提前发现问题
1、每周检查服务指标,接口请求、耗时(网关统计prometheus、nginx日志采集)
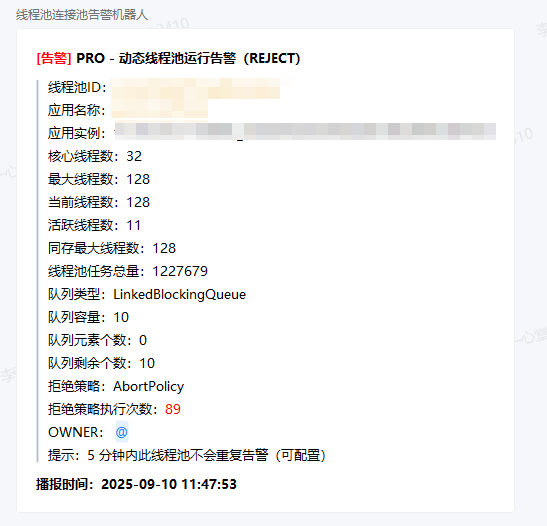
2、每周检查中间件指标(CPU、内存、QPS、磁盘使用率等) 比如CPU 内存 同比大幅增长
3、每周慢sql检查,治理(云厂商 dashboar获取)
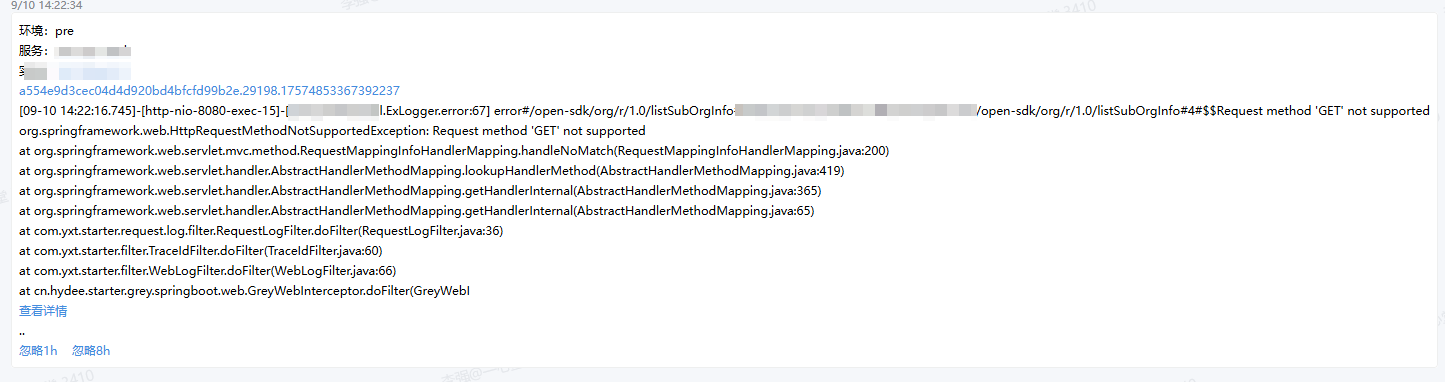
4、错误日志治理,error日志都需要告警到研发,如果不需要告警符合预期的 不打印error
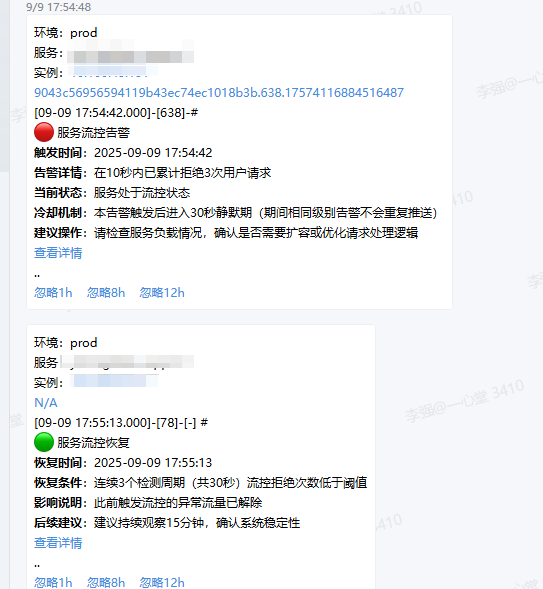
5、每周慢接口检查治理、针对高QPS的进行优化,或者熔断降级线路,避免超过接口处理阈值的流量,压垮服务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号