Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
爬取华图教育官网2020年国家公务员招聘信息
2.主题式网络爬虫爬取的内容与数据特征分析爬取国家公务员的招聘具体信息的文档
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)实现思路:
(1)利用requests请求网页并爬取目标页面
(2)利用BeautifulSoup解析网页同时获取文件名及目标url链接
(3)将爬取到的信息(招聘信息的具体文档)下载下来
(4)利用pandas分析数据
技术难点:
(1)网页源代码内容太过单一简洁,分析过程较难进行
(2)注意BeautifulSoup库中findAll的语法的书写格式
(3)要注意在遍历过程中代码的对齐
(4)数据分析时,注意将表格列表的第二行设置为标题(因为第一行是内容说明)
1.主题页面的结构特征
打开华图官网,点击右键打开检查,查看网页结构,找到对应要爬取的链接。打开该链接,爬取职位表信息。
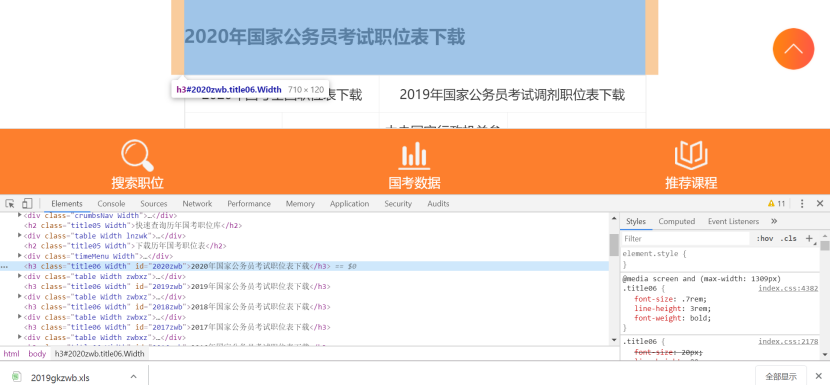
2.Htmls页面解析
使用BeautifulSoup进行网页页面解析,通过观察发现我想要获取的内容是在“div”标签下的“a”标签中。
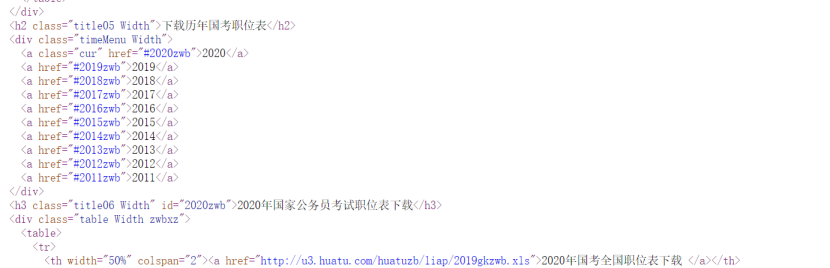
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
查找方法:findAll
遍历方法:for循环
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
import requests from bs4 import BeautifulSoup import os #爬取华图目标的HTML页面 def getHTMLText(url): try: #获取目标页面 r = requests.get(url) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败" #获取文件名 def getName(html,namelist): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为class="table Width zwbxz"的div标签 for div in soup.findAll("div",{"class":"table Width zwbxz"}): #遍历div标签中的a标签 for a in div.findAll("a"): #将a标签中的内容存储在namelist列表中 namelist.append(a.get_text()) return namelist #获取目标url链接 def getURL(html,urllist): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为class="table