Python百度文库爬虫之txt文件
Python百度文库爬虫之txt文件
说明:
对于文件的所有类型,我都会用一篇文章进行说明,链接:
- Python百度文库爬虫之txt文件
- Python百度文库爬虫之doc文件
- Python百度文库爬虫之pdf文件
- Python百度文库爬虫之ppt文件
- [Python百度文库爬虫之xls文件
- Python百度文件爬虫终极版
一.网页分析
txt文件最容易爬取的文件,此文件类型不需要进行文件排版,直接爬取并保存
from IPython.display import Image
Image("./Images/txt_0.png",width="600px",height="400px")
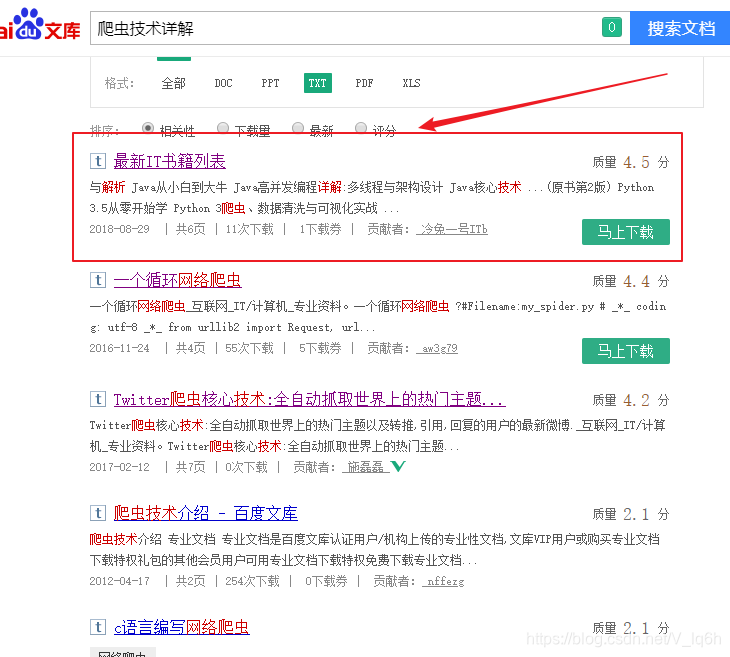
此文件的链接(URL):https://wenku.baidu.com/view/147d495158eef8c75fbfc77da26925c52cc5913d.html?fr=search
二.URL分析
我们查看网页源代码发现没有我们需要的文件数据,我们只能查看其它相关的URL。发现有个链接存在我们需要的文件数据:
https://wkretype.bdimg.com/retype/text/147d495158eef8c75fbfc77da26925c52cc5913d?md5sum=aa717cd0960c7940d5f404b32b10d5e5&sign=72df814876&callback=cb&pn=1&rn=6&type=txt&rsign=p_6-r_0-s_f3056&_=1587947981910
Image("./Images/txt_1.png",width="600px",height="400px")
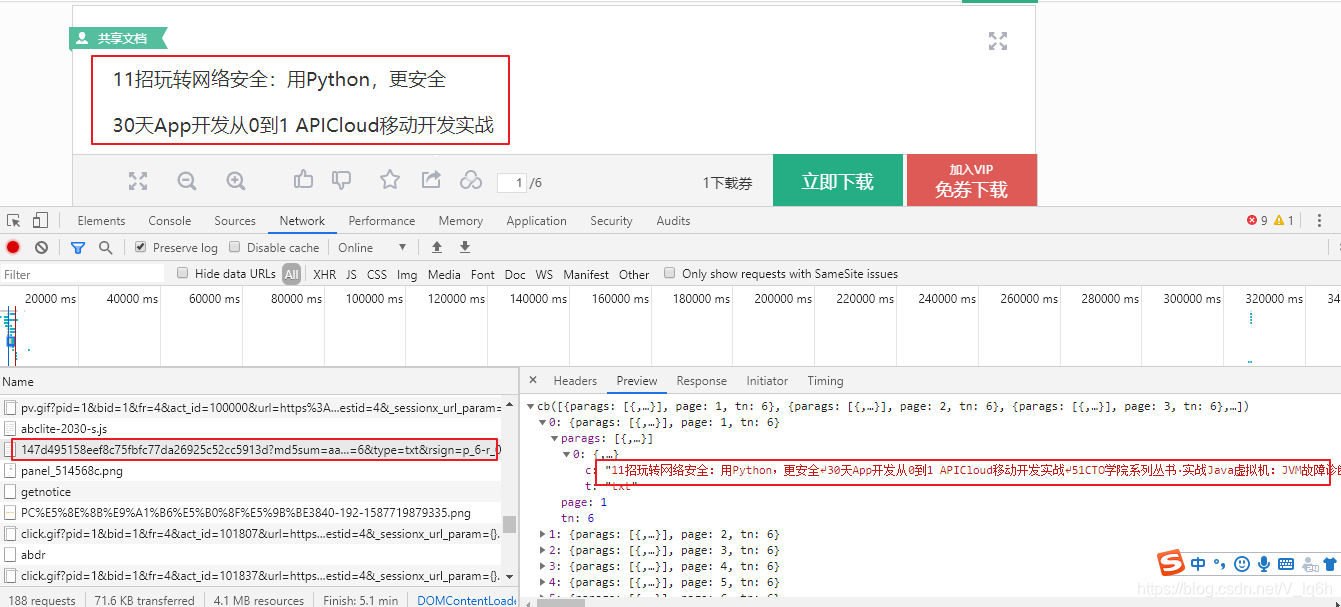
此链接所需的参数为:
- md5sum: aa717cd0960c7940d5f404b32b10d5e5
- sign: 72df814876
- callback: cb
- pn: 1
- rn: 6
- type: txt
- rsign: p_6-r_0-s_f3056
- _: 1587947981910
Image("./Images/txt_2.png",width="600px",height="400px")
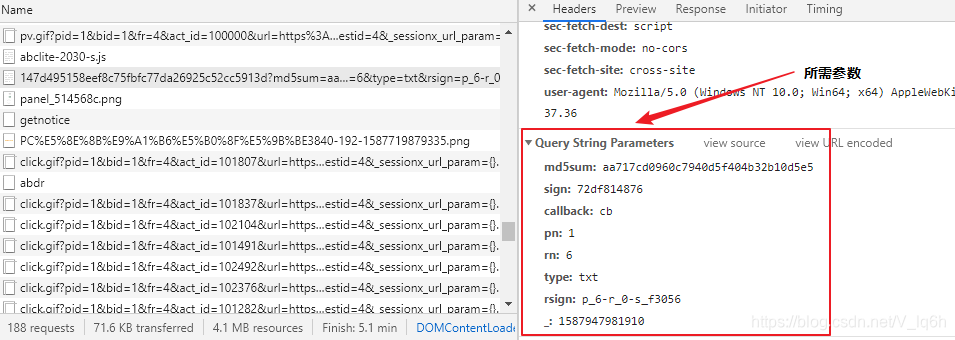
说明一下:此链接还有一个doc_id的文件id的参数,只是我们输入下载文件链接时可以获取:
doc_id=re.findall(‘view/(.*?).html’,url)[0]
此url是下载文件的链接
对于上面所需的参数,我们需要按照时间线查找上面的链接,查看是否有数据传输接口包含我们需要的数据,通过查看我们找到了一个数据接口:
https://wenku.baidu.com/api/doc/getdocinfo?callback=cb&doc_id=147d495158eef8c75fbfc77da26925c52cc5913d&t=1587947982553&_=1587947981909
Image("./Images/txt_3.png",width="600px",height="400px")
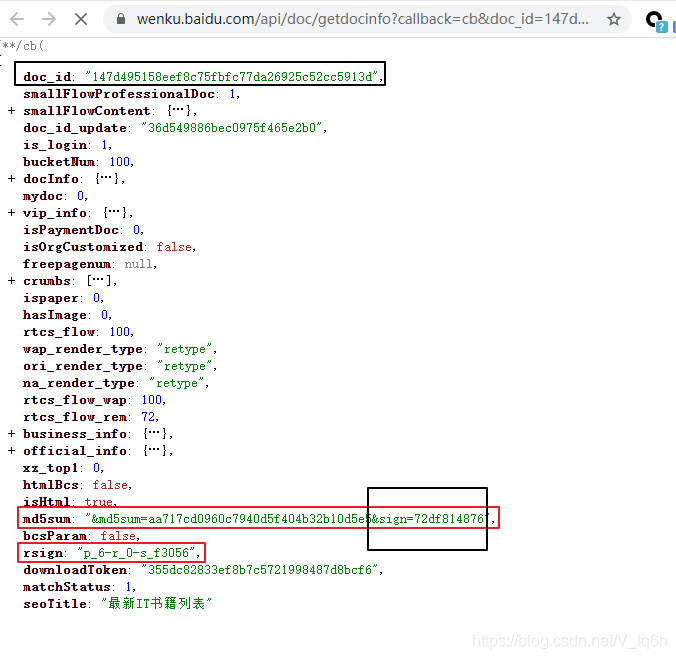
上面链接包含我们部分我们需要的链接参数:
- md5sum: aa717cd0960c7940d5f404b32b10d5e5
- sign: 72df814876
