Attention&Transformer
Attention&Transformer
3blue1brown&豆包
GPT&Transformer
-
$\text{GPT} = \text{Generative} + \text{Pre-trained} + \text{Transformer} $.
-
$ \text{Embedding} \rightarrow (\text{Attention} \rightarrow \text{MLP})_{repeat} \rightarrow \text{Unembedding}$
-
token -> vector/tensor(embedding) -Attention> update Value (fashion model or ML model) -MLP> problem update vector
-
Attention -> MLP(升维+降维) repeat 作用有
- 提炼特征,即浅层捕获局部模式,深层捕获全局语义;
- 通过非线性变换及信息交互,增强表达能力;
- 构建层次化理解,即词->短语->句子->篇章....
-
Attention+MLP的详解:
- 升维:拓展语义表达空间,用高维神经元捕捉特定语义特征;
- 激活函数:引入语义非线性,抑制噪音,增强特征;
- 降维:语义压缩与整合,将分散语义压缩并整合,保留最核心的语义关系,变成了更抽象的语义表达;
- Attention:在token间建立联系,动态聚合,形成上下文感知表示;并将MLP提取的局部语义与全局上下文相结合,对语义进行修正(语义增强+语义校准)。
-
Transformer的每一层都在前一层的基础上进行更复杂的语义处理,从浅层捕获局部语法和基础语义到中层构建实体关系和简单推理,再到深层处理复杂语义和篇章级推理,形成了特征提取->上下文关联->更高级特征提取->更高级上下文关联的循环,深化模型对语言的理解。
-
从数学角度看,这种结构等价于在函数空间中进行层次化的近似:
- MLP:在局部空间中拟合复杂的非线性函数;
- Attention:在全局空间中建立不同局部函数之间的联系;
- 交替堆叠:逐步逼近真实的语言生成概率分布。
-
Transfomer核心架构即Transformer Block,即Self-Attention+MLP。
-
可以得知embedding嵌入词向量时,某个维度方向将代表的某种语义联系。例如cats-cat的方向就接近于复数向量方向,woman-man就接近于女性化身份向量方向;同时点积的大小即可以表示两个向量之间的关联程度。
-
Prompt作为初始上下文存在,而用户的第一个问题则是作为第一段对话存在。
-
GPT中Attention网络数据流量则为上下文长度。
-
unembedding得到的输出结果是logits,即softmax函数的输入,probablity则是输出;常见的Temperature其实是softmax的参数,即\(\frac{e^{x/T}}{\sum_{n=0}^{N-1} e^{x/T}}\)中的参数\(T\)。
Transformer&Attention
-
核心思想:Query-Key-Value三元组,Qurey是理解对象(需要什么信息?),Key是候选关联对象(提供什么信息?),Value是关联具体信息(语义/提供的具体信息内容)。
-
注意力计算过程:Q、K相似度计算->权重归一化->Value加权求和;
-