Width zwbxz"的div标签 for div in soup.findAll("div",{"class":"table Width zwbxz"}): #遍历div标签中的a标签 for a in div.findAll("a"): #判断a标签中是否含有href属性 if 'href' in a.attrs: #如果有则将a中的链接存储在urllist列表中 urllist.append(a.attrs['href']) return urllist #数据存储 def dataSave(file,name): try: #创建文件夹 os.mkdir("C:\华图") except: #如果文件夹存在则什么也不做 "" try: #创建文件用于存储爬取到的数据 with open("C:\\华图\\{}.xls".format(name),"wb") as f: f.write(file.content) print("下载成功") except: "存储失败" #用于存储目标url链接 urllist = [] #用于存储文件名 namelist = [] #华图教育网url链接 url = "http://zw.huatu.com/zwbxz/" #获取页面html代码 html = getHTMLText(url) #获取目标的url链接 getURL(html,urllist) #获取文件名 getName(html,namelist) #将目标的信息存储在本地 for i in range(0,len(urllist)): #获取链接下的文件信息 file=requests.get(urllist[i]) #将文件信息存储在本地 dataSave(file,namelist[i])
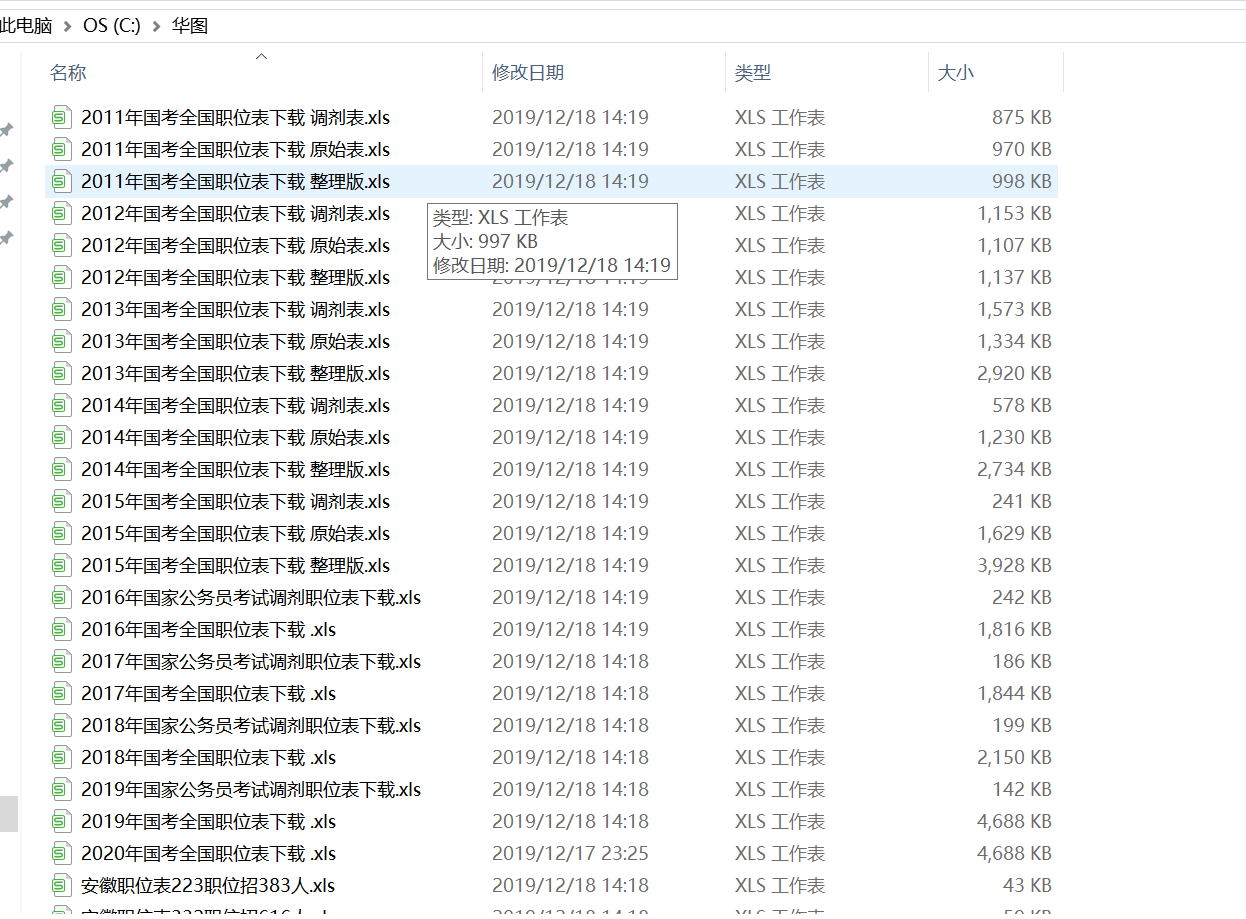
2.对数据进行清洗和处理
import pandas as pd gongwuyuan=pd.DataFrame(pd.read_excel('C:\华图/2020年国考全国职位表下载 .xls')) gongwuyuan.head()

(2)因为第一行为说明行,第二行才是标题行,所以设置第二行为标题行
import pandas as pd gongwuyuan=pd.DataFrame(pd.read_excel('C:\华图/2020年国考全国职位表下载 .xls', header = 1)) gongwuyuan.head()

(3)重复值处理
gongwuyuan.duplicated()
(4)空值和缺失值处理
gongwuyuan['备注'].isnull().value_counts()

(5)空值和缺失值用null代替
gongwuyuan['备注']=gongwuyuan['备注'].fillna('null') gongwuyuan.head()

