公平锁也是实现了java.util.concurrent.locks.lock
的一种现象,它保证了多个redisson客户端线程同时请求加锁时,优先分配给先发出请求的线程。所有请求会在一个队列中排队,当某个线程出现宕机时,redisson会等待5秒继续下一个线程,也就是说前面5个都等待,那么后面进程最少等待25秒。

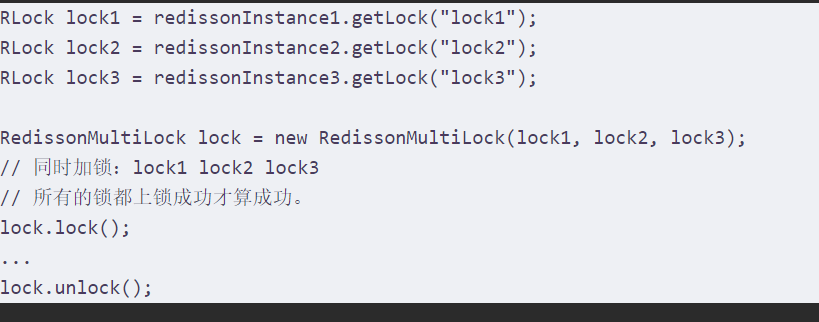
**联锁(MultiLOCK)
基于redis的redisson分布式联锁redissonMultiLock对象可以将多个对象关联为一个联锁,每一个Rlock对象实例可以来自不同的redisson实例

* 独享
相互互斥。任意时刻,只有一个客户端持有锁
*无死锁
即便持有锁的客户端崩溃或者网络被分裂 锁仍然可以被获取
*容错
只要大部分redis节点都活着,客户端就可以获取和释放锁
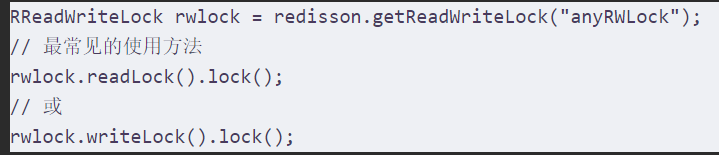
***读写锁
分布式可重入读写锁允许 同时有多个读锁和一个写锁处于加锁状态
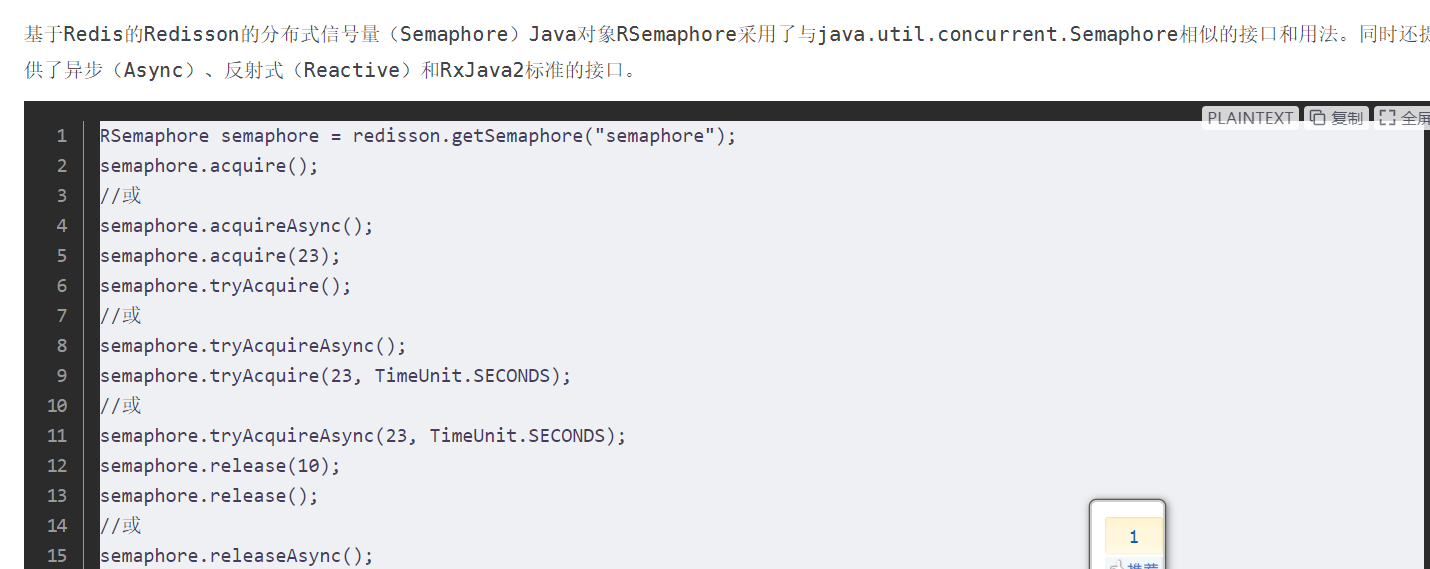
信号量(Semaphore)
可过期信号量(PermitEXpirableSemaphore)
基于redis的redisson可过期信号量是在RSemaphore对象的基础,为每一个信号增加了过期时间,可以通过独立的ID来辨识,通过提交这个ID才能释放

**闭锁
基于Redisson的redisson分布式闭锁java对象RcountDownLATch采用了与java.util.concurrent.CountDownLatch相似的接口和用法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号