- type: txt
- rsign: p_6-r_0-s_f3056
没有获取的链接参数有:
- callback: cb
- pn: 1
- rn: 6
- _: 1587947981910
参数callback为常数参数,pn与文件的页数(pageNum)相关,主要是_参数,我们猜到这个是类似时间戳的参数,对于这种前后关联的请求,处理时一般采用Requests的session
import requests
url='https://www.baidu.com'
session=requests.session()
content=session.get(url).content.decode('utf-8')
添加说明一下,我们需要解析我们文件链接(URL)的网页源代码,由于我们需要的数据非格式数据,不能使用lxml,bs4等数据解析器,只能使用Re正则表达式,关于正则表达式的学习:链接
Image("./Images/txt_4.png",width="600px",height="400px")

三.程序调试
1.文件信息获取
import requests
import json
import re
import os
session=requests.session()
url=input("请输入下载的文库URL地址:")
content=session.get(url).content.decode('utf-8')
doc_id=re.findall('view/(.*?).html',url)[0]
types=re.findall(r"docType.*?:.*?'(.*?)'",content)[0]
title=re.findall(r"title.*?:.*?'(.*?)'",content)[0]
请输入下载的文库URL地址: https://wenku.baidu.com/view/8edb30e82dc58bd63186bceb19e8b8f67c1cef8e.html?fr=search
content_url='https://wenku.baidu.com/api/doc/getdocinfo?callback=cb&doc_id='+doc_id
content=session.get(content_url).content.decode('gbk')
md5sum=re.findall('"md5sum":"(.*?)",',content)[0]
md5sum
'&md5sum=aa717cd0960c7940d5f404b32b10d5e5&sign=72df814876'
rsign=re.findall('"rsign":"(.*?)"',content)[0]
rsign
'p_6-r_0-s_f3056'
pn=re.findall('"totalPageNum":"(.*?)"',content)[0]
pn
'6'
content_url='https://wkretype.bdimg.com/retype/text/'+doc_id+'?rn='+pn+'&type='+types+md5sum+'&rsign='+rsign
content=json.loads(session.get(content_url).content.decode('gbk'))
result=''
for item in content:
for i in item['parags']:
result+=i['c']
filename=title+'.txt'
with open(filename,'w',encoding='utf-8') as f:
f.write(result)
f.close()
Image("./Images/txt_5.png",width="600px",height="400px")

四.函数编程
1.程序改进
当我请求这个文件内容时:https://wenku.baidu.com/view/8edb30e82dc58bd63186bceb19e8b8f67c1cef8e.html?fr=search。这个txt文件的加载过程与其他txt文件不同,它所需的参数都在这个网页中,不需要数据传输接口
Image("./Images/txt_6.png",width="600px",height="400px")
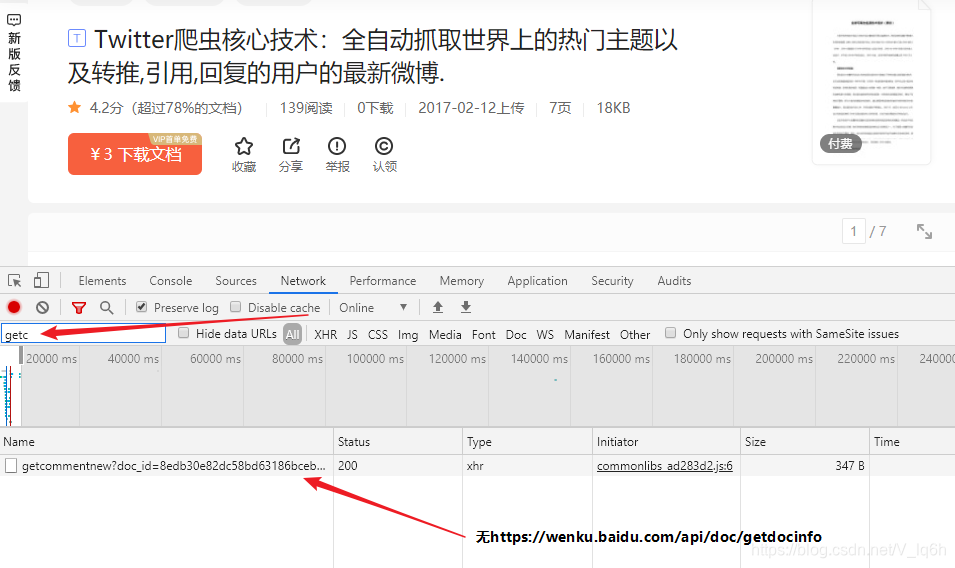
所需要的参数都在源网页中:
- md5sum: bb3ae60282c367a61adf49c6a72bdbab
- sign: 885b0be3b9
- callback: cb
- pn: 1
- rn: 3
- type: txt
- rsign: p_3-r_0-s_c8b7a
- _: 1587970284175
Image("./Images/txt_7.png",width="600px",height="400px")

参数获取方式与前面类似:
title=re.findall(r'<title>(.*?). ',content)[0]
md5sum=re.findall('"md5sum":"(.*?)",',content)[0]
rsign=re.findall('"rsign":"(.*?)"',content)[0]
pn=re.findall('"show_page":"(.*?)"',content)[0]
content_url='https://wkretype.bdimg.com/retype/text/'+doc_id+'?rn='+pn+'&type=txt'+md5sum+'&rsign='+rsign
content=json.loads(session.get(content_url).content.decode('utf-8'))
2.完整代码
import requests
import json
import re
import os
session=requests.session()
path="F:\\桌面\\Files"
if not os.path.exists(path):
os.mkdir(path)
def parse_txt1(code,doc_id):
content_url='https://wenku.baidu.com/api/doc/getdocinfo?callback=cb&doc_id='+doc_id
content=session.get(content_url).content.decode(code)
md5sum=re.findall('"md5sum":"(.*?)",',content)[0]
rsign=re.findall('"rsign":"(.*?)"',content)[0]
pn=re.findall('"totalPageNum":"(.*?)"',content)[0]
content_url='https://wkretype.bdimg.com/retype/text/'+doc_id+'?rn='+pn+'&type=txt'+md5sum+'&rsign='+rsign
content=json.loads(session.get(content_url).content.decode('gbk'))
result=''