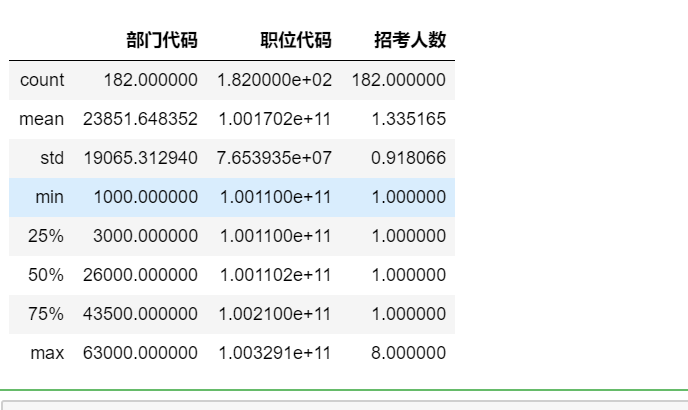
(6)观察是否产生异常值
gongwuyuan.describe()
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
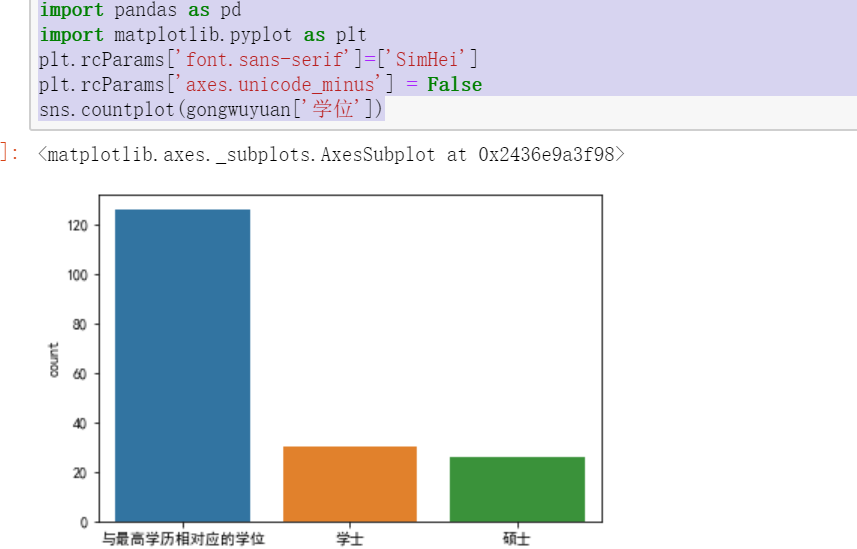
import seaborn as sns import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False sns.countplot(gongwuyuan['学位'])
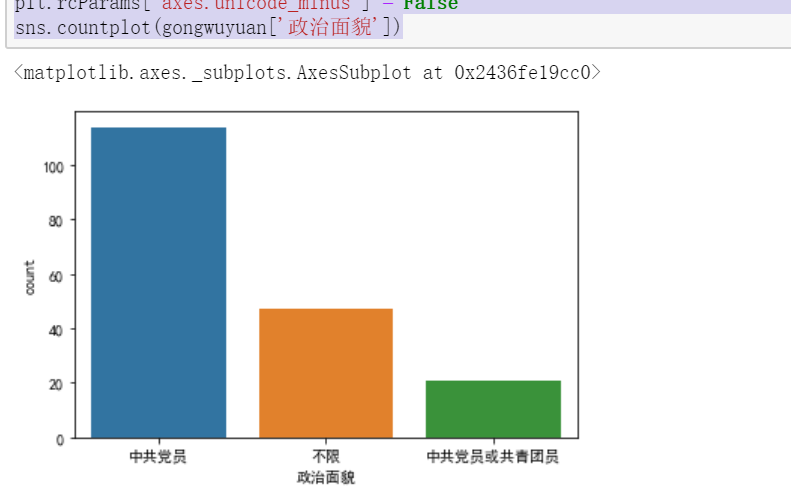
(2)利用柱形图描述岗位需求的政治面貌
import seaborn as sns import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False sns.countplot(gongwuyuan['政治面貌'])
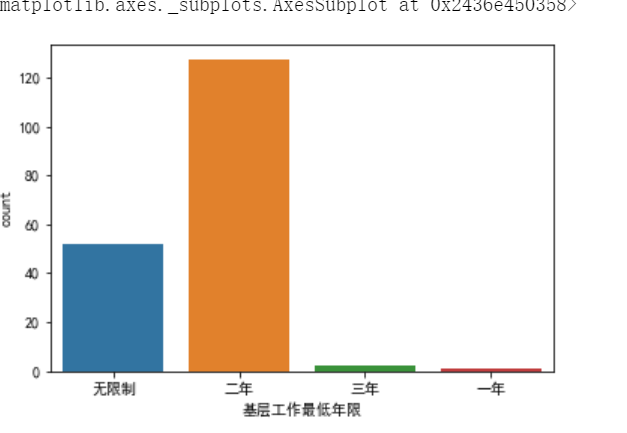
(3)利用柱形图描述岗位需求的基层工作最低年限
import seaborn as sns import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False sns.countplot(gongwuyuan['基层工作最低年限'])
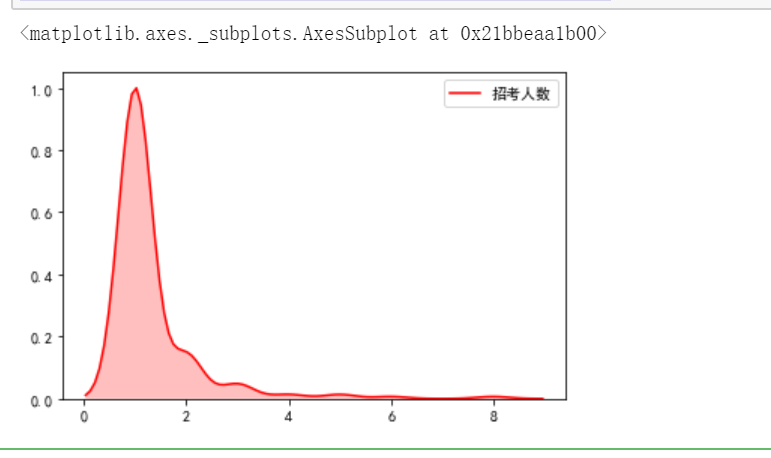
(4)利用单变量核密度图,可以看出招考人数的分布情况
sns.kdeplot(gongwuyuan['招考人数'],shade=True,color='r')
5.数据持久
import requests from bs4 import BeautifulSoup import os #爬取华图目标的HTML页面 def getHTMLText(url): try: #获取目标页面 r = requests.get(url) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败" #获取文件名 def getName(html,namelist): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为class="table Width zwbxz"的div标签 for div in soup.findAll("div",{"class":"table Width zwbxz"}): #遍历div标签中的a标签 for a in div.findAll("a"): #将a标签中的内容存储在namelist列表中 namelist.append(a.get_text()) return namelist #获取目标url链接 def