注意力计算公式SDPA:
\[\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V \]公式解释:先计算Query与Key相似度(关联度),将结果缩放使数值稳定,接下来用softmax归一化,将相似度转成概率权重,最后对权重矩阵和Value相乘,得到输出。每个Query位置融合了Key-Value的信息。
-
Q与K的相似度计算结果依赖于其本身带有语义的嵌入向量的语义,Attention的作用只不过实在其本身语义基础上进行微调理解,嵌入质量决定了QK的语义底子,例如BERT的预训练词嵌入、ViT的图像Patch嵌入才能精确的编码上下文语义,而普通的Word2Vec仅仅是普通的降维,并没有保留其深层语义;嵌入直接定义了输入的基础语义表示,是 Q/K 的根本材料。
-
注意力的Query因注意力机制不同而不同,自注意力的Query来自于其本身;交叉注意力的Query来自于另一个序列,例如翻译模型的Query会指向源语言;多头注意力则是将Query分为多个子空间,每个注意力头处理Query的不同部分;在检索和记忆模块中,Query则是预定义固定的。
-
注意力在计算的时候要做到后面的此不影响前面的词,即QK矩阵的主对角线Key侧的值在softmax之前应赋值为\(-\infty\)(因果掩码);其本质是因果性约束的要求,即保证预测的合理性和训练的一致性。
-
在Transformer等场景多次堆叠注意力时,会引入残差连接保证底层的具体信息不会被高层抽象完全覆盖,避免丢失细节。
-
注意力权重矩阵的大小为上下文长度的平方;注意力模式即QK点积得到的相似度矩阵,其经过缩放与softmax处理则成为注意力权重矩阵。
-
Q、K、V矩阵是由输入特征矩阵X与相应的可学习参数矩阵点积得,而并非参数矩阵。
-
V矩阵升维*降维在数学上等效于一个V参数矩阵,但在实际计算中,二者并不等效,因为是降维->加权->升维代替V参数矩阵。
-
注意力更新的嵌入表示是V与注意力模式点积得到的向量,即$ Attention(Q,K,V) $;gpt中的注意力参数矩阵等更新是通过自监督更新的,即用下一个词更新上一个词。
-
一句话解释注意力机制:通过不断对自己提问 “该关注谁的信息”,倾听每个对象的回应以衡量关联,再把这些回应按重要性整合,最终重新理解自己在整体中的位置与含义。
-
单头注意力是在单一特征空间中建模联系,而多头注意力则是在多子空间中并行建模;单头注意力难以同时建模不同类型的关联,受限与单一空间的信息瓶颈。
-
Q、K、V 参数矩阵的学习过程是一个通过梯度引导的自组织分化过程。尽管所有参数最初都是随机初始化的,但通过反向传播的误差信号反馈,它们会自动演化出明确的分工。
-
单头注意力流程图:
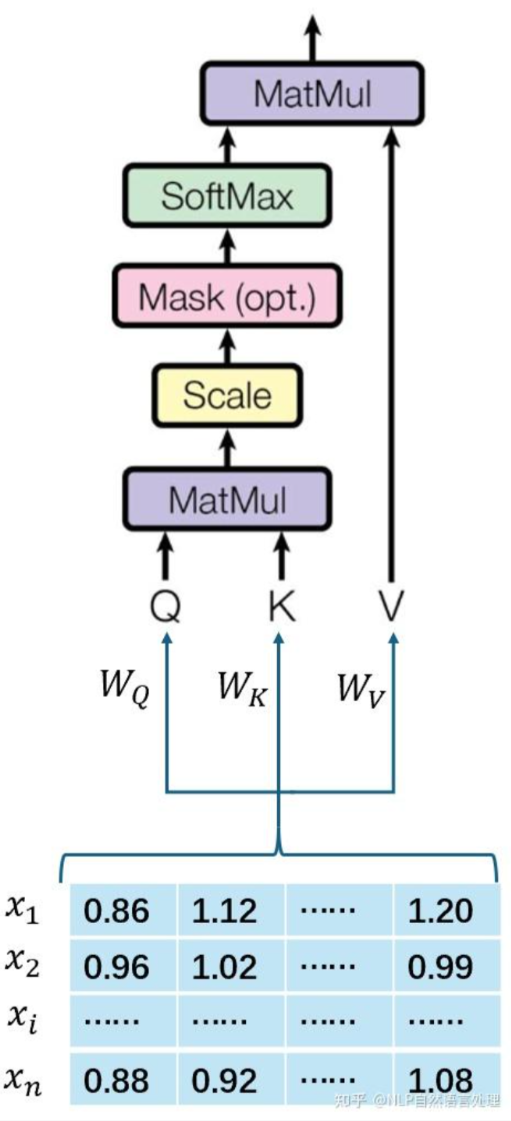
-
QKV参数矩阵之所以能学到自己的角色是因为前向运算不同,可参考上图,之所QK能区分自己的角色,是因为有\(\frac{\partial \text{loss}}{\partial Q} = K \cdot \text{权重梯度}\);Q和K随着训练会被驱动分化并且互补强化,并会让QK分别落在需求子空间和标识子空间中去,所以角色区分是注意力机制高效工作的必然结果:运算逻辑要求分工,梯度推动分工,训练强化分工。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号