for item in content:
for i in item['parags']:
result+=i['c']
return result
def parse_txt2(content,code,doc_id):
md5sum=re.findall('"md5sum":"(.*?)",',content)[0]
rsign=re.findall('"rsign":"(.*?)"',content)[0]
pn=re.findall('"show_page":"(.*?)"',content)[0]
content_url='https://wkretype.bdimg.com/retype/text/'+doc_id+'?rn='+pn+'&type=txt'+md5sum+'&rsign='+rsign
content=json.loads(session.get(content_url).content.decode('utf-8'))
result=''
for item in content:
for i in item['parags']:
result+=i['c']
return result
def save_file(title,filename,content):
with open(filename,'w',encoding='utf-8') as f:
f.write(content)
print("文件"+title+"保存成功")
f.close()
def main():
print("欢迎来到百度文库文件下载:")
print("-----------------------\r\n")
while True:
try:
print("1.doc \n 2.txt \n 3.ppt \n 4.xls\n 5.ppt\n")
types=input("请输入需要下载文件的格式(0退出):")
if types=="0":
break
if types!='txt':
print("抱歉功能尚未开发")
continue
url=input("请输入下载的文库URL地址:")
# 网页内容
response=session.get(url)
code=re.findall('charset=(.*?)"',response.text)[0]
if code.lower()!='utf-8':
code='gbk'
content=response.content.decode(code)
# 文件id
doc_id=re.findall('view/(.*?).html',url)[0]
# 文件类型
#types=re.findall(r"docType.*?:.*?'(.*?)'",content)[0]
# 文件主题
#title=re.findall(r"title.*?:.*?'(.*?)'",content)[0]
if types=='txt':
md5sum=re.findall('"md5sum":"(.*?)",',content)
if md5sum!=[]:
result=parse_txt2(content,code,doc_id)
title=re.findall(r'<title>(.*?). ',content)[0]
#filename=os.getcwd()+"\\Files\\"+title+'.txt'
filename=path+"\\"+title+".txt"
save_file(title,filename,result)
else:
result=parse_txt1(code,doc_id)