getURL(html,urllist): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为class="table Width zwbxz"的div标签 for div in soup.findAll("div",{"class":"table Width zwbxz"}): #遍历div标签中的a标签 for a in div.findAll("a"): #判断a标签中是否含有href属性 if 'href' in a.attrs: #如果有则将a中的链接存储在urllist列表中 urllist.append(a.attrs['href']) return urllist #数据存储 def dataSave(file,name): try: #创建文件夹 os.mkdir("C:\华图") except: #如果文件夹存在则什么也不做 "" try: #创建文件用于存储爬取到的数据 with open("C:\\华图\\{}.xls".format(name),"wb") as f: f.write(file.content) print("下载成功") except: "存储失败" #用于存储目标url链接 urllist = [] #用于存储文件名 namelist = [] #华图教育网url链接 url = "http://zw.huatu.com/zwbxz/" #获取页面html代码 html = getHTMLText(url) #获取目标的url链接 getURL(html,urllist) #获取文件名 getName(html,namelist) #将目标的信息存储在本地 for i in range(0,len(urllist)): #获取链接下的文件信息 file=requests.get(urllist[i]) #将文件信息存储在本地 dataSave(file,namelist[i])
1.经过对主题数据的分析与可视化,可以得到哪些结论?
(1)学位为学士的可报考的岗位比硕士的多
(2)政治面貌中要求中共党员的较多
(3)基层工作年限要求两年的较多
(4)职位招考一人的岗位比较多
2.对本次程序设计任务完成的情况做一个简单的小结。本次课程设计由于自己选择方向没有选好的缘故,所以一开始总是麻烦不断,原先打算爬取中公教育的2019年国家公务员招聘信息,因为该网站属于连接嵌套,由官网跳转至公务员招聘的网页再跳转至2019年公务员招聘界面最后再次跳转至下载界面,爬取难度太大且只能单一的爬取,无法批量下载。后来分析了华图教育官网的网页发现华图教育官网的爬取可以批量下载爬取,所以改为爬取华图教育的官网。数据分析的过程中发现该招聘内容基本上都是文字内容,画图的时候,很多图由于“str”与“int”导致无法识别,所以画图只能画出单一的柱形图。总而言之,遇到了很多难题,也学习到了很多的方法,通过本次课程设计,我受益匪浅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号