title=re.findall(r"title.*?:.*?'(.*?)'",content)[0]
#filename=os.getcwd()+"\\Files\\"+title+'.txt'
filename=path+"\\"+title+".txt"
save_file(title,filename,result)
except Exception as e:
print(e)
if __name__=='__main__':
main()
欢迎来到百度文库文件下载:
-----------------------
1.doc
2.txt
3.ppt
4.xls
5.ppt
1.doc
2.txt
3.ppt
4.xls
5.ppt
请输入需要下载文件的格式(0退出):
txt
请输入下载的文库URL地址: https://wenku.baidu.com/view/147d495158eef8c75fbfc77da26925c52cc5913d.html?fr=search
文件最新IT书籍列表保存成功
1.doc
2.txt
3.ppt
4.xls
5.ppt
请输入需要下载文件的格式(0退出):
txt
请输入下载的文库URL地址: https://wenku.baidu.com/view/9a41886f26d3240c844769eae009581b6bd9bd6e.html?fr=search
文件一个循环网络爬虫保存成功
1.doc
2.txt
3.ppt
4.xls
5.ppt
请输入需要下载文件的格式(0退出):
txt
请输入下载的文库URL地址: https://wenku.baidu.com/view/8edb30e82dc58bd63186bceb19e8b8f67c1cef8e.html?fr=search
文件Twitter爬虫核心技术:全自动抓取世界上的热门主题以及转推,引用,回复的用户的最新微博保存成功
1.doc
2.txt
3.ppt
4.xls
5.ppt
请输入需要下载文件的格式(0退出):
txt
请输入下载的文库URL地址: https://wenku.baidu.com/view/df7ffa19b7360b4c2e3f6495.html?fr=search
文件爬虫技术介绍保存成功
1.doc
2.txt
3.ppt
4.xls
5.ppt
请输入需要下载文件的格式(0退出):
0
Image("./Images/txt_8.png",width="600px",height="400px")
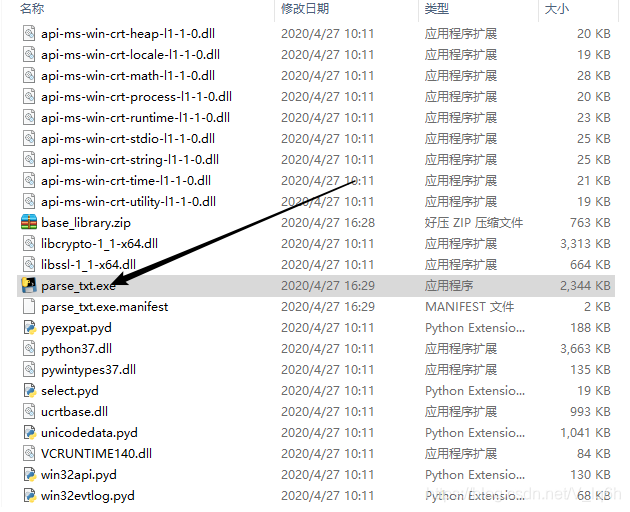
3.使用pyinstaller打包
pyinstaller parse_txt.py
from IPython.display import Image
Image("./Images/txt_9.png",width="600px",height="400px")
4.运行效果
文件存储路径:F:\桌面\Files
Image("./Images/parse_txt.gif",width="600px",height="400px")
Image("./Images/txt_10.png",width="600px",height="400px")

5.完整代码
Github链接:https://github.com/LQ6H/Python_spider
百度网盘链接:
链接:[https://pan.baidu.com/s/1kdtu0oVIJprocl5FwPatOw]
提取码:szxi

 浙公网安备 33010602011771号
浙公网安备 33010602011771号